Invented by CAHU; Arthur, MARCUSANU; Ana, Dassault Systèmes
In this blog post, we’ll explore a new way to teach computers to find objects in real-world 3D scenes. We’ll break down a recent patent application that introduces a smarter machine learning method for working with 3D point clouds. You’ll learn how this invention fits into today’s technology, how it builds on past ideas, and what makes it so special.
Background and Market Context
Imagine you walk into a room with your phone and use it to slowly scan the space. What happens inside your phone is amazing—tiny points are collected by the camera, each one marking a spot in the room. These points, together, form a “point cloud.” But while humans can look at the dots and know where the chair, bed, or table is, computers need help. That’s where machine learning comes in.
Right now, technology companies and researchers are racing to make computers smarter at understanding 3D scenes. This is important for things like home design apps, robots that move indoors, and even augmented reality games. The better these systems get at recognizing objects in 3D, the more useful and friendly our devices become.
The market for indoor 3D scene understanding is growing fast. Companies like Apple, Google, and many startups are working on ways to let users scan rooms and get instant feedback. For example, Apple’s RoomPlan helps people design their homes by detecting big objects like sofas or beds in real time as they move their phones. But there are limits: RoomPlan mainly finds large items, and struggles with smaller things, like books or lamps.
Most current methods are “offline.” This means they take all the scan data at once, ignore the order in which points were collected, and then try to recognize objects. While this works if you have already captured the whole room, it’s not very helpful if you want feedback while you’re still scanning. Imagine you’re scanning a room corner by corner and want to know right away if you missed something—today’s offline methods can’t help much.
Another problem is that offline methods need a lot of computer memory and time. Each time you add new points, you may need to start over or re-calculate a lot of things. This slows down the process and drains your phone’s battery.
Some new methods, borrowed from outdoor uses like self-driving cars, try to track both time and space, but they are often designed for big outdoor scenes and miss the fine details of indoor objects. Indoor scenes are trickier because objects can be stacked, hidden, or very close together. Plus, you may have both big objects and tiny items in the same space.
So, the need is clear: we want a way to scan a room, see what objects are already found, and get feedback in real time—no matter if you’re looking at a sofa or a book. The patent we’re discussing today sets out to solve exactly these problems, offering a new way for computers to learn and make sense of 3D scenes as the scan happens.
Scientific Rationale and Prior Art
To understand what’s new, let’s look at how things have been done so far.
Most modern 3D object detection systems use a kind of machine learning called neural networks. These networks are trained with lots of data—scans of rooms where every object is labeled. Famous datasets like SUN RGB-D and ScanNet are used for training. The main models, like FCAF3D and TR3D, use convolutional neural networks (CNNs) to process 3D data.
Here’s how a typical model works:
First, the raw point cloud is turned into a “voxel grid.” Imagine dividing the room into small cubes (like 3D pixels). If a cube contains any points, it’s marked as “occupied.” The grid size matters—a finer grid gives better detail, but uses more memory and takes longer to process.
Next, a CNN processes the voxel grid. The network tries to find patterns that match known objects, like the corners of a chair or the top of a table. But these models often make too many guesses, sometimes marking parts of the same chair as different objects. To fix this, a rule called “non-maximum suppression” (NMS) is used. NMS keeps only the best guess for each object, based on how much predictions overlap.
But there’s a big catch. These models treat the whole scan as a single snapshot. They don’t care about the order in which the room was scanned. This is called an “offline” method. It’s good for accuracy if the whole room is already scanned, but not if you want to see results as you go.
Apple’s RoomPlan tries to offer real-time feedback. But to do this quickly, it uses a coarse grid—meaning it only finds big objects, missing smaller items. Plus, it breaks the scan into chunks and runs detection separately on each chunk, then combines the results. This approach is fast but can miss things or get confused if objects are partly scanned.
Outdoor 3D detection models, such as PointPillars or BEVFusion, focus on moving objects in open spaces, like cars or people on the street. They often flatten the 3D problem down to a 2D “bird’s-eye view.” This doesn’t work so well for indoor scenes, where objects can be anywhere—on the floor, on a table, or hanging from the ceiling.
So, the main problems with prior art are:
– Offline models need the whole scene scanned before they can help.
– Online models are fast but miss small details or use tricks that only work for big objects.
– No system so far really uses the order of scanning to get smarter as new data comes in.
This is the gap that the new patent aims to fill. It combines the best of both worlds: using information about both space and time, so the computer can learn from how the scan unfolds and give feedback instantly.
Invention Description and Key Innovations
Now, let’s look closely at what this new patent brings to the table.
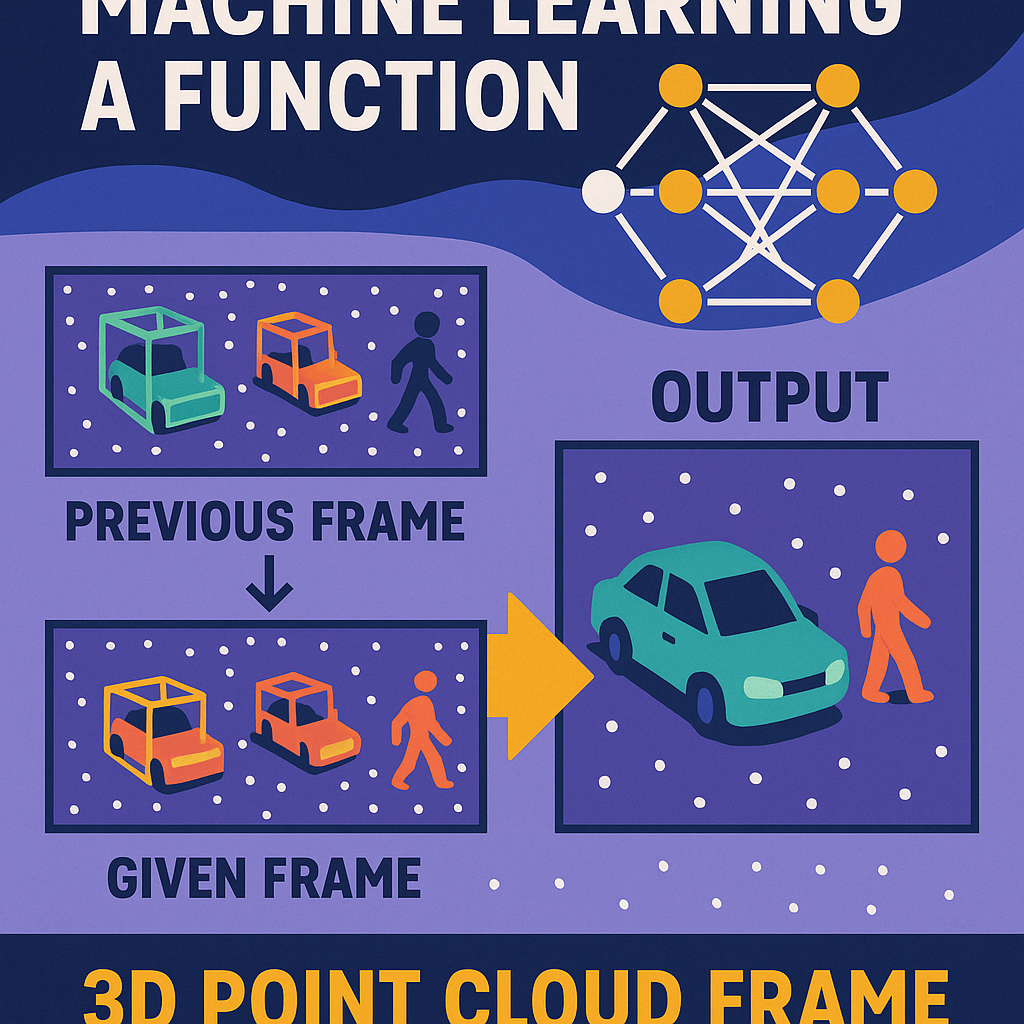
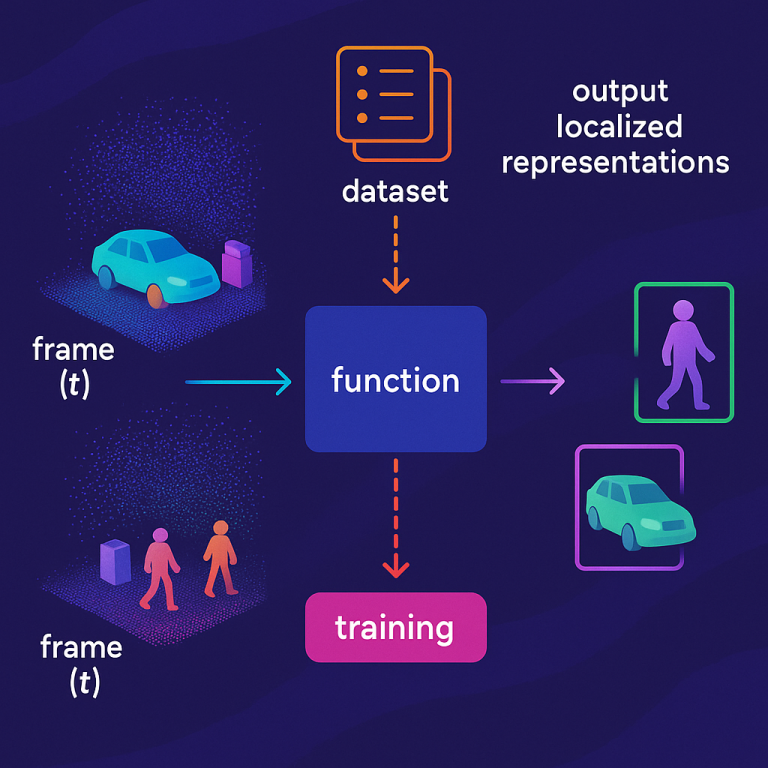
The heart of the invention is a computer-implemented method for training a function (think of a clever program) that takes a 3D point cloud frame and outputs “localized representations”—that is, for each object in the scene, it gives you its position and what kind of object it is (like “sofa” or “lamp”).
What’s special is how the training works. Instead of just looking at each frame alone, or lumping everything together, the function is trained to use both the current frame and at least the previous frame. This way, it learns how the scene grows as you scan, remembering what has already been seen and using that to make better predictions about new data.
The process starts with a dataset of sequences—each sequence is a list of point cloud frames, captured over time as someone scans a room. Each frame shows a part of the scene and comes with labels for every object found. The method trains the function so that, for each frame in the sequence, it predicts the objects in that frame using both the frame itself and the one(s) just before it.
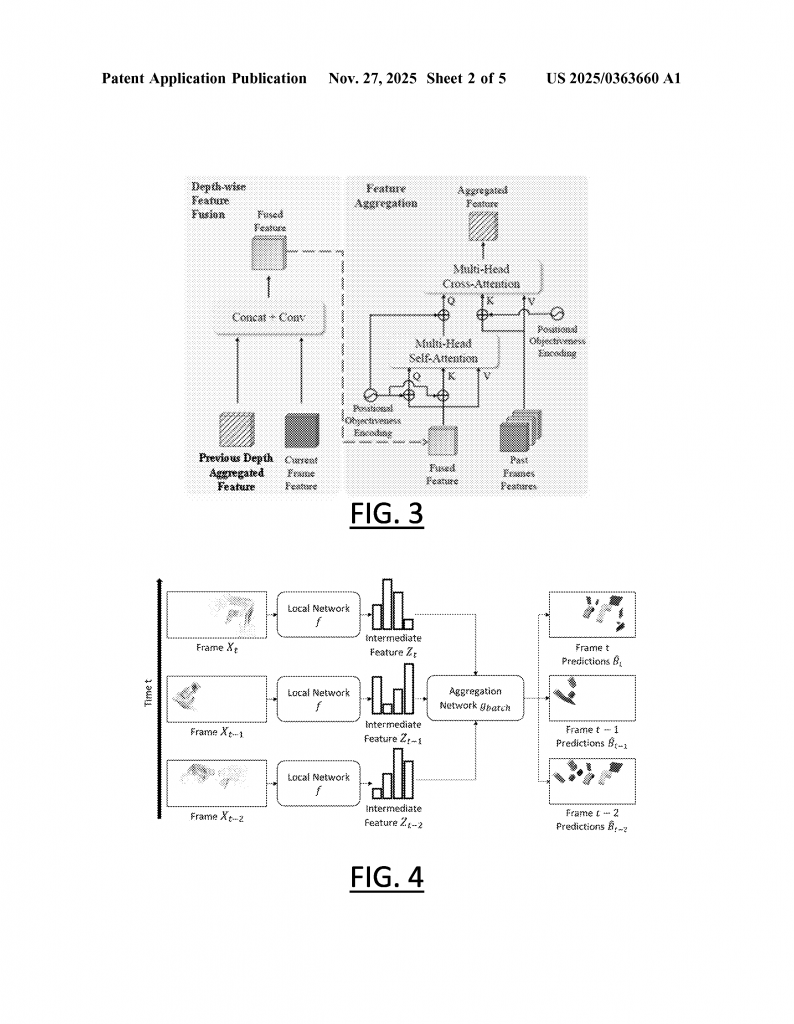
Inside the function, there are two main neural networks:
1. The first is a “local” network, like a CNN. It looks at each frame and creates a feature vector—a compact summary of what’s in the frame.
2. The second is an “aggregation” network (sometimes using transformers), which takes the feature vectors from the current and previous frames and combines them. This step helps the system understand how the scene is changing and what objects might be present based on what has already been seen.
If you imagine scanning a table with some books on it, the local network will spot parts of the books in each frame. The aggregation network will “remember” what was seen in the last frame, helping to piece together that it’s the same book, even if you only see a new corner each time.
Another advance is that the function can handle different resolution levels. For example, it can output feature vectors at both fine and coarse detail, which helps it spot both big and small objects. The aggregation network performs matching at each resolution, so no object slips through the cracks.
To make training efficient, the method uses “batch training,” processing several frames at once. But—and this is important—it always respects time order. The function never uses information from future frames when predicting the current one. This keeps it realistic for real-time use, where you can’t know the future.
The data for training can come from real scans (physical rooms) or virtual scans (simulated rooms). The method can work with any kind of 3D point cloud data, as long as you know the order in which frames were captured.
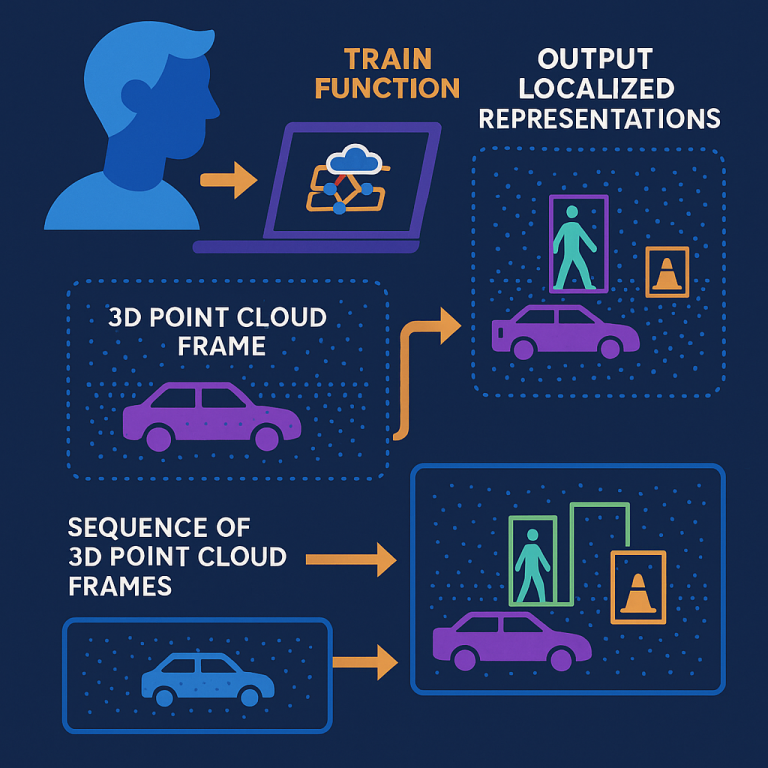
When the trained function is used, it takes a new sequence of frames as you scan. For each frame, it creates a feature vector, then combines it with previous vectors to figure out which objects are present, where they are, and what kind they are. The output is a set of localized representations—think of them as little boxes drawn around every object, with labels.
A key benefit is that the aggregation network is much lighter (uses less memory) than the local network. So, once the local network has processed a frame, the aggregation can quickly update predictions as you scan new areas. You don’t need to keep all past frames in memory—just the feature vectors from the last few frames. This makes the method fast and practical for phones or tablets.
The system can be implemented as a computer program, run on a device, or even as a cloud service. It can give users real-time feedback as they scan, telling them instantly if they missed an object or if more scanning is needed in a certain spot.
Tests show that this new method is much more accurate for online detection than simply concatenating frames and running an offline detector. It can spot both big and small objects, works in real time, and is smart about using past information to improve its guesses.
In short, the invention teaches computers to think not just about what they see now, but also about what they saw a moment ago. This “memory” helps make sense of tricky scenes and gives much better feedback to users as they scan.
Conclusion
This new method for machine learning on 3D point clouds changes how computers see and understand real-world scenes. By using both the current view and what was seen before, it brings real-time, accurate object detection to mobile devices and other platforms. It solves big problems in today’s technology, letting you scan a room and get instant, smart feedback—no matter what you’re looking for. As more devices use 3D scanning, inventions like this will become key to making our digital experiences richer, smoother, and more helpful.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363660.