Invented by Cruanes; Thierry, Cseri; Istvan, Dageville; Benoit, lyer; Ganeshan Ramachandran, Muralidhar; Subramanian, Ramachandran; Raghav

Today, let’s talk about a new way computers can handle lots of jobs at once by using something called a “processing pipeline.” This is based on a recent patent application for a system that makes it easier and faster to process many tasks with less waiting and wasted computer power. We’ll look at why this matters, how it builds on old ideas, and what makes this invention special. We’ll keep things simple and easy to follow.
Background and Market Context
In our digital world, data is everywhere. Companies, schools, doctors, and even games rely on databases to store and manage all sorts of information. Think about your favorite app or website. Every time you log in, search for something, or upload a picture, data gets stored in a database. This data needs to be safe, easy to find, and quick to update.
Years ago, databases were small and simple. Now, they are huge. Some companies have so much information that it fills up entire buildings with computer servers. This data isn’t just text; it’s also pictures, videos, reports, and more. All these different types of files make storage and processing even harder.
But it’s not just about storing data. It’s about using it. Every time someone wants to look up a record, change something, or run a report, the database must do “workloads.” A workload is just a job the computer must finish. Here’s the problem: When lots of people or apps ask for work at the same time, things can slow down. Some jobs wait in line, while others get stuck because the computer doesn’t know the best way to use its time and memory.
This is especially tough for companies that use “cloud” systems. The cloud means renting computer power over the internet, instead of buying your own servers. Cloud services, like those from Amazon, Microsoft, or Google, let people run huge databases and only pay for what they use. But even in the cloud, it’s hard to make sure every job gets done quickly, without wasting money on unused computer power.
Today’s big challenge is making sure all these workloads get processed quickly, with little waiting, and without spending more than needed. This can be even harder when the files are not just numbers and words, but also pictures, videos, or complicated scientific data. If the system is not smart, it can end up wasting computer time, costing more money, and making users wait longer for results.
Because of this, there is a strong need for better ways to handle many tasks at once. The goal is to make systems that are fast, save money, and can grow as needed. This is where the new patent comes in. It tries to solve these problems with a new method for processing jobs in databases, especially in cloud systems.
Scientific Rationale and Prior Art
To really understand this patent, let’s talk about how things worked before and why new ideas were needed.
In the old days, when a database got a job, it would just do it right away if it could. If too many jobs came in, some would have to wait. The system would often split big jobs into smaller tasks and assign them to “nodes.” A node is just a small computer or a part of a big computer that can work on its own. Each node has some memory (to store data) and a processor (to do the work). Modern systems might have hundreds or thousands of these nodes.
But even with many nodes, problems can happen. Sometimes, nodes are busy while others are not. Sometimes, a job needs more memory than a node has. Worse, if something goes wrong, jobs might get stuck or lost. This is called “inefficient workload distribution.” It means the system isn’t using its resources in the best way.
Many companies have tried to fix these issues. They made “pipelines” to process data in steps. Imagine an assembly line, where each worker does one part of the job. Each step in the pipeline does a little bit of work, passing the result to the next step. Pipelines can be very good at handling lots of data, especially if each step can run on its own node. This idea is not new—in fact, it’s how many modern data systems work.
Some systems also use “queues.” A queue is a line where jobs wait their turn. When a node is ready, it takes the next job from the queue. This is helpful, but it doesn’t solve all problems. If the system doesn’t know how big or hard each job is, or how long each step will take, jobs can still get stuck. And if the pipeline isn’t flexible, it might not work well with new types of files or workloads.
There are also “compute resource managers.” These are programs that decide which node should do each job, trying to balance the load. They look at things like which nodes have free memory, which are busy, and so on. This helps, but it still isn’t perfect, especially in the cloud where resources can change quickly.
Another challenge is the variety of file types. Databases now store not just text and numbers, but also images, videos, scientific files, and more. Some files are “unstructured,” like pictures. Others are “semi-structured,” like JSON files, which are used to store data in a way computers can read. Some are “structured,” like spreadsheets or scientific data files. Each type needs different processing steps. Old systems often needed lots of custom code to handle new file types, which was slow and expensive.
Finally, there’s the issue of “continuous processing.” In many cases, new data arrives all the time, not just once. Think of a security camera sending new video every minute, or a weather sensor updating every second. The system needs to keep up, processing each new piece of data right away. Many old systems were built for “batch” processing—doing lots of jobs at once, but only every so often. They struggle to keep up with a constant stream of new work.
So, to sum up: Old systems had problems with slowdowns, wasted resources, and trouble handling new types of files and constant streams of jobs. The market wants solutions that are fast, flexible, and can handle all kinds of workloads, all the time.
Invention Description and Key Innovations
This patent introduces a new way to make file processing smarter and more flexible, especially for big databases in the cloud. Let’s break it down into simple parts and see what’s new.
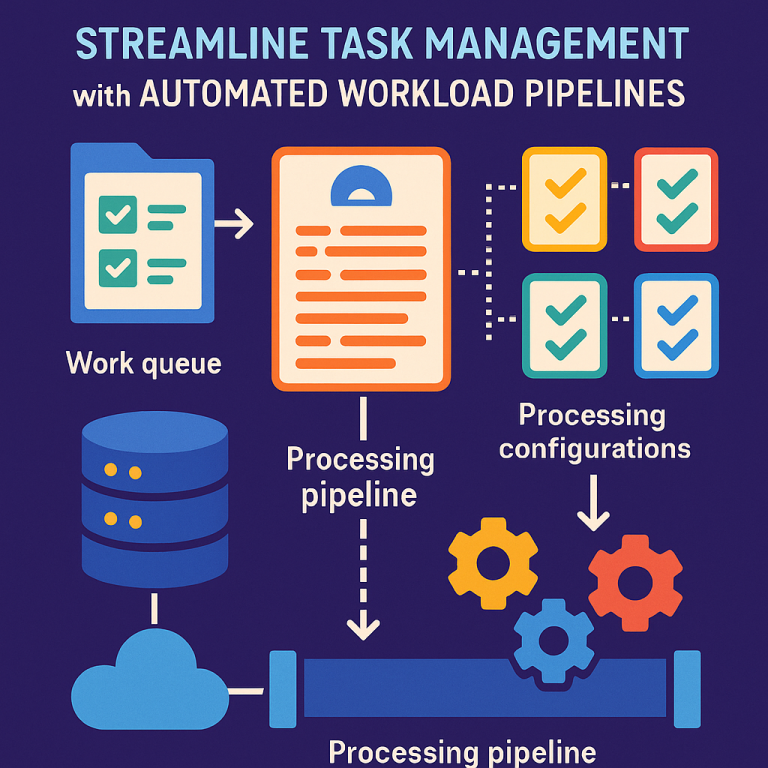
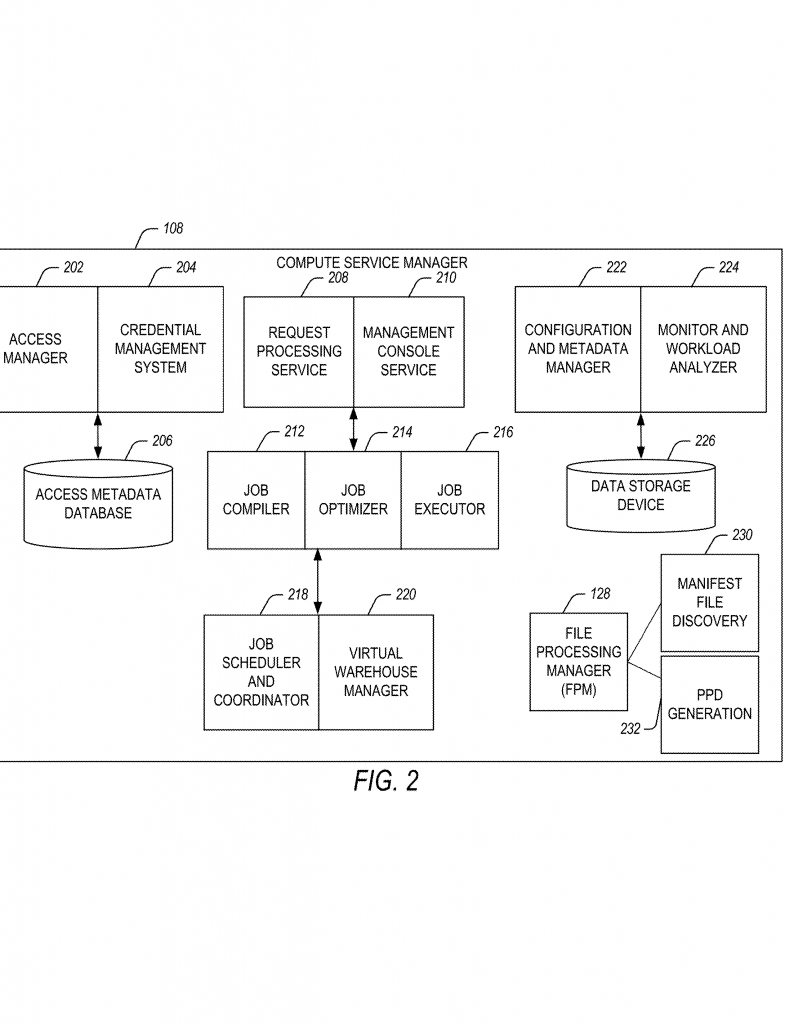
The heart of the invention is something called a “Processing Pipeline Definition” or PPD. Think of the PPD as a recipe for how to handle a set of jobs. Each job might be about processing a certain file, running a report, or updating some data. The PPD lists all the steps needed for each kind of job, and how to schedule them so everything runs smoothly.
The system works like this:
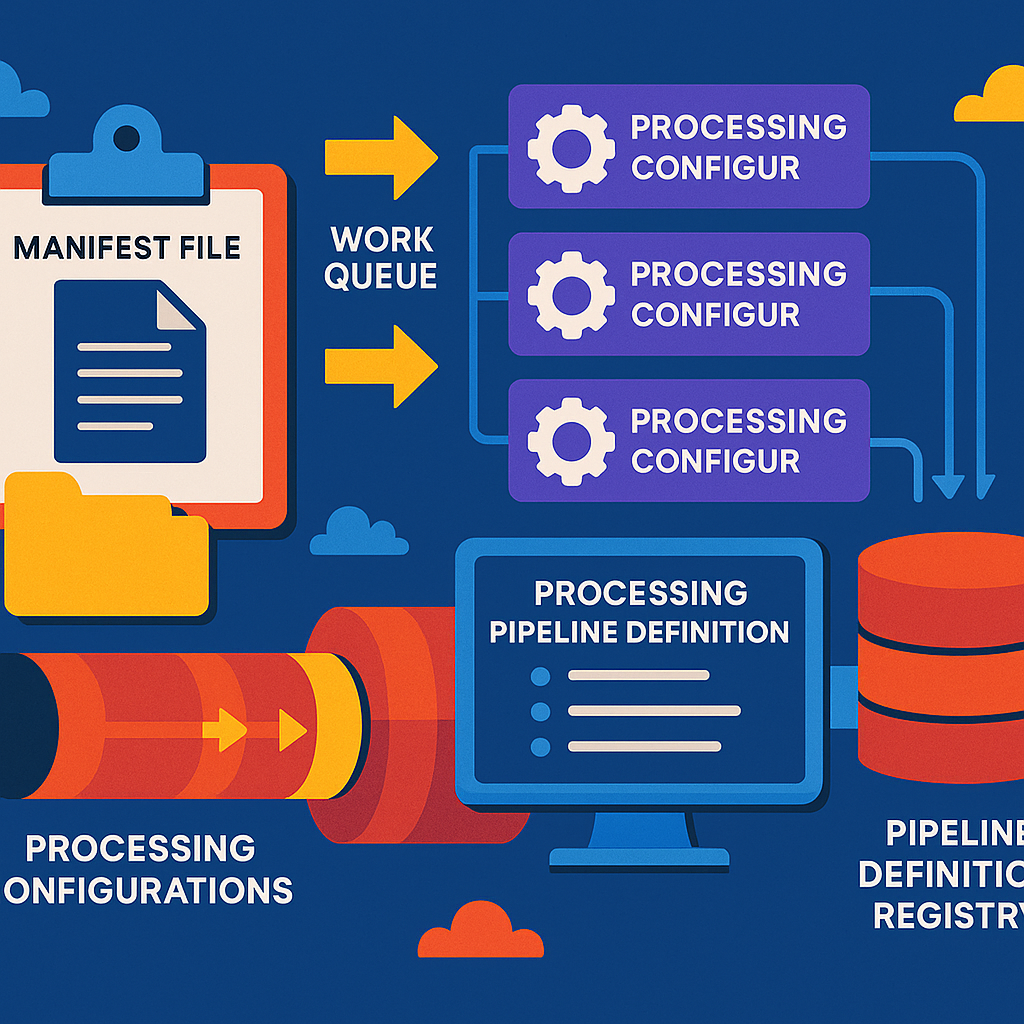
First, a “manifest file” is created. A manifest is just a list that describes many jobs waiting to be done. It holds “metadata”—that’s information about each job, like what kind of file it is, where to find it, and what steps are needed. This manifest gets put into a “work queue,” which is just a list of jobs waiting to be processed.
Next, the system reads the manifest file from the queue. For each job in the manifest, the system creates a “processing configuration.” This is like a set of instructions for how to handle that specific job. Each configuration says what steps to take, how to schedule them, and what computer resources (like memory and processor time) are needed.
Then, all these processing configurations are grouped into the PPD. The PPD is a blueprint that tells the system how to process each job, in what order, and with what resources. The PPD can handle many workloads at once, and it’s flexible enough to work with all kinds of files and tasks.
But here’s what makes it really special: The PPD is registered in a “pipeline definition registry.” This registry is like a library where all the recipes for different types of jobs are stored. When a new job comes in, the system can quickly grab the right PPD from the registry, instead of building a new one from scratch. This saves time and makes it easy to add new types of jobs in the future.
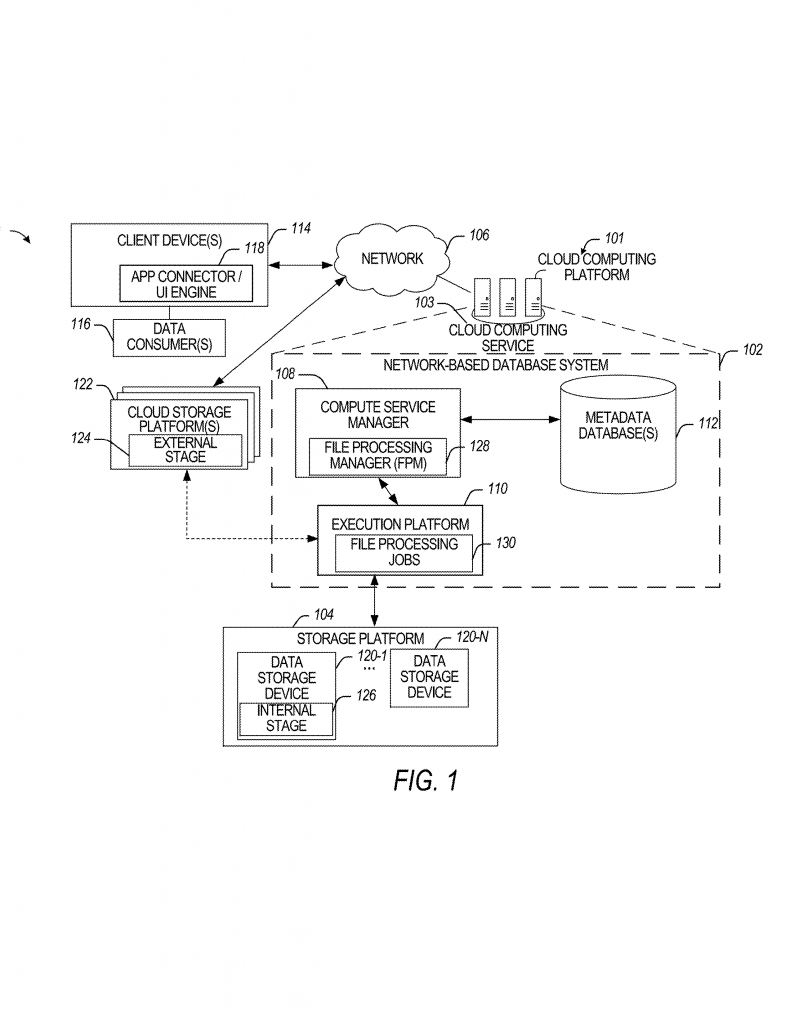
The system also splits up the work in a smart way. Some steps are handled by a “compute service manager.” This is a smart program that makes high-level decisions, like which jobs to start first and how to set up the pipeline. Other steps are handled by the “execution platform,” which is made up of nodes that actually do the work. The system can give different jobs to different nodes, and even adjust which node does what based on how busy everything is.
Another important part is the “source monitor function.” This is like a watchman who keeps an eye on where the data comes from. If a table or file is updated, the monitor notices and tells the system to update the manifest file and start new jobs. This keeps everything up to date without anyone needing to check by hand. It also allows the system to process new data as soon as it arrives, which is perfect for things like live video, sensor data, or anything that changes often.
The PPD also lets you set up different kinds of pipelines for different types of files or jobs. For example, there might be one pipeline for processing video files, another for scientific data, and another for text reports. Each pipeline type can have its own recipe, stored in the registry. When a new job comes in, the system picks the right recipe and starts working right away.
And because everything is managed by the PPD and registry, it’s easy to add support for new file types or new kinds of jobs. You just create a new PPD, register it, and the system can start using it right away. This saves time and makes the system much more flexible than older methods.
Some more key points that make this invention stand out:
- Automatic resource assignment: The system figures out how many computer resources are needed for each job and assigns them as needed. If the job is big, it gets more power; if it’s small, it uses less. This saves money and avoids wasted resources.
- Fault tolerance: If a node fails, another node can take over. Because the system keeps track of progress, jobs aren’t lost.
- Scalability: The system can handle more and more jobs as needed. It can add or remove nodes, or even whole “virtual warehouses” of nodes, based on how much work there is.
- Support for many file types: The PPD can describe steps for almost any kind of file or job, from simple numbers to complex scientific files or live data streams.
- Continuous processing: The monitor function means the system can keep up with new data as it comes in, not just process a batch and stop.
- Easy updates and customizations: New pipelines can be added or old ones updated without disrupting the whole system.
In short, this system gives big databases a smarter, more flexible way to handle jobs of all types, sizes, and speeds. It keeps everything moving fast, uses resources wisely, and is easy to grow or change as needed.
Conclusion
As data grows and changes, companies and users need better ways to handle more jobs, more types of files, and faster updates. This patent shows a new path forward. By using manifest files, processing pipeline definitions, and a smart registry, systems can keep up with even the busiest workloads. The invention makes it simple to add new kinds of jobs, use computer resources wisely, and keep everything running smoothly, even in the cloud.
For anyone building or running big databases, especially in the cloud, these ideas can help save money, speed up results, and make sure nothing gets left behind. As more data flows in from more places, systems like this will become even more important. If you want to build a system that is fast, flexible, and ready for anything, this new approach is a big step in the right direction.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250362974.