
Invented by Lee; Dean-yue, Rorie; Jamal
Machines can break down without warning, and catching small problems before they become big ones is very important. Today, we look at a new way to find machine problems early, even when the sensor data is thin and only collected during certain events. This new method uses more than one tool at once, checks the results, and helps keep machines running longer and safer. Let’s break down what makes this patent application unique and how it changes the way we think about machine health.
Background and Market Context
Modern machines, from cars to airplanes to factory robots, are packed with sensors. These sensors watch for issues, hoping to catch a problem before it causes a big failure. But not all machines can collect data all the time. Many machines, especially older ones or those with limited storage, only collect information when something important happens, like a sudden change in temperature or speed. This is called sparse, event-driven data.
Most old methods for finding problems look at regular, steady streams of data. They work well for new machines that collect lots of information every second. But when data is collected rarely and only at odd times, these methods do not work well. They might miss slow-growing problems or give false alarms. This can lead to missed warnings or too many false alerts, both of which can be costly.
There is also another challenge: many industries want to do what is called condition-based maintenance. This means fixing or replacing parts only when needed, not on a set schedule. This saves money, time, and resources. But to do this kind of smart maintenance, you need to be very sure about when something is starting to go wrong. If you cannot trust your data, this is almost impossible.
As machines get older and more mixed in terms of technology, there is a big need for tools that can make sense out of small, scattered bits of data. Factories, power plants, ships, and even airplanes are looking for better ways to catch early warning signs, especially when they have to work with less-than-perfect sensor data. This is where the new method described in the patent application comes in. It is designed to handle these tough situations and give clear, actionable results from very little data.

In today’s world, where uptime is money and safety is king, being able to spot trouble early is a huge advantage. Companies want tools that work with the data they already have, not just with the perfect data they wish they had. This new method fills that gap, giving maintenance teams a better way to keep machines running safely and smoothly, even when the data is sparse and the risks are high.
Scientific Rationale and Prior Art
To understand why this invention matters, we need to know how old methods work and why they fall short with sparse, event-driven data.
Most traditional anomaly detection tools are built for dense, regular data. They look for patterns, sudden spikes, or changes in data that are collected every second or minute. They use things like moving averages, thresholds, or machine learning models trained on lots of regular data. When the data is missing or comes in only during special events, these methods either miss signals or make mistakes.
There have been some attempts to fix this. Some systems use physics-based models, which try to guess what a machine should be doing based on its design and compare it to what the sensors say. Others use machine learning to spot outliers, but these models need a lot of data to learn from. Some newer tools use symbolic representations like SAX (Symbolic Aggregate approXimation), which turn time series data into strings of symbols to make it easier to spot weird patterns. There is also topological data analysis (TDA), which looks at the shape of data, not just the numbers. Each of these methods has strengths, but also weaknesses.
One common problem is that each method is sensitive to certain types of errors or “bias.” For example, a physics-based model might miss problems that are not directly tied to known machine physics. A machine learning model might get confused if there is not enough data or if the data is not regular. Symbolic methods need careful tuning and can give too many false alarms if not set up just right. TDA is powerful but can be hard to set up and explain.
Another big challenge is handling uncertainty. When the data is sparse, it is hard to know how sure you can be about any warning. Most old methods either ignore uncertainty or just give a simple “yes/no” answer. This is not enough for real-world decisions, where maintenance teams want to know how confident the system is in its alerts.
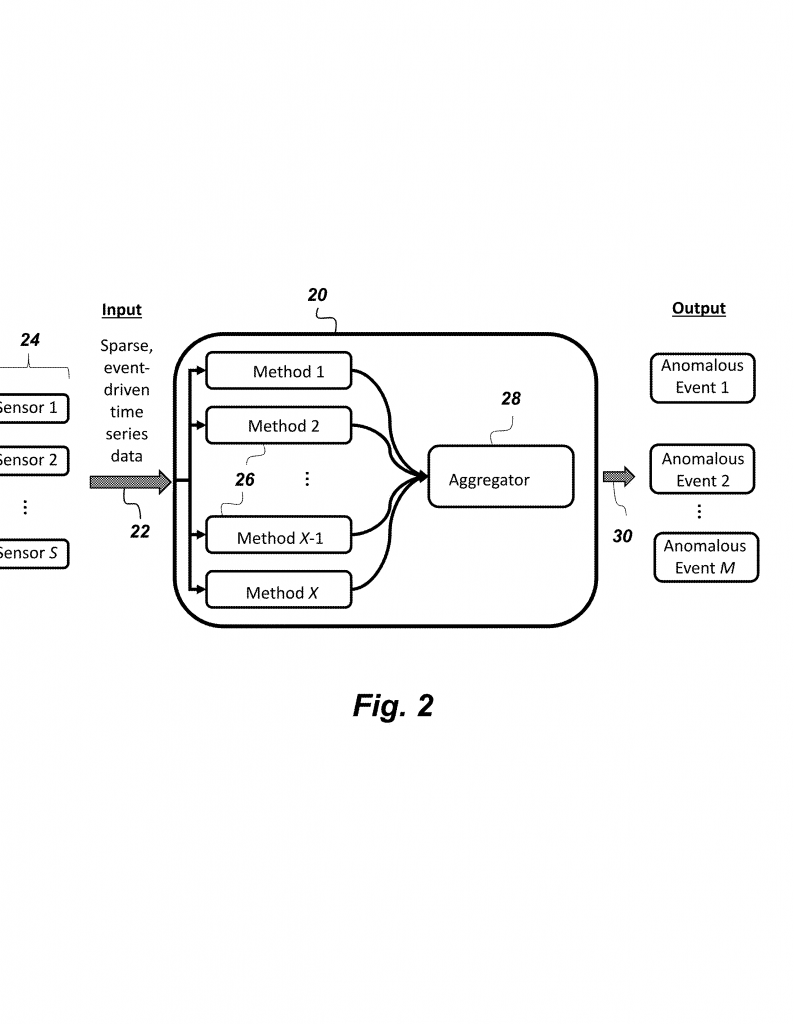
Past art also did not make it easy to combine many different types of anomaly detectors at once. Most systems use just one tool, or maybe two, but do not have a way to mix results, compare their confidence, or adjust which tools are being used on the fly. This limits flexibility and can leave gaps in coverage.
This invention builds on all these earlier ideas but does something new. It brings together different types of anomaly detectors (physics, machine learning, TDA, and more) in a single “ensemble.” Each detector looks at the data in its own way, gives a score, and says how sure it is. Then, a special processor combines the results, weighing each one’s score and uncertainty, to give a single, unified answer. This process uses ideas from conformal prediction, which is a smart way to measure and combine uncertainty across different tools.
By handling the weaknesses of each method and blending their strengths, this new approach gives a more reliable, flexible, and confident warning system. It also lets users add or remove detectors as needed, tune their confidence levels, and see only the results that meet a certain threshold of trust. This is a big step forward compared to old, single-method tools, especially for sparse, event-driven data.
Invention Description and Key Innovations
This invention is all about finding machine problems early, even when sensor data is thin and scattered. Here’s how it works, step by step, and what makes it different from anything before.
1. Collecting Sparse, Event-Driven Data: The system starts by gathering data from one or more sensors on a machine. But instead of needing lots of steady data, it works with whatever is there — even if data is only collected during certain events, not all the time.
2. Using a Heterogeneous Ensemble: This is the heart of the invention. Instead of using just one type of anomaly detector, the system uses a mix, or “ensemble,” of at least two (but often more) very different detectors. These can include:
- Physics-based models that look for changes in how the machine should act
- Machine learning models that spot outliers or weird patterns
- Symbolic methods like SAX, which turn data into symbols and look for odd “words”
- Topological data analysis (TDA), which looks at the shape or structure of data
Each detector works on its own, looking at different aspects of the data. Some might be better at catching sudden spikes, others at spotting slow changes. Each one gives an output: a score (how likely there is a problem) and an uncertainty (how sure it is about that score).
3. Aggregating Results with Uncertainty: Once each detector has done its job, their scores and uncertainties are sent to a processor. This processor combines all the results into a single “unified output.” It balances each score based on how sure the detector is. If one detector is very confident, its result might carry more weight. If another is not so sure, it is balanced accordingly. This way, the final result is more reliable than any single detector on its own.
4. Flexible Ensemble Management: The system is smart enough to add or remove detectors from the ensemble on the fly. If the overall confidence drops, it can add more detectors. If a detector keeps giving doubtful or false results, it can be removed. This makes the system very flexible and able to adapt to different machines, situations, or even changing data patterns.
5. Adjustable Confidence Thresholds: Users can set how confident they want the system to be before it shows an alert. If they want to see only the most certain warnings, they can raise the threshold. If they prefer to catch even the smallest hints of trouble, they can lower it. This helps maintenance teams balance between false alarms and missed warnings.
6. Prognosis and Preventive Action: The final output is not just a warning, but also gives a measure of how certain the system is about the problem. Maintenance teams can use this information to decide when to inspect, repair, or replace parts. In some cases, the system can even help decide which part to replace or what maintenance to do, before a failure happens.
7. Conformal Prediction for Unified Output: The method uses a clever statistical trick called conformal prediction. This lets the processor combine uncertainties from all detectors in a fair, mathematically sound way. It creates a score that tells not only if there is a problem, but how sure the system is, and how “wide” the window of uncertainty might be.
8. Works Across Machines and Domains: The method is not tied to any one machine or industry. It can be used on engines, pumps, motors, bearings, ships, airplanes, cars, and even weather data. The ensemble can be tailored to each platform, adding or removing detectors as needed for the specific machine or environment.
9. Detects Precursors, Not Just Failures: One of the most powerful features is that it can spot early warning signs — changes that come before a real breakdown. This gives teams time to act before a small problem becomes a big one.
10. Data-Driven and Human-Aided: The system can learn from new data, adjust its thresholds, and even help humans find problems they might have missed. If a strange pattern shows up that was not recorded by human observers, the system can flag it for review. This helps catch hidden or overlooked issues.
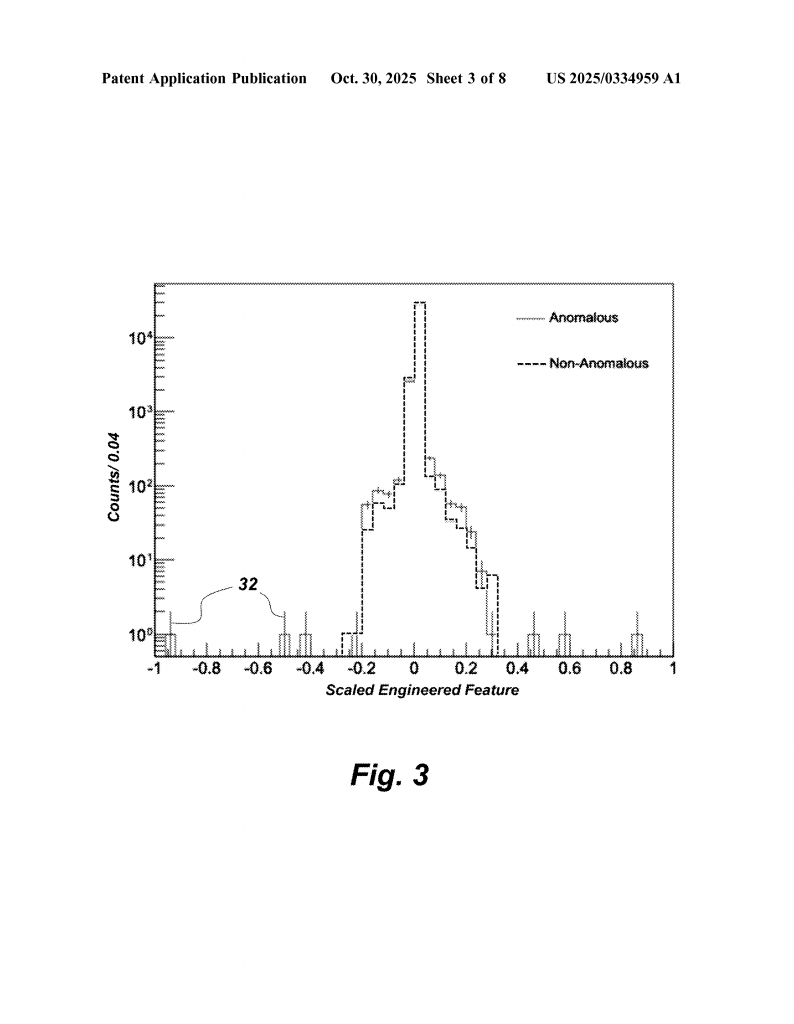
Real-World Example: In tests with engine data from several machines, the system looked at data from both failed machines and healthy ones. It found clear differences in certain features, even when data was sparse. The ensemble approach was able to spot problems with high accuracy, sometimes even finding issues before humans did. When symbolic methods like SAX were used, the system could detect unique “words” in the data that matched up with known problems, and even catch issues before they caused real trouble. By combining all the detectors and managing their confidence, the system gave much clearer, more reliable warnings than any single detector could.
Conclusion
This new method for finding machine problems early is a big step forward, especially for machines that can only collect data now and then. By using a team of different detectors, checking their confidence, and combining their results in a smart way, it gives clear, actionable warnings that maintenance teams can trust. It adapts to different machines and changing conditions, and it helps keep everything running smoothly, safely, and cost-effectively. For anyone who relies on machines and wants to avoid unexpected failures, this is a powerful new tool to have.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250334959.