
Invented by LABONTE; Thomas, SURY; Samantika, JOSEPH; Douglas, GARA; Alan
Cache management in computers is one of those hidden heroes that quietly makes our devices run faster and smoother. When you open a photo, play a game, or load a web page, you’re depending on a system that moves data in and out of memory quickly and safely. But what happens when many parts of a computer want to use and change the same data at the same time? That’s where cache coherence comes in. Today, we’ll explore a new invention that promises to make cache systems even better, by letting different parts of a computer share data more smartly—down to the smallest pieces. This article will help you understand why this matters, how current systems work, and what’s so special about this new approach.
Background and Market Context
We live in a world where computers are everywhere. From cell phones to cloud servers, these machines are expected to do more things at once, and do them fast. Inside every computer is a processor—often with many “cores” working side-by-side, like a team of workers. Each core thinks fast, but the real magic comes when they can work together, share data, and not get in each other’s way.
To help with this, computers use something called a cache. A cache is like a super-fast notepad, sitting close to each core. Instead of going out to the slow main memory every time, the core can look in its own notepad for the information it needs. If the data isn’t there, it asks the next, slightly slower cache, and so on, until it gets to main memory. This whole system is made up of several layers: the upper-level cache (closest to the core), and the lower-level cache (shared by all cores).
But there’s a problem. When many cores want to use or change the same data, their notepads can get out of sync. For example, if Core A writes a new value, and Core B reads an old one, the whole program could get confused. To fix this, designers use cache coherence—rules and systems that keep everyone on the same page.
The challenge gets bigger as programs get more complex. Modern apps, games, and servers run code that often asks many cores to work with the same group of data—sometimes even the same cache line, which is a small block of data, like a row in the notepad. If two cores both want to write to different parts of that row, the system can get bogged down, constantly handing the whole row back and forth. This is called false sharing, and it wastes time and energy.
As more companies build computers with more cores, and as programs become more tangled and shared, the need for better cache management grows. Server farms, cloud computing, and even phones are moving toward designs with dozens, even hundreds, of processing cores. Here, every tiny delay or mistake in data sharing can mean slower apps, higher costs, and wasted electricity. That’s why new ideas in cache coherence—like the invention we’re going to discuss—are so important to the market today.
Scientific Rationale and Prior Art
Let’s take a step back and see how cache coherence works in most computers today.
The classic approach is something called the MESI protocol. MESI stands for Modified, Exclusive, Shared, and Invalid. Imagine a four-way switch for each row in the notepad:
– Modified: This core has changed the row, and others don’t have the new value.
– Exclusive: This core has the only copy, but hasn’t changed it.
– Shared: Many cores have the row, but nobody has changed it.
– Invalid: This core’s copy is old and must not be used.
Every time a core wants to read or change a row, the system checks and updates these states. If a core wants to write, it must make sure nobody else has write access. If it writes, other cores’ copies are “invalidated”—they’re told, “Don’t use your old copy anymore.”
This works well when the whole row is needed by only one core at a time. But real programs aren’t always this neat. Sometimes, different cores need to read and write different words (smaller pieces) within the same row. Imagine two kids coloring different parts of the same picture. If one wants to use a red crayon and the other wants to use blue, it doesn’t make sense to keep taking the entire picture away from one just because the other wants to color a different part. But that’s what happens with classic cache coherence: if one core writes to any word in the row, all other cores lose access to the whole row. This is the core of the false sharing problem.
Previous attempts to fix this include:
1. Software Padding: Programmers can spread out data in memory, so different cores don’t use the same row. But this wastes memory and isn’t always possible.
2. Fine-Grained Locks: Programs can use locks for each word, but this adds complexity and can slow things down.
3. Hardware Solutions: Some systems try to track changes at a smaller scale, but this often means a lot more tracking bits and bigger, more expensive hardware.
Even with these solutions, the basic problem remains: most systems still treat the cache line (the row) as the smallest piece for sharing and control. That means extra work, wasted energy, and slow-downs when programs “falsely share” a row.
Scientists and engineers have long wanted a system that can track who is using which words in a row, and allow different cores to read and write different words without bumping into each other. The trick is to do this without making the cache too big or slow. That’s the challenge this new invention aims to solve.
Invention Description and Key Innovations
Now let’s look at what makes this new cache management system special. The heart of the invention is a way to track and control sharing at the word level—not just at the row (cache line) level. Think of it as giving each kid their own part of the picture to color, with clear rules about who can use which crayon, so they don’t have to fight over the entire picture.
This system uses three main parts:
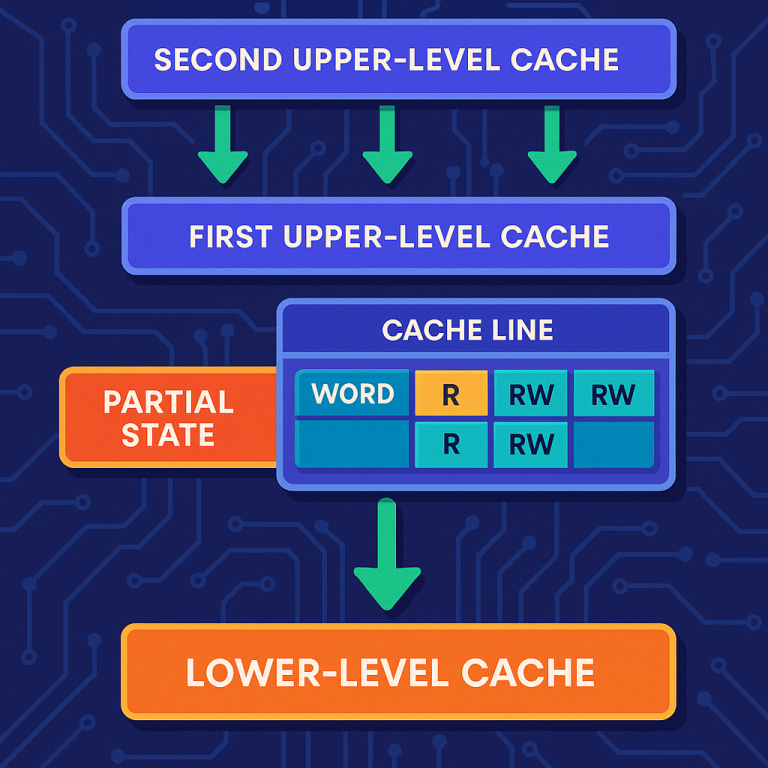
1. Lower-Level Cache: This is the shared notepad for all the cores. It keeps track of the overall state of each row, and also knows which cores are allowed to write to which words.
2. First Upper-Level Cache: This is close to Core A. It keeps its own notes about which words in each row it can read or write.

3. Second Upper-Level Cache: Close to Core B, with its own notes.
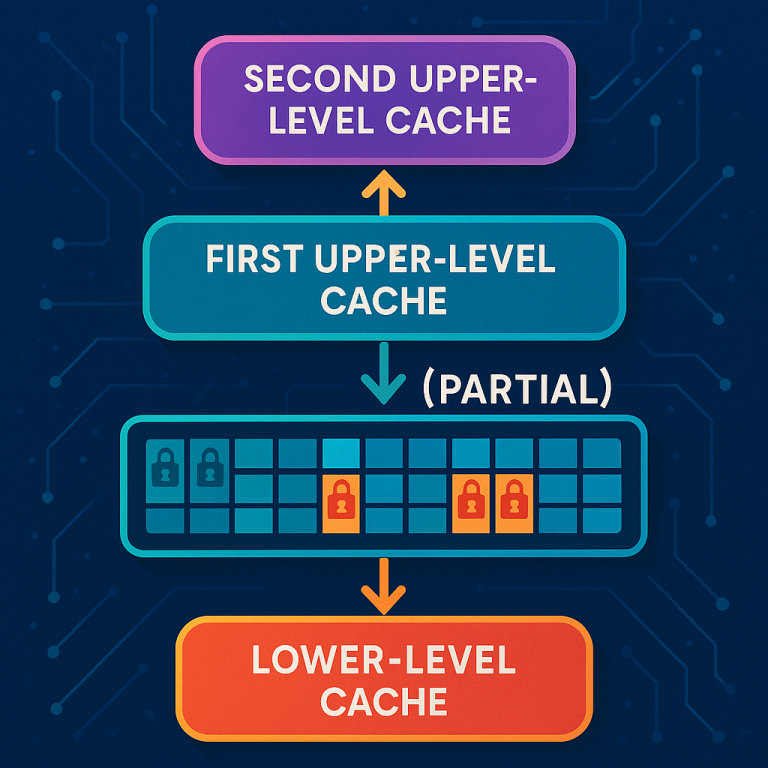
The magic happens with a new kind of metadata. For each row (cache line), the caches keep a record of which words are readable, writable, or invalid in each core’s cache. There’s a new partial state—meaning that, inside a row, some words have different permissions than others. For example, Core A might have permission to write to word 1, while Core B can only read word 2, and so on.
This metadata works like a set of switches—one for reading, one for writing, for each word in the row. If a core wants to write to a word, it asks the lower-level cache. The lower-level cache checks to see if anyone else is writing to that word, and updates its list of “writers.” If another core is reading the word, their read permission can be changed for just that word, not the whole row. All this happens behind the scenes, letting the cores keep working without getting in each other’s way.
Here’s how it plays out in practice:
– When Core A wants to write to word 3, it gets permission for just that word. Core B, which is reading word 4, keeps its read access to word 4.
– If Core B later wants to write to word 4, it asks the lower-level cache. The system updates the permissions so now Core B can write word 4, while Core A still writes word 3.
– If a core wants to read a word that another core is writing, the system decides whether to let the reader wait, or to “merge” the changes, depending on what makes sense for speed and safety.
This invention also lets the system “merge” changes from different cores when needed. The lower-level cache keeps a list of who wrote which word, so when it has to send the row back to memory, it can build the full, up-to-date row with all the latest changes.
Another smart feature is how the system chooses when to switch a row from “partial” state to “fully owned” by one core. If a core starts writing to several words in the same row, the system can decide to give that core full control, making things faster for big changes.
Why is this a big deal? Because it means:
– Less Wasted Time: Cores can keep working on their own words without having to wait for full rows to be handed back and forth.
– Less Energy Used: Fewer messages and less copying mean lower power use—a big win for phones and large servers.
– Smoother Performance: Programs that use lots of shared data, like databases and games, can run faster and more smoothly.
The invention is flexible, too. Designers can choose how small the “word” should be—maybe four bytes, eight bytes, or even one byte—depending on what fits their needs best. The system can also work with existing network-on-chip technologies, making it easier to use in real products.
In short, this new system lets computers share data at a much finer level, so more work can be done at once, with fewer slowdowns. It’s a smarter way for cores to play together, each with its own piece of the data puzzle.
Conclusion
Cache management may seem like something only engineers care about, but it touches every part of our digital lives. As computers get more powerful and more connected, the way they share data inside becomes even more important. This new approach—tracking data down to the word, not just the row—means less waiting, less fighting over data, and more speed for everything from cloud servers to your smartphone. By allowing each processor core to read and write its own piece of data without stepping on others, this invention opens the door to faster, more efficient, and more reliable computing for all of us. As technology keeps moving forward, solutions like this will help keep our devices running smoothly, no matter how much we ask of them.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363053.