Invented by Galvin; Brian
Welcome! Today, we’re going to break down a complex patent about a new kind of deep learning model called the Modality-Agnostic Large Codeword Model (LCM). This model helps computers learn from different types of data—like text, images, sounds, and videos—all at once. Let’s explore what makes this invention special, why it matters, and how it builds on the science and technology that came before it.
Background and Market Context
Let’s start by looking at why this invention matters and what problems it tries to solve in the world of artificial intelligence (AI) and machine learning.
AI is everywhere now, from the phone in your hand to the laptop on your desk. Most AI models today do very well with one type of data, like text or images. If you talk to a voice assistant, it’s great at understanding your words. If you use a photo app, it can find faces or objects in pictures. But what if you want a computer to understand both your words and the pictures you show? Or maybe even a video with sound and text? That’s where things get tricky.
Most of today’s best AI models, like the famous GPT or BERT, work by breaking text into “tokens” (think: words or pieces of words). Each token is turned into a number-filled vector—a way for the computer to understand meaning. But this approach has a few problems. First, it can be slow and needs a lot of computer power. Second, it only works well with one type of data at a time. If you want to use text and images together, you usually need to build two separate models and try to make them talk to each other. That’s hard, slow, and often doesn’t work as well as we’d like.
There’s a growing demand for smarter AI that can understand many types of data at once—what we call “multimodal” AI. Think of a robot that can read a sign, listen to instructions, and recognize a face—all at the same time. Or imagine a search engine that lets you search using both your voice and a photo. The market for these kinds of smart tools is huge and growing fast, especially as devices get more powerful and people expect more from technology.
But making AI that can handle all these data types together is tough. Current systems often use “dense embeddings”—big blocks of numbers representing bits of data. These are heavy, use lots of memory, and are often hard to understand (even for the people who build them!). Plus, they usually don’t work well if you try to move them from one task (like language) to another (like images). That limits their usefulness.
The Large Codeword Model (LCM) aims to change all of this. It promises a smarter way to represent data—using small, compressed “codewords”—and a new model that can natively handle text, images, audio, and more. The goal is to make AI that’s faster, lighter, and much better at understanding and connecting different types of data. This is a big deal in a world where businesses and users want AI that can multitask and adapt quickly.
In short, the LCM is built to help AI systems become more flexible, efficient, and able to work across many different data types—something the world really needs as technology keeps moving forward.
Scientific Rationale and Prior Art
Now, let’s look at the science behind the LCM and how it builds on or improves past inventions.
For many years, the main idea in AI models—especially those that process language—was to turn words into “tokens” and then into “dense embeddings.” These are just fancy names for ways to change words into numbers, so computers can work with them. Transformers (the model behind GPT and BERT) were a huge step forward. They use attention mechanisms, which let the model figure out which words matter most in a sentence. This was a big improvement over older models that just read text from left to right, like RNNs (Recurrent Neural Networks).
But there are still problems. Tokenization (breaking data into tokens) can be clumsy. Sometimes a word gets split in a way that loses meaning. Dense embeddings take up lots of space and are hard to move from one task to another. And, most importantly, these systems are usually locked to one kind of data—mostly text.
In the world of images, models like CNNs (Convolutional Neural Networks) are used. Audio uses models like RNNs or variants like LSTMs. Video is even harder, often needing a mix of both. If you want to make a model that can do more than one thing, you usually build separate models for each type of data and try to “fuse” their results. But this is complicated and doesn’t work very well.
Some new models, called “multimodal” models, try to bring together text, images, and audio. But most of them still use dense embeddings for each type of data and then try to glue them together. This makes the models big, slow, and hard to train. They also don’t “share knowledge” well—what the model learns from text doesn’t always help with images, and vice versa.
Another idea from the past is data compression, like Huffman coding or arithmetic coding. These methods turn bits of data into shorter codes, saving space. But they weren’t really used in deep learning models—until now.
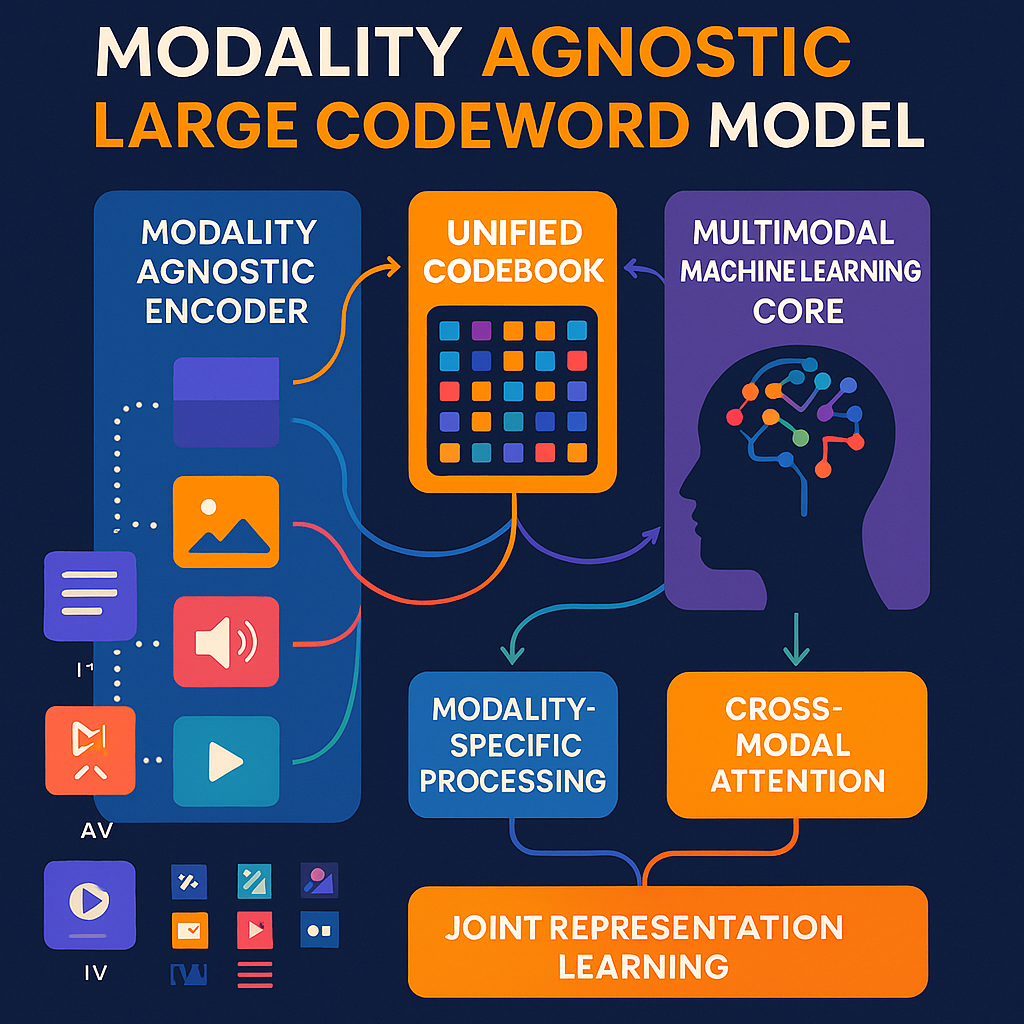
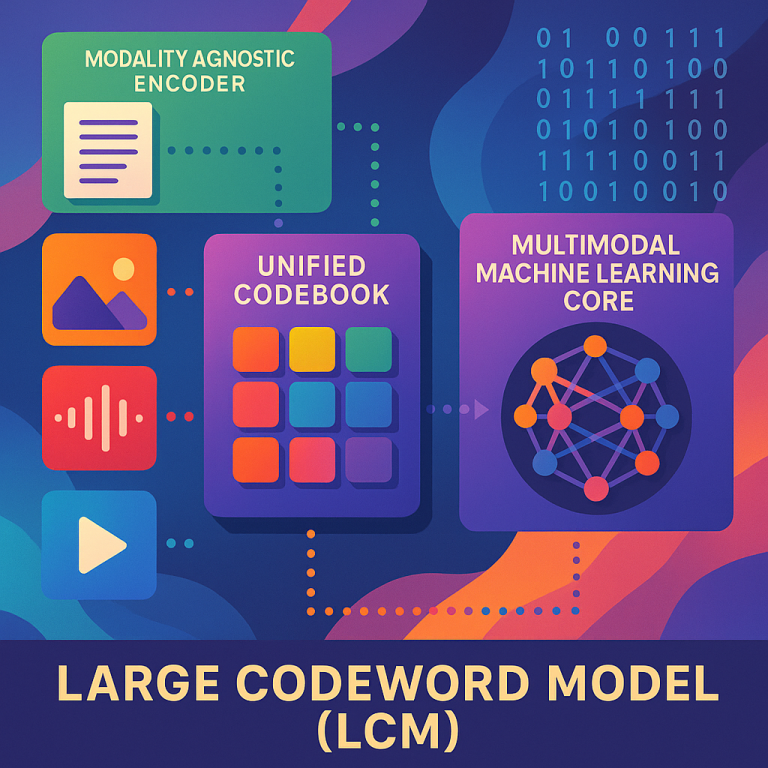
This is where the LCM stands out. It borrows the idea of “codewords” from data compression. Instead of turning every word or image patch into a big vector, it uses a compact codeword—a small, unique bit of information representing a meaningful chunk of data. These codewords are not just for text, but for any kind of data (images, audio, video, etc.). The LCM’s codewords are designed to work across all modalities, using a shared “codebook.”
The LCM also introduces the idea of “modality-agnostic” encoding. That means it doesn’t care what kind of data you give it—text, photo, sound—it can turn it all into the same kind of codeword before the main processing. This is different from legacy models, which usually need a separate path for each data type.
By clustering codewords before embedding, the LCM reduces the number of things it needs to remember. It learns to focus on groups of similar data, making the system more efficient and easier to interpret. This helps with transfer learning—knowledge gained from one type of data can be used to help with another, making the model more flexible and generalizable.
So, while LCM builds on ideas like tokenization, embeddings, transformers, autoencoders, and data compression, it changes the game by combining these concepts in new ways. It uses codewords to make data processing lighter, smarter, and more adaptable. The LCM is not just an improvement; it’s a fresh approach that could help AI models finally understand and use all kinds of data together.
Invention Description and Key Innovations
Let’s break down exactly how the Modality-Agnostic Large Codeword Model (LCM) works and what makes it so innovative.
The LCM is a system and method that allows computers to learn from and generate responses using any type of data. Here’s how it works, step by step, in simple terms:
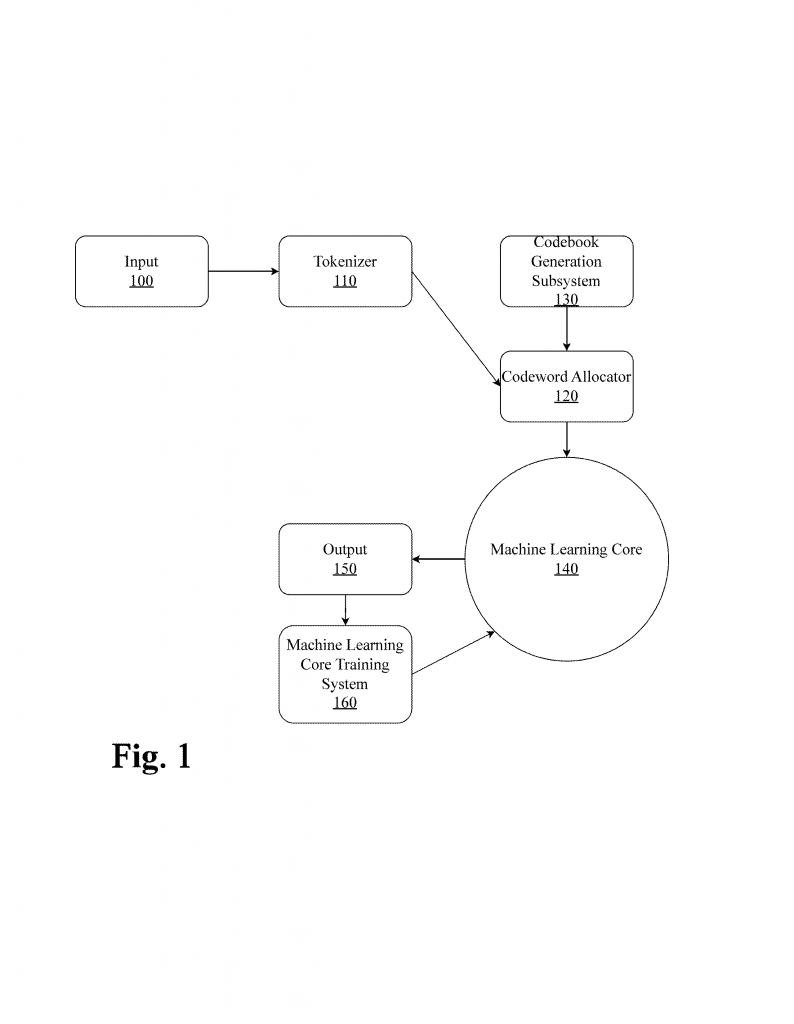
1. Receiving Inputs: The system takes in lots of different data types at once. This could be words (text), pictures (images), sounds (audio), or even video. You can give it any mix of these, and it’s ready to handle them all.
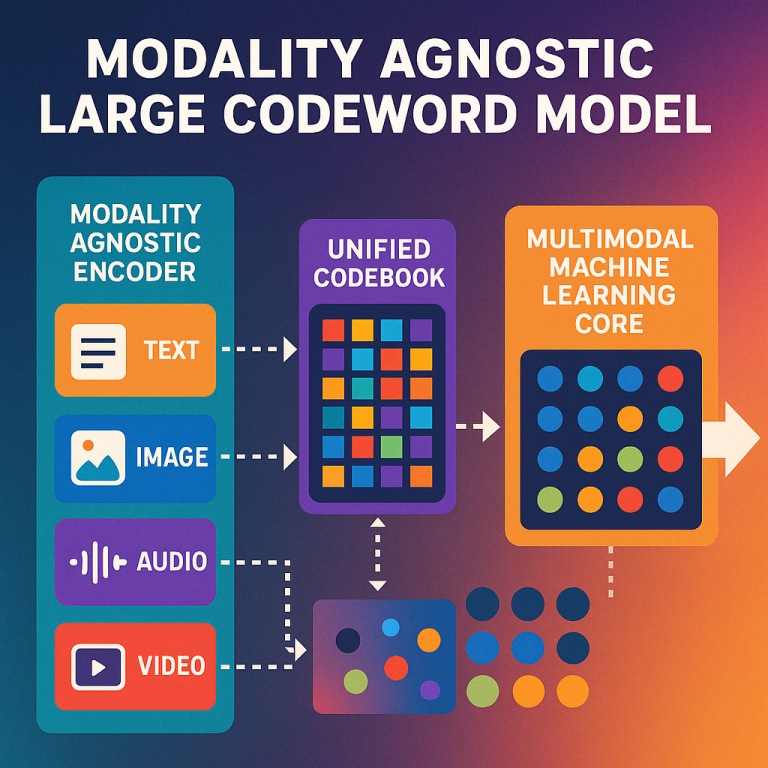
2. Modality-Agnostic Encoding: Before breaking down the data, the LCM uses a “modality-agnostic encoder.” This is a special piece that doesn’t care what kind of data it gets. It turns everything—words, pixels, audio waves—into a unified representation. This step is key because it means the system doesn’t have to keep separate rules for each data type.
3. Tokenization into Sourceblocks: Next, the encoder’s output is split into “sourceblocks.” Think of these as meaningful chunks—like a word, a part of a picture, or a bit of sound. The system uses smart rules to find the best way to split the data, using methods like Huffman coding (which looks at how common each chunk is and assigns shorter codes to the common ones).
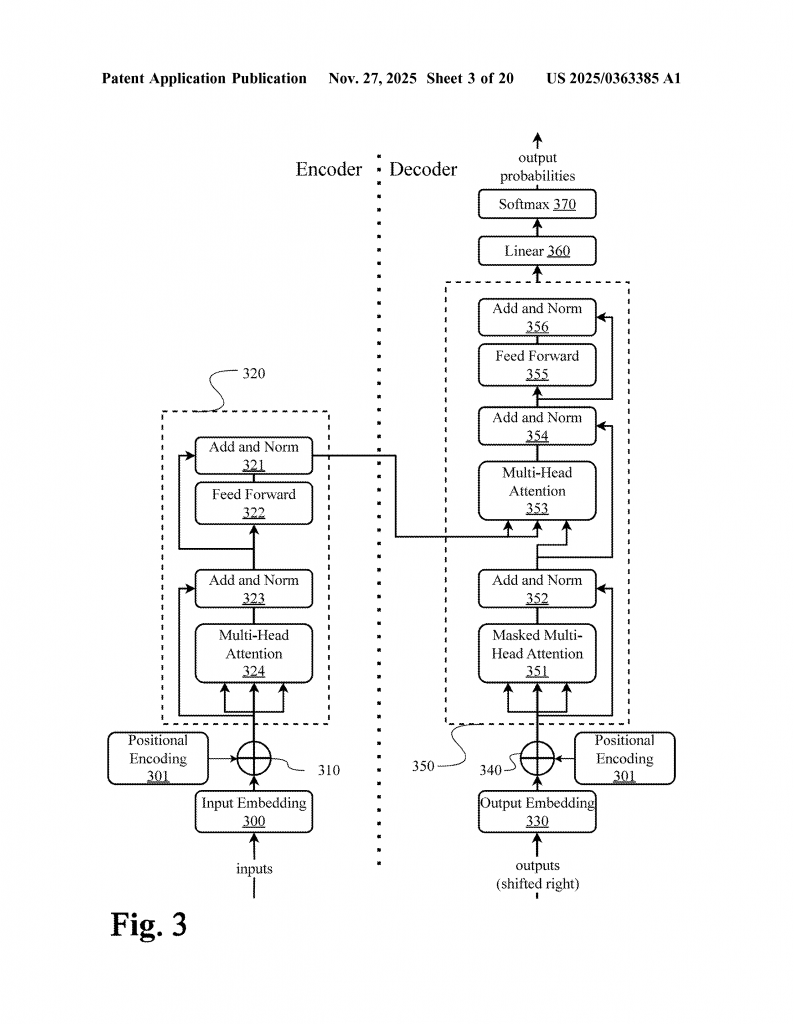
4. Assigning Codewords: Each sourceblock gets a unique codeword from a big dictionary called a “codebook.” This codebook is shared across all types of data, not just one. If “cat” in text and a picture of a cat both appear, they can be assigned similar or related codewords, making it easier for the system to connect them.
5. Clustering Codewords: Before the main learning happens, the codewords are clustered together. This means similar codewords are grouped, making the model’s job easier. Instead of learning about every single codeword, the model can focus on groups, saving memory and speeding up learning. This also helps the model understand connections between data types—for example, linking the word “dog” with a bark sound and a dog photo.
6. Processing in the Machine Learning Core: The heart of the LCM is its “multimodal machine learning core.” This can be a transformer (like GPT), a variational autoencoder, or even a recurrent neural network. The core uses an embedding layer (which turns codewords into numbers the computer can work with) and a cross-modal attention mechanism (which helps the system decide what parts of which data type to focus on at each step).
7. Codeword Response and Translation: Once the model processes the input, it generates a codeword response. This is a compressed answer, still in codewords, that can then be turned back into text, an image, sound, video, or any mix—matching the types of input it got. For example, if you give it a picture and some text, you can get back a mix of both as a response.
8. Training for Multimodal Learning: The LCM is trained on big sets of data that include all the different types. It learns to understand and connect them, using joint representations and cross-modal attention. It can even do “transfer learning,” using what it learned from one data type to help with another. This is a powerful way to make the model smarter and more general—able to handle tasks it was never directly trained for.
9. Output Generation and Adaptability: The model has a smart output controller. This part decides what kind of output to create (text, image, audio, video, etc.) based on the task and the data it received. The system is flexible and can be expanded to new data types as needed.
10. Continuous Improvement: The system is always learning. It uses a training subsystem that can handle multiple data types at once, adjust how it learns based on new data or tasks, and keep improving over time. It can even adapt to new tasks or data types by updating its codebook and training routines.
Key Innovations:
– The use of a modality-agnostic encoder to convert any data into a shared format.
– The creation of compact, discrete codewords that work for all types of data.
– Clustering codewords before embedding, making the system faster and easier to train.
– A unified codebook that connects different data types, helping with transfer learning and cross-modal understanding.
– A flexible machine learning core that can use different architectures (transformers, autoencoders, RNNs) as needed.
– Cross-modal attention, helping the system relate different types of data in smart ways.
– Adaptable outputs, letting the system respond in any data type or combination.
– Continuous, multimodal training, making the system smarter and more general over time.
In simple words, the LCM is like a smart, flexible brain for computers. It can take in any kind of data, turn it into a compact, shared language (codewords), and learn to understand and connect all the pieces. This makes it much more powerful, efficient, and adaptable than traditional models that only work with one kind of data at a time.
Conclusion
The Modality-Agnostic Large Codeword Model (LCM) is a big step forward for artificial intelligence. It brings together ideas from data compression, machine learning, and model architecture to build a system that can learn from and respond to all kinds of data—text, images, audio, and video—in a unified way. By using codewords and a shared codebook, the LCM is faster, lighter, and smarter than older models. It makes AI more flexible, more general, and more useful for the real world, where data comes in many shapes and forms. As AI continues to grow and touch every part of our lives, inventions like the LCM will help make technology smarter, more efficient, and more adaptable to our needs.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363385.