Invented by Iyer; Ganeshan Ramachandran, Ramachandran; Raghav
Managing data is the backbone of almost every business today. As the amount of data grows, so does the challenge of keeping everything organized, up-to-date, and ready for analysis. The patent application we’re exploring describes a system for source monitoring in discrete workload processing. This is a smart way to make sure new data is noticed, fetched, and processed quickly and efficiently. In this article, we’ll break down what this new approach means, why it matters, and how it stands out from what came before.

Background and Market Context
Think about all the ways companies use data: from tracking sales to storing customer photos, videos, and documents. Most of this information sits in large digital “warehouses” called databases. These databases can live in the cloud, on local servers, or a mix of both. Every time a new file is added or changed—like a sales report, an updated customer record, or a new photo—something needs to notice that change, fetch the new data, and put it where it belongs for the next steps of processing or analysis.
In the past, this was mostly done by setting up schedules or manual checks. For example, you might have a script that checks every hour to see if there is new data, or someone might press a button to start an update. As companies grew and started using more cloud services, this got harder. Data could come from many places at once—internal company storage, cloud platforms like AWS or Azure, or even third-party apps. The more sources you have, the harder it is to keep track of everything and make sure nothing falls through the cracks.
Businesses today want their data to be fresh and ready to use almost instantly. This is especially true for things like real-time dashboards, automated reports, or applications that depend on live data feeds. Waiting for hours—or even minutes—can mean missed opportunities or outdated insights. There is also the need to do all this without wasting computing resources, which can get expensive in the cloud.
Another big issue is that not all data is the same. Some is structured (like tables in a spreadsheet), some is semi-structured (like JSON files from web apps), and some is unstructured (like photos or videos). A modern system has to handle all these types and do it with as little manual setup as possible. Companies want systems that can be flexible, adapt to new types of data, and scale easily as the business grows.
This is where the system described in the patent comes in. It aims to give organizations a way to automatically notice when new data arrives, fetch it, and trigger further processing—all in a reliable, low-latency, and cost-effective way. It does this by building smart “source monitors” that watch for new data events, decide what to do with them, and feed them into processing pipelines that can be customized for different purposes. Let’s look at how this fits into the bigger picture of data management.
Scientific Rationale and Prior Art
Before this invention, most systems used simple polling or scheduled jobs to check for new or changed data. For example, a script might run every 15 minutes, look at a folder or database table, and record any changes. This works for small or slow-moving systems, but as the number of data sources and the volume of data grows, it runs into problems:

1. Latency: If your polling interval is long, you might not notice new data for a while. Make it shorter, and you waste resources checking too often, especially when there’s nothing new most of the time.
2. Resource Waste: Constantly polling every source uses up computing time and network bandwidth. In the cloud, this means higher costs for no real benefit.
3. Complexity: Each data source might need its own script or polling logic, which is hard to manage and scale. If you want to add a new data type, it usually means writing more code.
4. Hard to Integrate: Getting notifications from sources like message queues, cloud events, or streaming topics (like Kafka) often requires different tools or connectors. It’s hard to have one system that handles them all.
Some systems tried to use event-based triggers, such as cloud storage services that send messages when a new file is uploaded. While faster and more efficient, each platform has its own way of doing this, and not all data sources support it. Plus, when you have multiple sources and need to coordinate them, things get complicated quickly.
Another challenge is what to do with the notifications once you get them. You need to filter out duplicates, ignore irrelevant changes, and sometimes forward them to different processing pipelines. For example, a new image file might go into an image-processing workflow, while a new sales record triggers a different set of steps. Keeping track of all this logic can be a headache, especially as needs change over time.
Some platforms tried to build more sophisticated “pipelines” that let you define a set of steps for processing data, but even then, setting up the monitoring part was often manual or required custom code for each use case. If you wanted to add a new source or change how notifications were handled, you might need to rework the whole system.
There were also issues with security and integration. Accessing external data sources safely often meant managing lots of credentials and making sure everything was authorized correctly. Mistakes here could lead to data leaks or failures in fetching data.
In short, the prior art was either too simple (and wasteful), too rigid (hard to adapt to new types of data or sources), or too complicated (requiring lots of custom code and manual setup). What was missing was a way to:
– Automatically set up source monitors in a flexible, reusable way
– Handle many kinds of data sources (internal, external, message queues, cloud events, etc.) under one roof
– Filter, deduplicate, and route notifications as needed

– Integrate scheduling and authentication without lots of manual work
– Scale up or down efficiently as the workload changes
The system described in this patent brings all these pieces together, making it easier for companies to manage their data flows in a way that’s both smarter and more cost-effective.
Invention Description and Key Innovations
At the heart of this invention is the idea of a processing pipeline and a source monitor. Here’s how it all works in very simple words:
1. Defining Processing Pipelines
A processing pipeline is just a set of steps that should happen when new data arrives. You can think of it like a recipe: first do this, then do that. Each step can be customized for the type of data and the job you want to do (like cleaning, transforming, or loading data).
The system lets you define these pipelines with many configurations, so you can have different steps for different types of data or sources. For example, processing an image file might involve a different pipeline than processing a sales record.
2. Creating Source Monitors
Instead of writing code to check each source for new data, the system creates “source monitors.” These are smart watchers that know how to look for new notifications from many kinds of sources—like cloud storage, message queues, or databases. Each source monitor is defined by a set of rules about what to watch, how often to check, and how to handle the results.
The beauty is that these monitors are not hard-coded. You can create a new one just by giving it a definition that points to the source, sets up the schedule, and says what should happen when something new is found. The system takes care of the rest.
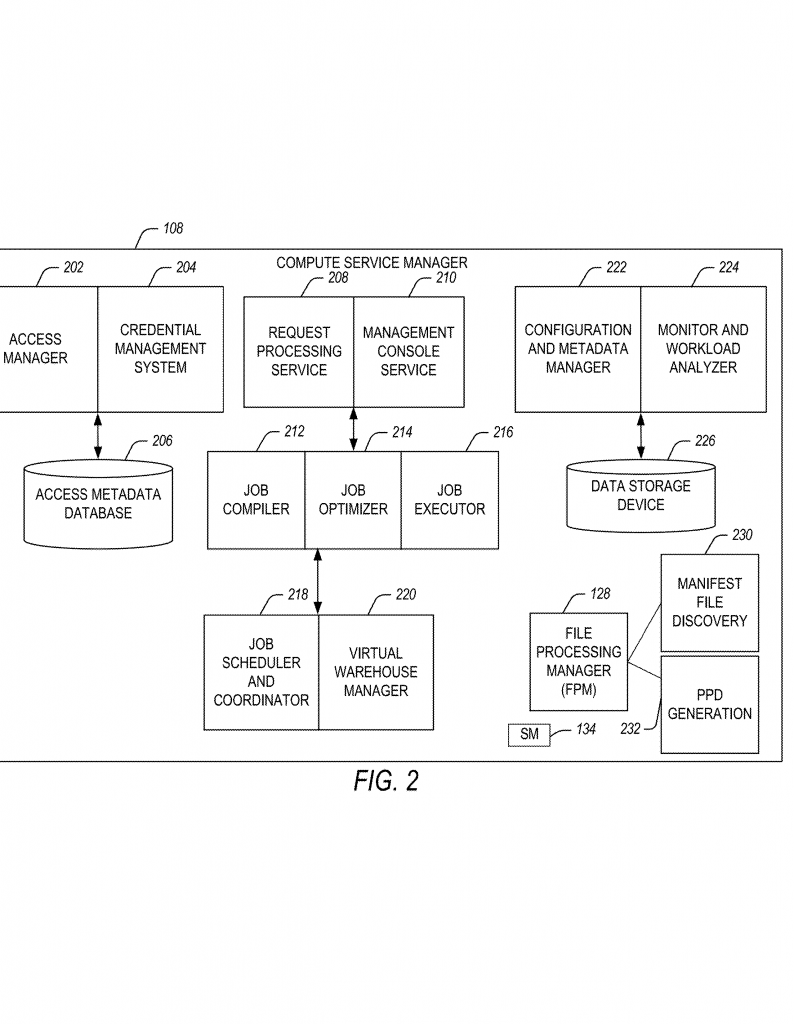
3. Scheduling and Integration
The system supports setting up schedules for how often each monitor should check for new data. Some sources might be checked every minute, others every hour, depending on how fast the data changes. It also lets you add integration details, like authentication info, so monitors can access protected data safely and securely.
If the integration or scheduling needs to change, you just update the configuration—no need to rewrite code or restart the whole system.
4. Fetching and Filtering Notifications
When the source monitor runs, it fetches notifications—messages or events that say, “Hey, there’s something new here!” Each notification is checked against the monitor’s rules to see if it matters for any processing pipeline. If it does, it goes into a work queue for that pipeline.
The system can filter out duplicates, ignore irrelevant events, and even decide to send the same notification to multiple pipelines if needed. This is done by a notification handler that sits in the middle and applies the logic you set up in the definition.
5. Feeding Data into Processing Pipelines
Once notifications are accepted, the data is fetched and placed into a work item queue. Each processing pipeline then picks up items from its queue and runs the steps you defined—like cleaning, transforming, or analyzing the data. This is done automatically, and you can have multiple pipelines running in parallel, each with its own logic and resources.
6. Scaling and Efficiency
The system is built to scale up or down as needed. If there’s a lot of new data, more resources can be added to handle the load. If things are quiet, it can scale back to save money. All the scheduling, monitoring, and processing can be managed centrally, making it easy to see what’s happening and adjust as needed.
7. Security and Flexibility
Because the system separates the definitions (what to do) from the actual code (how to do it), it’s easy to update, extend, or secure. You can add new sources, change authentication, or edit schedules without stopping the system or risking mistakes. Security is handled through integration information stored securely and used only when needed.
Key Innovations in Simple Terms
– Smart Polling: Instead of dumb, time-based checks, the system knows how to poll different sources more efficiently and only fetch what’s needed.
– Reusable Definitions: Everything is defined in reusable, modular configurations. You can add or change sources and pipelines without touching the core logic.
– Centralized Scheduling: All monitors can be scheduled and managed from one place, making it easier to keep track and avoid overlaps or waste.
– Flexible Notification Handling: A notification handler checks, filters, deduplicates, and routes events to the right place every time.
– Integration with Authentication: Secure access to data sources is built in. You can manage credentials and permissions easily, which is critical for enterprise use.
– Automatic Scaling: The system can add or remove resources based on need, so you’re not paying for unused capacity.
– Supports Many Data Types and Sources: Whether your data is text, images, logs, or live messages, the system can handle it. It works with cloud storage, message queues, streaming platforms, and more.
– Parallel and Sequential Processing: Pipelines can be set up to run steps one after another or in parallel, depending on what’s best for the workload.
All of this adds up to a system that lets businesses move faster, stay more organized, and save both time and money. It turns the messy, manual world of data monitoring and processing into a smooth, automated operation that can adapt as needs change.
Conclusion
In today’s world, managing data is more important—and more challenging—than ever. The invention described in this patent is a big step forward in making data platforms smarter, faster, and easier to use. It does this by letting companies set up flexible, automatic source monitors that watch for new data, filter and route notifications, and feed them into powerful processing pipelines. Everything is defined in reusable configurations, with strong support for scheduling, security, and scaling. This means less manual work, fewer mistakes, and more time spent on actually using the data rather than just managing it. For any business looking to keep up with the pace of change, this kind of system is not just nice to have—it’s a must.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363108.