Invented by Bharadwaj; Harsha
Modern data centers are the beating heart of the digital world. With so much information moving through these centers every second, making sure all this data gets where it needs to go—quickly and smoothly—is very important. But what happens when the network gets stuck because data isn’t spread out well enough? This article explains a new way to fix that problem, using something called flowlet-based Network Address Translation (NAT) in a device called a Network Interface Controller (NIC). Let’s walk through the background, the science behind it, and the new invention that is set to change how data center networks work.
Background and Market Context
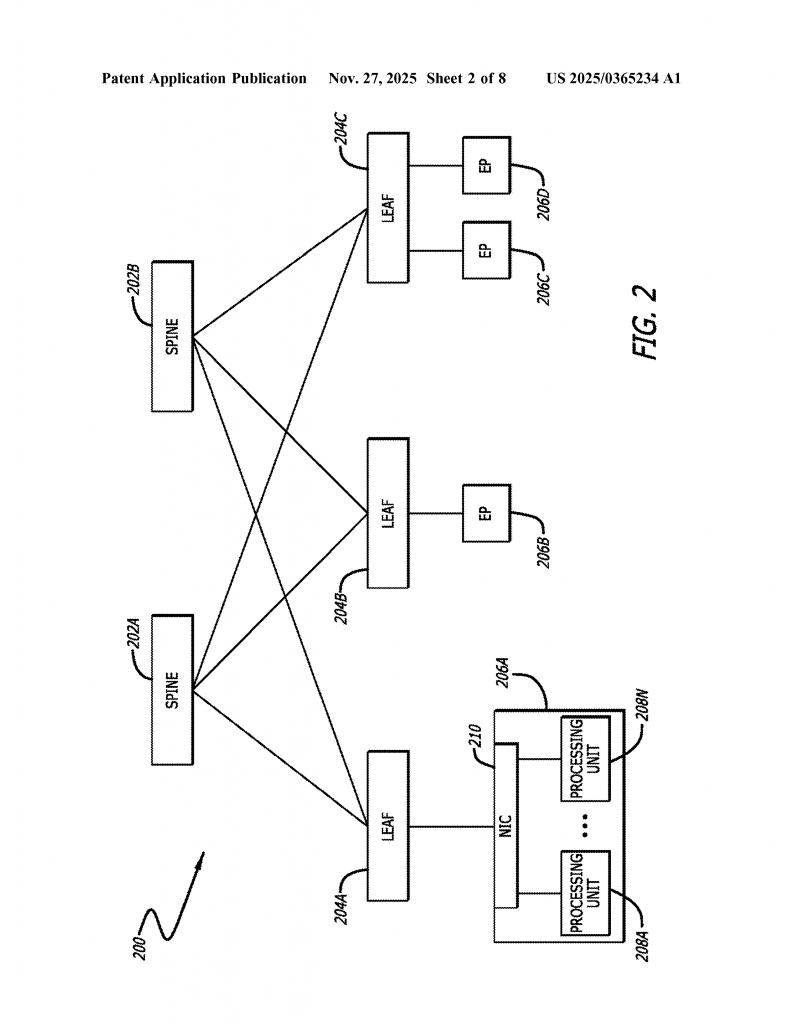
Data centers are like giant warehouses for information. Inside, there are many computers, called servers, that work together to handle requests from people all over the world. These servers often rely on high-speed connections to talk to each other, especially when working on big tasks like artificial intelligence or storing lots of files.
Within a data center, there are two main types of networks: front-end and backend. The front-end handles lots of small jobs, like sending emails or loading web pages. The backend is where the heavy lifting happens—huge chunks of data are shared between powerful computers, like Graphics Processing Units (GPUs), to train artificial intelligence models or process videos. These backend networks need to be fast and reliable.
To move data, backend networks use special technology called Remote Direct Memory Access (RDMA) over Converged Ethernet version 2 (RoCEv2) in Reliable Connection (RC) mode. This lets GPUs share information quickly. However, even with this great technology, there is a big problem: the network doesn’t always use all its paths equally. Some paths get crowded while others are empty. This means some data moves slowly, causing bottlenecks and delays.
This problem is called low flow entropy. In simple words, there are not enough unique data flows for the network to split the work evenly. In backend networks, there may only be a few hundred flows at once, compared to the thousands or millions in front-end networks. Because of this, the network’s load balancing system, which tries to spread out the work, often fails to do it well. The result is some parts of the network are overworked, while others are barely used.
Many companies have tried to solve this by using methods like Dynamic Load Balancing (DLB) or packet spraying, but each method has its own problems. DLB needs special signals from the network to work well, but these signals can be blocked by other features. Packet spraying sends single packets over different paths, but it needs new hardware and support from all devices involved, making it hard to use in existing data centers. These challenges show that a new, simple, and effective solution is needed to keep backend data centers running smoothly, especially as artificial intelligence and cloud services keep growing.
Scientific Rationale and Prior Art
To understand how this new invention stands out, let’s first look at how networks have traditionally tried to tackle the flow entropy problem.
Imagine a big city with many roads, but only a few cars. If most cars take the same roads, traffic jams happen there, while other roads are empty. The same thing happens in networks. In backend data centers, there aren’t enough unique flows (“cars”) to make use of all the available network paths (“roads”). The network tries to spread out flows using a hash function, which works like a randomizer, but with few flows, randomness isn’t enough. Some paths get a lot of traffic, others get almost none.
Dynamic Load Balancing (DLB) tries to fix this by breaking up flows into smaller chunks called “flowlets,” and sending each chunk down a different path. It uses feedback from the network to decide which path to pick. But this needs special feedback signals, which can be blocked by features meant to protect important data flows, like Priority Flow Control (PFC) in RoCEv2 networks. If the signals don’t get through, DLB can’t do its job correctly.
Another approach, packet spraying, sends individual packets along different paths. This works well in theory, but in real networks, it needs every device (especially switches and network cards) to support reassembling packets in the right order. Most existing hardware doesn’t do this, or it requires a lot of resources to keep track of all the packets, which isn’t practical at a large scale. Plus, programming new behaviors into the switches often needs advanced tools like P4, which isn’t widely adopted yet.
Because of these hurdles, neither method has become the standard in backend networks. What the industry needs is a way to trick the network into thinking there are more unique flows, so that the load balancer can work better, but without needing new hardware, special feedback, or changes to existing software.
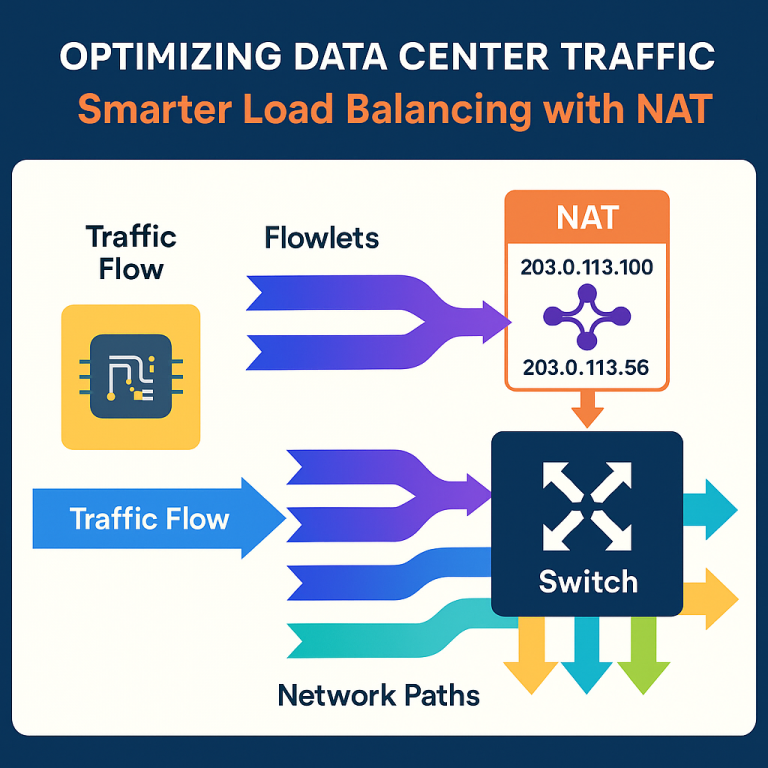
This is where Network Address Translation (NAT) comes in. NAT is usually used to hide the details of a network by changing the address information in packet headers as they pass through a device. The novel idea here is to use NAT at the NIC level—but not just for hiding addresses. Instead, it’s used to create more unique flows by changing the source port numbers in each chunk of data, or “flowlet.” This way, each flowlet looks like a brand new flow to the network, even though it comes from the same original source. As a result, the network’s load balancer can distribute these flowlets across all available paths, reducing congestion and making the network work more efficiently.
Unlike previous approaches, this method doesn’t depend on special signals or new hardware. It works with current switches and protocols, making it a practical and powerful solution for real-world data centers.
Invention Description and Key Innovations
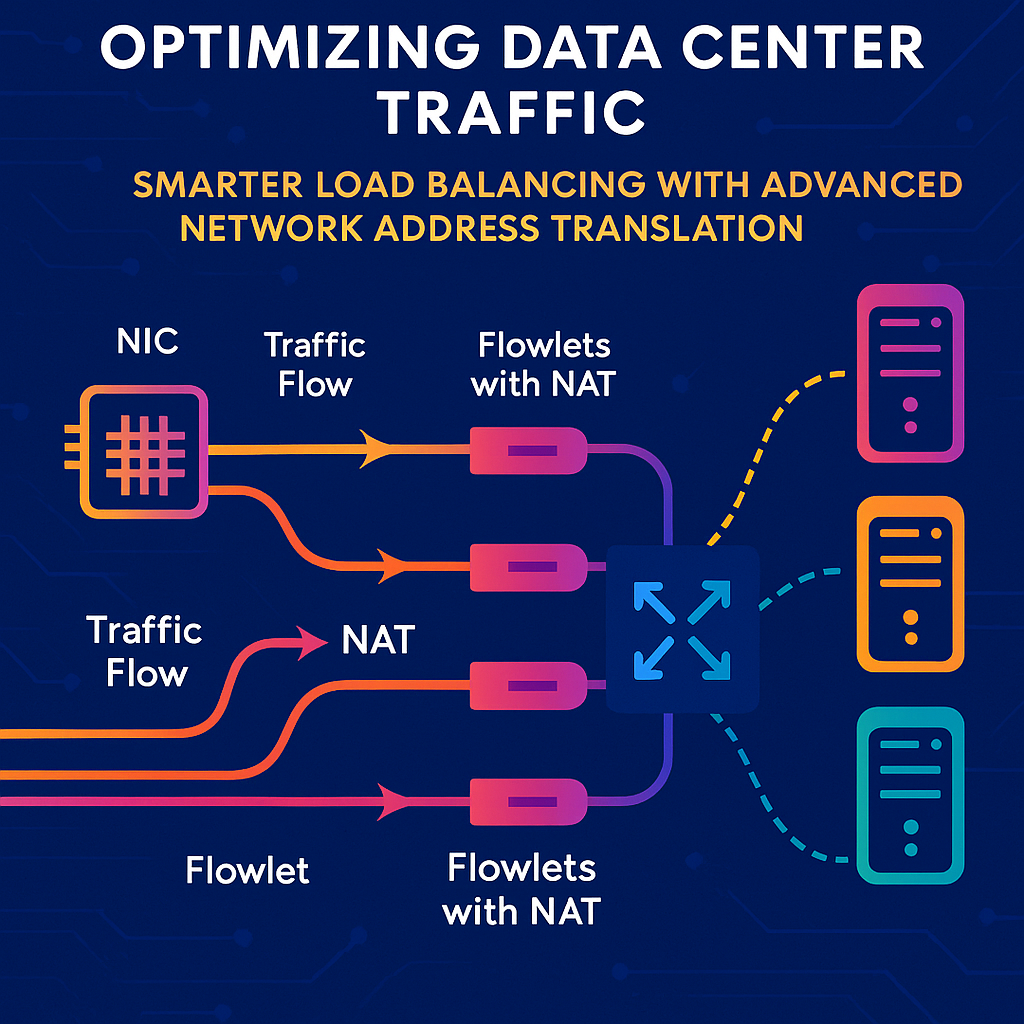
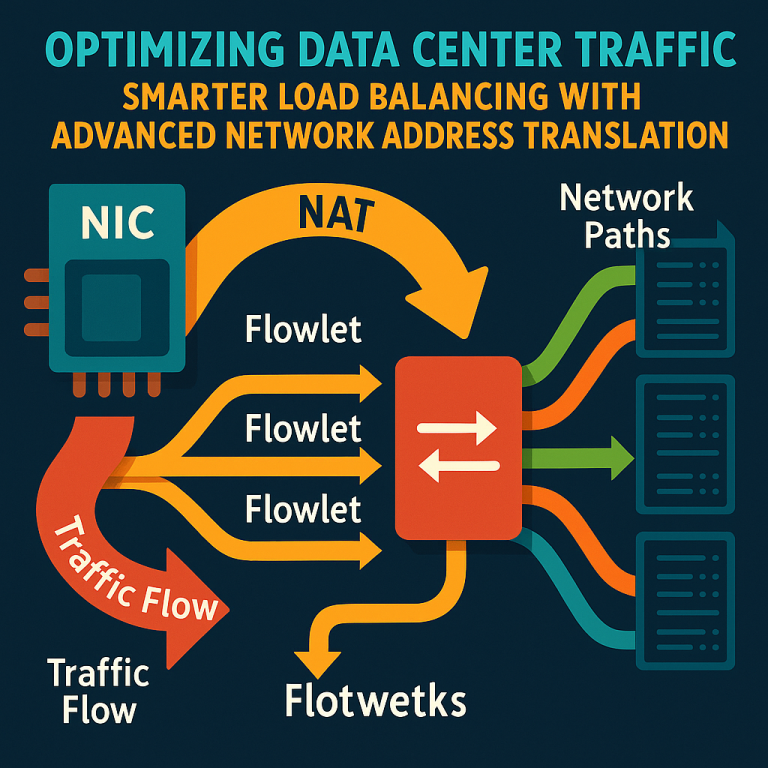
This invention centers on a smart logic built into the Network Interface Controller (NIC) that manages something called “flow entropy.” It does this by breaking down large flows of data into smaller chunks (flowlets) and making each flowlet look like a unique flow to the network. Here’s how it works, step by step:
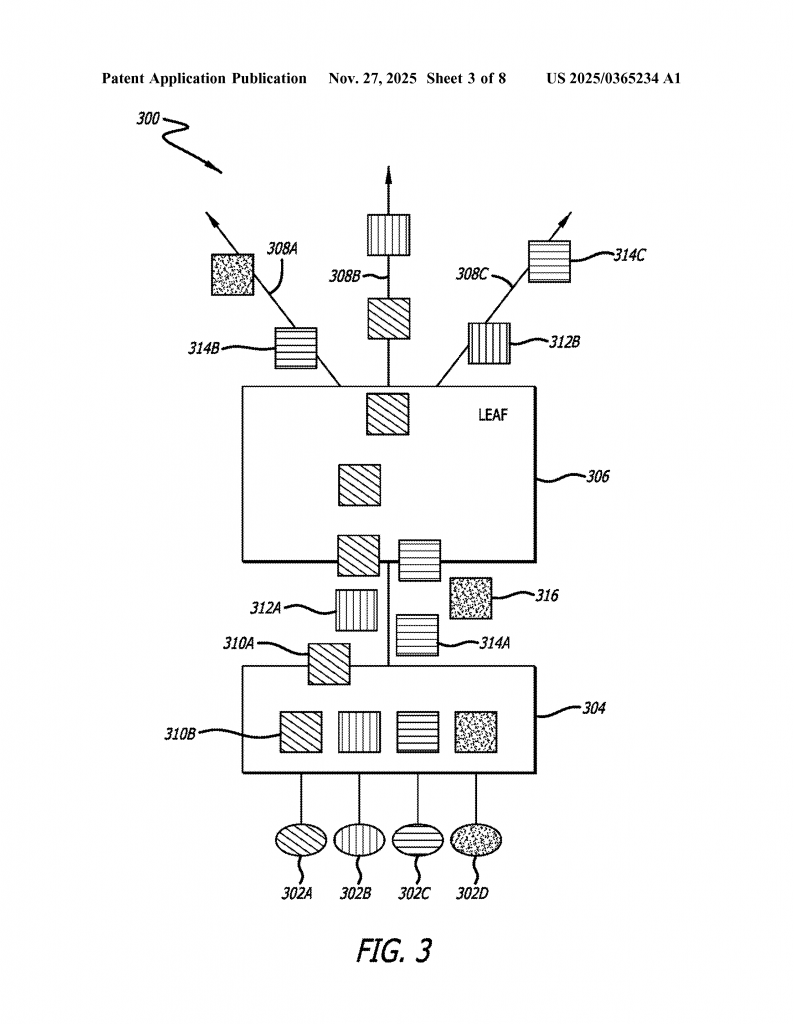
Flowlet Identification: When a GPU or processor starts sending a big stream of data, the NIC watches for breaks between packets. If the time gap between two packets is bigger than a certain threshold—usually the time it takes for a packet to go to the destination and back (called Round-Trip Time, or RTT)—the NIC treats the next packet as the start of a new flowlet. This means one big flow can be split into many smaller flowlets, each separated by these little pauses.
Unique Source Port Assignment via NAT: Each flowlet, by default, would use the same source port number, making it look like part of the same flow to the network. Instead, the NIC picks a new, unused source port number for each flowlet. It keeps track of which numbers are already in use by looking at a flow table. The unused source port number gets written into the header of every packet in the flowlet. This clever trick means that, to the network’s switches, each flowlet looks like a completely different flow—even though they all came from the same original source.
Mapping Table and Response Handling: The NIC keeps a mapping table to remember which original source port matches which new, fake source port. This is important because when a response comes back from the destination, it will be addressed to the fake port. The NIC checks its mapping table, swaps the fake port back to the original, and then sends the response to the right place. This makes the whole process invisible to the higher-level software and protocols—the system just works, without needing any changes in how the rest of the data center operates.
Load Balancing and Flow Aggregation: With each flowlet looking unique, the network’s load balancer can now spread them out across all available network paths. This evens out the traffic, prevents some links from getting too crowded, and makes sure all the resources in the data center are used effectively. If needed, the switch can still figure out which flowlets belong together by asking for the mapping table from the NIC using a simple handshake protocol. This helps with monitoring and managing the flows at a higher level.
RTT Detection Methods: The NIC can use either a simple method (by measuring the time it takes to get acknowledgements for packets) or a more active method (sending out special probe packets) to learn the right RTT for each destination. This ensures that flowlets are defined at the right spots, so packets don’t arrive out of order, keeping the data consistent and reliable.
Practical Implementation: All of this happens inside the NIC, which is a piece of hardware already present in every server. It doesn’t require new switches, new network protocols, or changes to existing applications. It’s a drop-in solution: just update the NIC’s logic, and the network gets smarter right away.
Benefits: By making each flowlet look like a new flow, the network’s load balancer finally gets enough “cars” to fill all the “roads,” spreading out the load evenly. This reduces congestion, speeds up data transfers, and makes the most of expensive data center hardware. It also works without major changes to the rest of the network, so companies can deploy it quickly and with little risk.
Key Innovations:
– Using NAT at the NIC level to rewrite source port numbers for each flowlet, creating high-entropy (many unique) flows without changing the actual data or needing new hardware in the switches.
– Keeping a mapping table in the NIC for seamless reverse translation of ports, so response packets are correctly routed without the higher-level software ever noticing the trick.
– Dynamically measuring RTT to split flows at the right moments, ensuring packets stay in order and data stays reliable.
– Allowing switches to aggregate flowlets for management and monitoring, using simple handshake protocols to fetch mapping info when needed.
– Making the solution fully compatible with existing protocols like RoCEv2 and with current switch hardware, so it can be adopted widely and quickly.
Conclusion
As data centers become more central to our digital lives, solving the problem of uneven traffic flow—known as low flow entropy—becomes more urgent. Traditional solutions like DLB and packet spraying have not fully solved the problem because they depend on special signals or require new hardware. The invention described here offers a practical, powerful fix: by breaking up flows into flowlets and making each flowlet look unique using NAT at the NIC level, the network’s existing load balancing can finally do its job well. This means less congestion, faster data movement, and better use of expensive network equipment.
The best part? This solution works with the hardware and software most data centers already have. There’s no need to rebuild the network or retrain staff. By simply upgrading the NIC logic, data centers can unlock new levels of efficiency and reliability—keeping pace with the growing demands of cloud computing and artificial intelligence.
For anyone running a modern data center, this approach to flow entropy management is not just a technical upgrade—it’s a smart business move that lets you get more out of your existing network, with less hassle and more confidence in your infrastructure’s future.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250365234.