Invented by Bharadwaj; Harsha
Modern data centers and high performance computing systems rely on efficient network communication to move massive amounts of data quickly. When many devices send data to a single target at the same time, the network can choke, dropping packets and slowing everything down. This is known as incast congestion. A new patent application details a device and method that aims to solve this stubborn problem for RDMA networks. In this article, we’ll break down the background, science, and inventive steps behind this solution in simple terms.
Background and Market Context
The world of computing is changing fast. We have more data, bigger models, and the need to move them across more machines than ever before. In large data centers, companies use groups of graphics processing units (GPUs) to train artificial intelligence models or to process huge datasets quickly. But these clusters of GPUs need to talk to each other at high speed. Regular networks just don’t cut it—they’re too slow and too unreliable.
To keep up, companies use a special kind of network called RDMA (Remote Direct Memory Access). RDMA lets one computer put data straight into another computer’s memory, skipping the usual steps and making the transfer much faster. One popular way of doing this is called RoCEv2, which runs RDMA over regular Ethernet hardware but with some smart changes to make things reliable and fast. This is now common in data centers that work on artificial intelligence and big data.
But there’s a catch. In many AI or big data jobs, you often need to collect results from many devices and combine them, or share data from one device with many others. This is called many-to-one communication. For example, in an “All-Reduce” operation, every GPU sends its results to one place to sum them up before moving on. When lots of machines send data to one machine at the same time, all that data can pile up at a network switch’s output port, overfilling its buffers. This is called incast congestion. It’s like too many people trying to get through a single door at once. Some people get stuck, some get pushed back, and everyone is delayed.
To keep things running smoothly, networks use something called Priority Flow Control (PFC). PFC tells the sender to pause when the receiver’s buffer is full. This usually works, but with incast congestion, pausing can make things worse. When the switch tells the senders to stop, the hold-up can spread back up the chain, pausing unrelated data flows and causing delays far away from the original problem. This is called “congestion spreading.” It makes the network unfair—flows that have nothing to do with the bottleneck get slowed down too.
The market needs a better way to manage incast congestion, especially as data centers grow and as workloads become more complex. Without a solution, AI jobs take longer, resources are wasted, and customers are unhappy. A fix that targets only the sources of congestion, without hurting others, would be a big step forward. The patent application we’re exploring introduces just such a solution.
Scientific Rationale and Prior Art
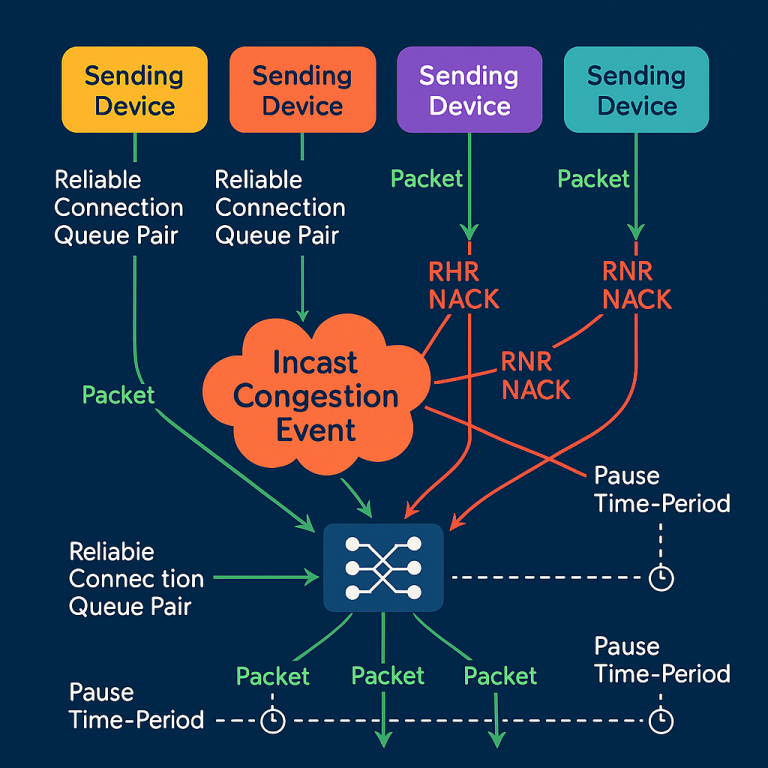
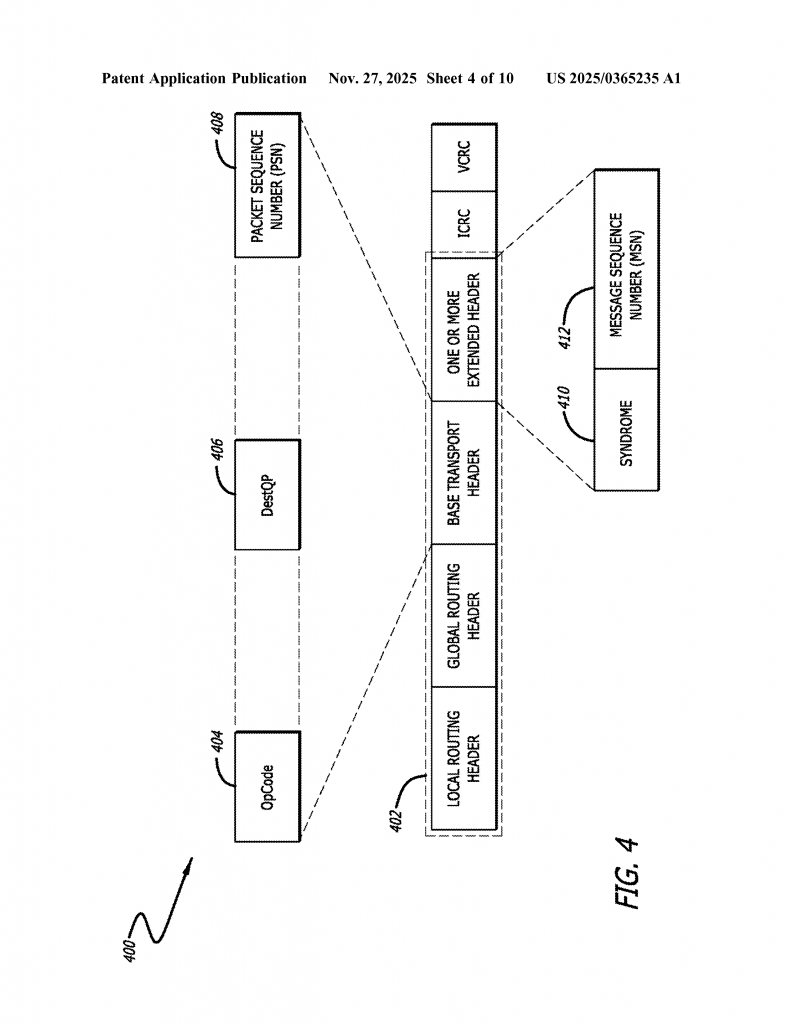
To understand the new invention, we need to review how RDMA networks and prior congestion control methods work. RDMA uses a system of “queue pairs” (QPs)—a send queue and a receive queue for each connection. Each message sent across the network is tagged with a Packet Sequence Number (PSN), making sure that packets are processed in the right order and nothing gets lost. Reliable Connection (RC) mode in RDMA ensures that messages go from sender to receiver in the right order, with no data lost or mixed up.
In current systems, when congestion is detected (for example, by monitoring how full a buffer is), the network can signal the sender to slow down or stop. This can be done using PFC or other methods like ECN (Explicit Congestion Notification). ECN marks packets when congestion is detected, and the receiver tells the sender to slow down. DCQCN (Data Center Quantized Congestion Notification) is another method that uses ECN marks to adjust sending speed.
But these methods have problems when it comes to incast congestion:
First, PFC works by pausing whole traffic classes, not individual flows. If one output port gets full, PFC tells all senders using that class to pause—even if their traffic isn’t causing the problem. This leads to unrelated traffic being stopped, which is unfair and wastes network resources. It can also cause “head-of-line blocking,” where packets at the front of the queue block others behind them.
Second, ECN and DCQCN rely on gradual congestion buildup to work well. But incast congestion can happen suddenly, with many flows arriving at once, overwhelming the buffer before the control loop has time to react. By the time ECN marks packets and the sender slows down, it’s often too late—packets have already been dropped, and retransmissions have started.
Third, tuning ECN or PFC thresholds is hard in large, complex networks. Too low, and you get lots of false alarms and unnecessary slowdowns. Too high, and you risk buffer overflows and dropped packets. Each switch, each port, and each traffic class may need different settings. It’s easy to get wrong.
Prior art does not provide a way to pause only the flows causing the incast, without pausing others. Nor does it provide a way to quickly and directly notify only the senders that need to slow down, without waiting for end-to-end feedback loops. The result is inefficiency, wasted resources, and slow job completion times.
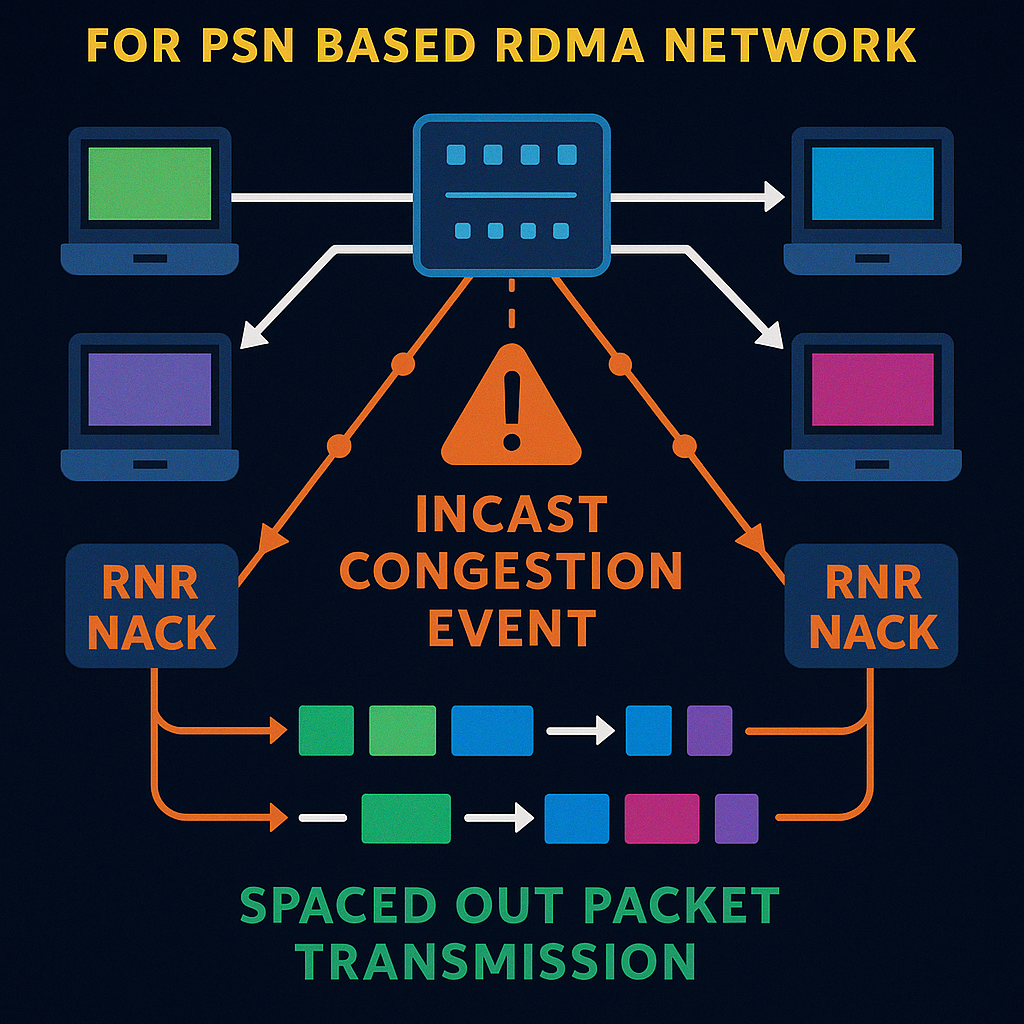
The new patent application recognizes these gaps and offers a targeted solution. Instead of pausing whole switches or traffic classes, it proposes a method where the switch detects incast congestion, identifies exactly which flows are to blame, and sends them a special negative acknowledgement (NACK) directly. This NACK tells the sender to pause just long enough for the congestion to clear—and each sender can get a different pause time, so they don’t all start up again at once and cause another pile-up.
The system leverages features already present in RDMA, such as PSNs and queue pairs, but uses them in new ways. It also takes advantage of switch capabilities like “packet trimming” (removing payloads) and “back to sender” functions, which help create the right kind of feedback without extra hardware. Importantly, this approach does not require changes to the end devices, making it practical for real-world deployment.
Invention Description and Key Innovations
The heart of the invention is a device and logic system inside a network switch (or similar network device) that can spot incast congestion as it happens, figure out which senders are causing the problem, and tell only those senders to pause—each for just the right amount of time.
Here’s how it works, step by step, in simple terms:
1. Detecting Incast Congestion: The switch watches its output buffer for each port. If too many packets come in at once and the buffer fills past a certain point (the “output buffer threshold”), the switch knows that incast congestion is happening. It can use other tricks too, like tracking packet loss, using predictive analytics, or listening for feedback from receivers, but watching the buffer is the main method.
2. Identifying Responsible Flows: The switch checks which flows (specifically, which Reliable Connection Queue Pairs, or RC QPs) are sending data through the congested port at that moment. It only needs to act on these flows—the others are not causing the problem.
3. Generating Negative Acknowledgements (NACKs): For each “guilty” RC QP, the switch creates a special message called a Receiver Not Ready (RNR) NACK. This is done by taking the first packet that would have been dropped, removing its payload, swapping the sender and receiver information, and turning it into a NACK format that the sender can understand. The NACK includes:
- The packet sequence number (PSN) of the first-to-be-dropped packet, so the sender knows where to restart.
- A pause time-period, telling the sender how long to wait before sending more packets.
Each NACK can have a unique pause time, based on things like round-trip time for the connection, so all the senders don’t start up again at once and cause another incast.
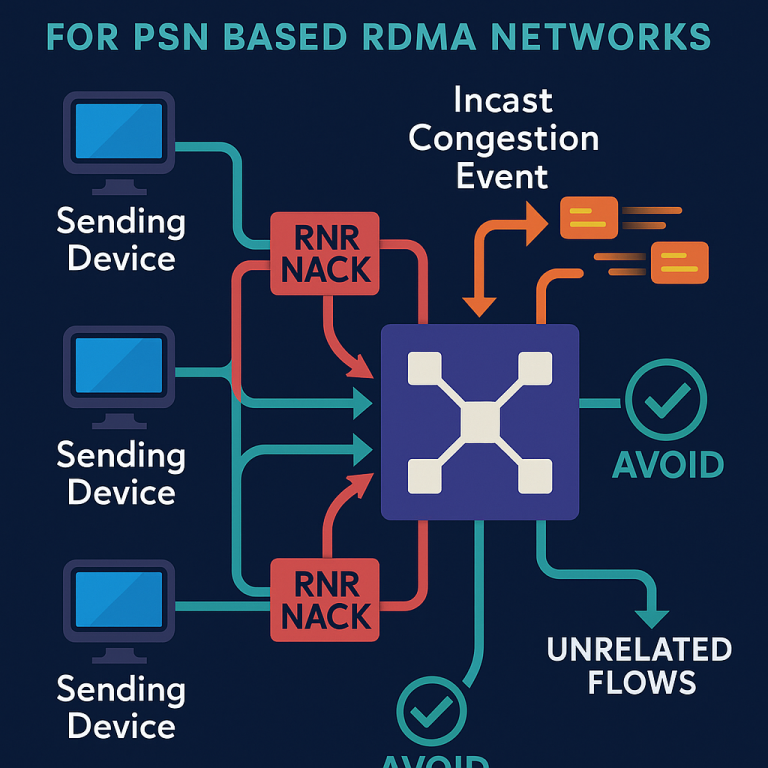
4. Sending the NACKs: The switch sends each NACK directly to the sender’s RC QP. When the sender gets the NACK, it pauses sending on that queue only, for the time specified in the message. Other queues on the same device, or flows to other receivers, are not affected—they keep running as usual.
5. Resuming Transmission: When the pause time is up, the sender resumes sending packets, starting from the PSN given in the NACK. This way, no data is lost. Because each sender’s pause is slightly different, the packets don’t all arrive at the switch at the same time when traffic resumes. This spreads out the load and helps prevent another incast congestion event.
6. Dropping and Retransmitting Packets: During congestion, the switch may drop packets it can’t handle. But the receiver’s expected PSN is set according to the NACK, so any out-of-order or old packets that sneak through are ignored, keeping data consistency.
7. State Tracking: To generate accurate NACKs, the switch keeps track of two things for each RC flow: the destination QP and the current message sequence number (MSN). It does this by “snooping” on incoming packets and acknowledgements. This allows the switch to fill in the right fields in each NACK, making sure the sender gets all the information needed to resume correctly.
8. Implementation Simplicity: The system uses existing features in RDMA switches, like packet trimming and back-to-sender functions, so it doesn’t require new hardware or changes to the end devices. The logic can run in software or programmable hardware inside the switch.
9. Selective Action: Only the RC flows causing the incast are paused. Other traffic—flows to other destinations, or other classes of service—keep moving. This prevents the “congestion spreading” problem that plagues PFC.
10. Flexibility and Learning: The system could use machine learning to predict incast congestion and act even faster, but the core invention works with simple buffer monitoring and logic. The pause times can be tuned based on network conditions, and the design supports future enhancements.
This targeted, quick-acting method keeps the network running smoothly, ensures that only the right flows are paused, and gets everything back to normal as fast as possible. It lets big data centers and AI clusters process jobs faster and more reliably, without the delays and unfair slowdowns caused by old-style congestion controls.
In summary, the key innovations in this patent application are:
- Detecting incast congestion based on buffer thresholds in the switch.
- Identifying only the flows (RC QPs) causing the congestion.
- Sending customized Receiver Not Ready NACKs to just those flows, with unique pause times.
- Using packet trimming and back-to-sender features to create NACKs from dropped packets.
- Maintaining state for each flow to fill out NACKs correctly.
- Allowing unrelated traffic to keep flowing, avoiding congestion spreading.
- Resuming traffic from the correct point, ensuring no data loss or duplication.
- Requiring no changes to end devices or network interface cards, making it easy to deploy.
This invention is not just a technical fix; it’s a practical, actionable solution ready for real-world data centers.
Conclusion
Incast congestion is a tough problem for modern data centers, especially in high-speed RDMA networks used for artificial intelligence and big data. Traditional solutions like PFC, ECN, and DCQCN are not precise enough and can make things worse by pausing unrelated traffic and reacting too slowly. The patent application we’ve explored introduces a smart, targeted method that detects incast congestion as it happens, identifies only the flows causing trouble, and tells just those flows to pause—each for exactly the right amount of time.
By leveraging features already present in RDMA and switch hardware, and by using a clever approach to state tracking and message formatting, this invention offers a practical fix that can be dropped into existing networks with minimal fuss. It keeps data moving, jobs finishing faster, and resources used more fairly and efficiently. For anyone designing or running large-scale data centers, especially those working with AI and big data, this is a solution worth watching.
The future of high-performance networking is about being smart, fast, and fair. With inventions like this, we’re getting closer to that goal.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250365235.