
Invented by Satloff; James

Spatial audio is changing how we listen. From home theaters to virtual reality, it shapes experiences by placing sounds around us, making them feel real. But until now, delivering this effect in open spaces—without headphones—has been hard. The patent application we’re exploring here proposes a new way: using radio waves, like Wi-Fi, to figure out exactly where your ears are, and then sending beams of sound right to them. Let’s break down how this works, why it matters, and what makes it new.
Background and Market Context
Imagine sitting in your living room, watching a movie or playing a game, and hearing every sound as if it’s coming from the right spot—even if you move around. That’s the promise of spatial audio: not just loudness, but direction, depth, and realism. Until recently, this was only possible with headphones or in carefully set-up rooms with many speakers. Even then, the effect would only work if you sat in the “sweet spot.”
The audio industry has been chasing better ways to bring spatial sound to real-world spaces. We’ve seen the rise of soundbars, smart speakers, and even speaker arrays that try to steer sound beams. Virtual reality (VR) and augmented reality (AR) platforms also rely on spatial audio to make digital experiences feel lifelike. But all these systems face the same challenge: they need to know where your ears are. If you move, the illusion falls apart.
Traditional solutions have involved cameras, wearables, or complex calibration steps. Cameras can feel invasive, and wearables are uncomfortable and not always practical. There’s also a growing need for privacy in home and public spaces. Nobody wants their living room monitored by a camera just for better sound.
This is where the technology described in the patent comes in. It uses radio waves—like the ones already bouncing around your home from Wi-Fi networks—to sense people’s location, orientation, and even details like heartbeat and breathing. By doing this, it can work out where your head (and therefore your ears) is, and then adjust the sound in real time. The result? Each person in a room can get a custom audio experience, without needing to wear anything or be filmed.
In a world where we’re surrounded by wireless signals and demand for immersive entertainment is growing, this approach could reshape not just home audio, but meeting rooms, classrooms, theaters, and public spaces. It brings together trends in smart homes, IoT (Internet of Things), and AI-driven personalization. Most importantly, it offers all of this while respecting privacy—no cameras needed.

Scientific Rationale and Prior Art
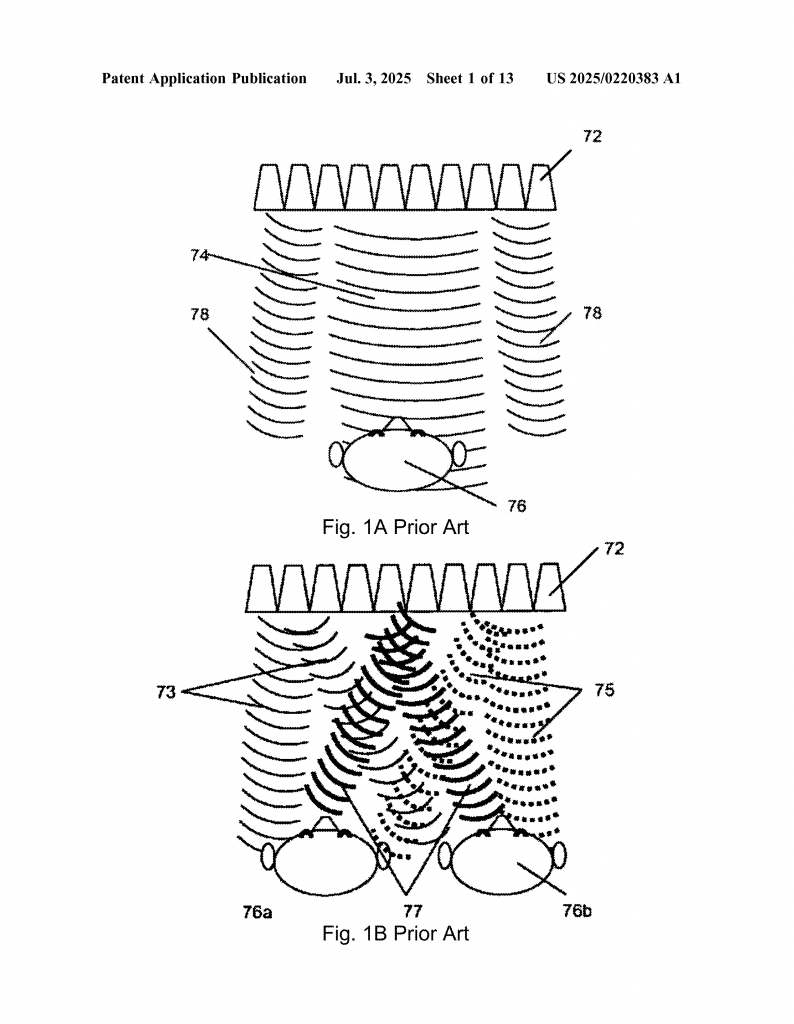
So, how does sound become “spatial”? The answer lies in something called the Head-Related Transfer Function (HRTF). This is a fancy way of describing how each person’s head, ears, and body shape the sound that reaches their eardrums. When sound comes from somewhere in the room, it bounces, bends, and changes in subtle ways. Our brains use these clues to figure out where a sound is coming from.
Classic spatial audio systems use HRTFs to simulate this effect. For headphones, it’s easy: software tweaks the left and right channels to make sound seem like it’s coming from all around. But for open spaces, it’s much harder. You have to deliver just the right sound to each ear, despite echoes, room shape, and the fact that people move around. Getting it wrong can make sound seem flat or even confusing.
Earlier technologies tried different tricks. Some used arrays of speakers to beam sound to a certain spot. Others used microphones, cameras, or wearable trackers to find the listener’s position. There are patents and products that use SLAM (simultaneous localization and mapping) with cameras, radar, or even LIDAR to map the room and people in it. Some tried to calibrate each user’s HRTF by playing test sounds and asking for feedback.
There’s also a long history of using radio frequency (RF) signals—like radar or Wi-Fi—to detect movement, locate people, or even track heartbeats and breathing. These RF-based systems have been used for security, health monitoring, and smart home automation. They work because human bodies reflect and change radio waves in ways that can be measured and interpreted.
However, combining all of this—using RF to locate people and then steering audio based on that data—has been rare. Most prior art focused on either audio or sensing, but not both together in this way. Some more recent research and a handful of patents have touched on using radar or Wi-Fi to detect people for audio purposes, but these often required special hardware, didn’t handle multiple listeners well, or still relied on other sensors like cameras.
What’s clever about the invention in this application is how it brings these ideas together. It uses off-the-shelf Wi-Fi radios (or similar RF devices) to sense people’s body pose, head location, and even ear position. It can pick up tiny signals—like your heartbeat or breathing—because these cause small movements that change the radio waves. With smart algorithms and machine learning, it can map these signals to actual body positions, even for more than one person. Then, it uses this data to control a spatial audio system in real time, creating the right HRTF for each listener and steering sound beams right to their ears.
This approach avoids the privacy concerns of cameras, the hassle of wearables, and the limits of fixed “sweet spots.” It can adapt to people moving around, and even distinguish between multiple listeners. It can also work with standard Wi-Fi hardware, making it easier and cheaper to deploy. By including feedback from the sound environment (using microphones, for example), it can further fine-tune the effect.
Invention Description and Key Innovations
Let’s walk through what the patent claims and how the whole system fits together, in plain language.
At its core, the invention is a method and system for delivering spatialized audio to people in a room, using radio signals (like Wi-Fi) to figure out exactly where to send the sound. Here’s how it works:
First, the system sends out radio waves into the environment. These can be standard Wi-Fi signals, specialized radar signals, or other RF transmissions. As these waves bounce around the room, they’re reflected, absorbed, or scattered by people and objects. Human bodies, in particular, create distinctive patterns—not just because they’re big objects, but because they move in tiny ways. Your chest rises and falls as you breathe. Your heart beats. These small movements cause tiny changes (Doppler shifts) in the returned radio signal.
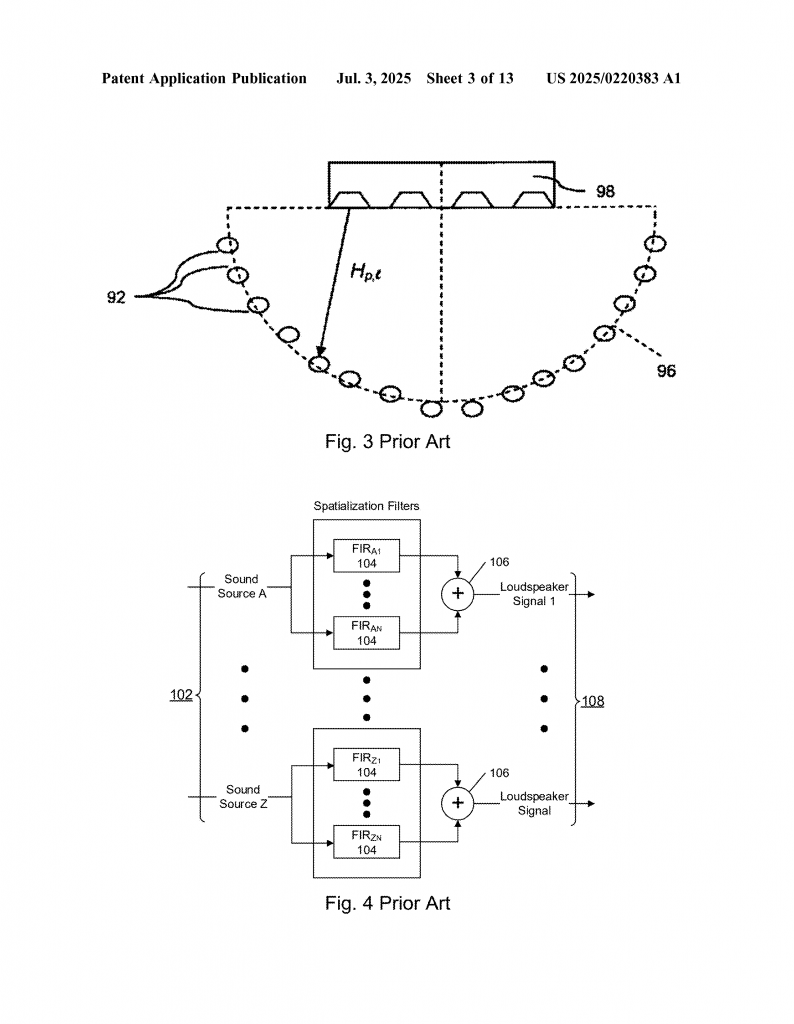
The system listens for these signals using one or more receivers—sometimes using the same device that sent them out, sometimes using dedicated sensors. It can use many antennas (MIMO), spread across a soundbar, TV, or even the walls. By analyzing the phase, amplitude, and timing of the received signals, it can build up a picture of what’s in the room and where people are.
Next, smart software—often powered by machine learning—processes this data to find the humans in the room. It looks for the dynamic patterns of heartbeat and breathing to spot live people (not just statues or furniture). Knowing where the chest is, it can infer where the head is, and from there, estimate the position and orientation of the ears. With more antennas or more advanced algorithms, it can get even more precise—tracking body pose, head tilt, and even gestures.
For even better accuracy, the system can use extra clues. Maybe the user is wearing glasses, earbuds, or even small, passive RF markers near the ears. But this isn’t required; the main idea is that it works “as is,” with nothing worn by the user.
Once the system knows where everyone’s ears are, it creates a custom HRTF for each listener. This can be generic (based on typical head and ear shapes) or personalized (if the system has calibration data or uses feedback from microphones near the ears). The audio content (music, movie, game sound, or even a conversation) is then processed through these HRTFs to create the right mix for each ear. This mix is sent to a speaker array, which uses beamforming to send focused “beams” of sound to the exact spots where the listeners’ ears are.
If there are multiple listeners, the system can separate the sound beams so that each person hears their own audio, or so that different audio is delivered to different people (for example, different languages, or private communication). It can also use masking sounds to ensure privacy, or adapt to changes in the room (like people moving, standing up, or new people arriving).
The system is designed to be smart and adaptive. It can update its estimates of ear positions in real time, track movement, and respond to gestures (like someone waving to adjust the volume). It can tune itself during setup with calibration routines, and then operate without cameras or manual intervention.
From a technical perspective, the patent covers several key innovations:
- Using radio frequency signals (especially Wi-Fi or compatible standards) to sense dynamic physiological patterns (heartbeat, breathing) as a way to find people and estimate body pose, head, and ear position.
- Channelizing the RF signals into multiple frequency subchannels, and using advanced measures (like Channel State Information—CSI) to get fine-grained data about the environment.
- Feeding the received RF data into neural networks or other machine learning models trained to map these signals to ear positions (using annotated training data from cameras or other sensors during setup, if needed).
- Generating spatialized audio for each listener, using the estimated head and ear positions and appropriate HRTFs, then emitting the audio through speaker arrays with precise beamforming.
- Handling multiple listeners, adapting in real time, and doing all of this without the need for cameras or wearable devices—protecting user privacy.
- Including optional feedback devices (microphones near the ears) for further calibration or personalization of the HRTF.
- Supporting standard hardware (like Wi-Fi radios), making the system easy to integrate into new or existing products.
All of this adds up to a system that can make spatial audio work for everyone, everywhere in a room, without special gear or privacy worries.
Conclusion
This patent application describes a leap forward for spatial audio—one that makes immersive, personalized sound possible in real spaces, not just with headphones or in perfect setups. By leveraging Wi-Fi and other radio signals already present in our homes, it senses where listeners are—down to their ears—and adapts the audio in real time. It blends advances in RF sensing, machine learning, and audio processing to overcome old limits and open up new experiences.
For users, this means a future where movies, games, music, and even meetings sound natural and real, no matter where you sit or move. For product makers, it promises new ways to differentiate and delight customers—without creating privacy headaches. And for the broader tech world, it’s a powerful example of how everyday signals and smart algorithms can work together to make life richer, simpler, and more secure.
Spatial audio is about to get a lot more personal, thanks to the invisible power of radio waves.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220383.