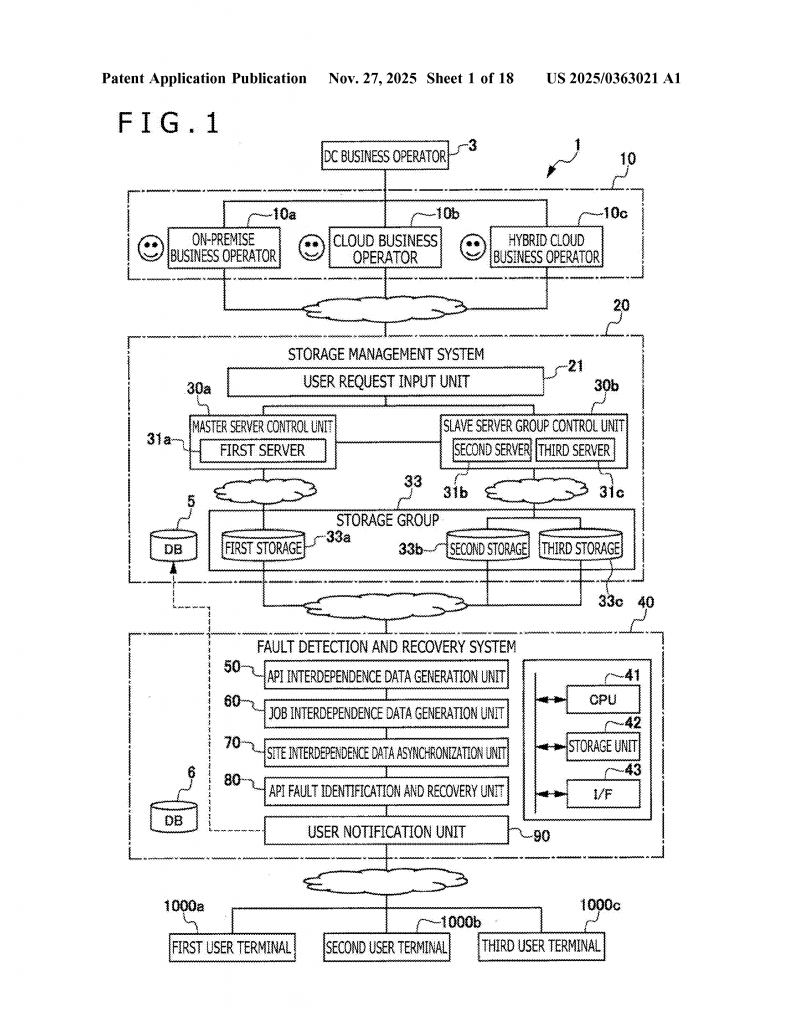
Invented by SUN; Jingtao, KANEKO; Satoshi, Hitachi Vantara, Ltd.
In today’s world, data is everywhere. More and more, companies rely on storing their data not just in one place, but in many places at the same time. This is especially true when businesses use both their own computers and cloud services together—a setup called a hybrid cloud. Managing all this storage can be tricky, especially when something goes wrong. Let’s look closely at a new patent application that brings a smart way to manage storage across many sites, helping companies find and fix problems faster and easier.
Background and Market Context
Think about how much information is being created every second. From photos and videos to documents and business records, it all needs to be kept safe. For a long time, companies stored their data in one place—usually in their own buildings, on their own machines. But now, cloud computing has changed the rules. Businesses often use both their own storage and space they rent in the cloud, mixing and matching to fit their needs. This is what we call a hybrid cloud.
But while using many storage sites gives more flexibility, it also makes things more complicated. Each storage place might have its own way of working, its own rules, and its own way to talk to other computers. So, companies need special systems to manage all these different parts together. These systems use what are called “APIs”—which just means a set of rules for how computers and programs talk to each other.
Usually, there are two kinds of APIs in these setups. The first kind, called low-level APIs, are designed for each storage site. They know all the details about how that one place works. The second kind, called high-level APIs, sit on top and try to control many low-level APIs at once, giving the company a single way to manage everything.
That sounds great, but what happens when something goes wrong? Maybe there’s a problem copying data from one place to another, or a piece of storage stops working. In those situations, the high-level API often doesn’t know exactly what happened or where the problem started. That makes it hard to find the problem and fix it quickly. Even though there are some ways to “roll back” or undo changes if something fails, these don’t always work well in complex setups where lots of different APIs are involved and where their relationships aren’t clear.
Companies today need better tools to handle these problems. They want to know right away when something goes wrong, where it happened, and how to fix it. This is especially important as data and storage keep growing, and as businesses rely even more on being able to move and protect information across many places at once. The new patent application we are exploring steps into this exact space, offering a smarter way to manage and recover from storage faults in hybrid cloud settings.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at how things have worked so far. When companies use many different storage systems, each with its own API, it’s like having different kinds of locks and keys for every door in a big building. The high-level API is like a master key, but if one door won’t open, it’s not always clear why. Maybe the lock is jammed, or maybe the key doesn’t fit anymore. Without knowing the details of each lock, the master key holder is left guessing.
Old systems tried to help by keeping some records of what actions were taken. If a problem happened, they could sometimes “roll back” or undo the last few steps. For example, if copying a file failed, they would try to put everything back the way it was before. This is helpful, but only if the system knows exactly which steps depend on each other, and only if the system can track which jobs were running and how they connect.
An example of earlier work is described in a patent called JP-2015-170344-A. This earlier patent talked about managing virtual resource groups and using rollbacks to fix failures. But, the problem with these older solutions is that they didn’t really understand or record how all the different APIs and jobs depend on each other in real time. When you have many storage sites and many jobs happening at once, it’s easy to lose track.
Let’s say a company is copying data from its own storage to the cloud and also from one cloud to another, all at the same time. If something goes wrong in the middle, the high-level API might not know which specific job or which storage place caused the problem. The links between the jobs—the “interdependence”—are not clear. Without that, the system just doesn’t have the full story.
This lack of clear connections makes error handling slow and risky. Sometimes, the system might try to fix the wrong problem or might even make things worse by rolling back too much or too little. In the end, business operations get delayed, users get frustrated, and data can be lost or left in a strange state.
That’s why the scientific rationale for this new patent is so strong. It builds a way for the system to watch and record, step by step, how each API and each job depends on others. When a problem happens, the system can look up these records and quickly find out exactly which job failed, where it happened, and how that job is connected to others. It’s like having a map of all the doors, keys, and locks, so you always know where to look when something breaks.
By making these relationships clear and easy to track, the new invention offers a more reliable way to find and fix faults—even in the most complicated hybrid cloud environments. It moves beyond just rolling back blindly, instead giving the system a real understanding of what’s happening, so recovery can be fast and accurate.
Invention Description and Key Innovations
Now, let’s open the hood and see how this new storage management system works. This invention is all about keeping track of how different storage jobs and their APIs are connected, and using that information to find and fix problems quickly.
At the center of the system is a smart brain that manages both low-level APIs for each storage site and a high-level API that controls everything together. When a job is started—like copying data from one site to another—the system carefully records how this job depends on the APIs involved and on other jobs. This is called generating “interdependence data.”
Here’s how it works in simple terms:
Whenever a job is started by the high-level API, the system uses special units that record two kinds of information. First, it writes down which APIs are being used and how they are linked together. For example, if copying data from Site A to Site B depends on both sites’ APIs, this link is noted. Second, when a job finishes successfully, it records “meta data” about how that job connects to other jobs—like if the next step depends on this one finishing first.
But the real magic happens when something goes wrong. If the high-level API can’t finish a job, the system doesn’t just throw up its hands. Instead, it uses the records it has built—the “interdependence data”—to trace back exactly which low-level API or job caused the problem. It’s like a detective following clues to the exact spot where things went off track.
If the system notices that a job failed, it checks to see if an automatic rollback is possible. If it is, the system stops the failed job and tries to reset everything to the last safe point. If not, the system looks at the job’s connections and tries to recover by retrying the job or another related job, depending on what the records show. This means that recovery is not random—it’s smart and targeted.
The system can also keep the user informed. Whenever a fault is found and as recovery steps are taken, the system sends clear notifications explaining what went wrong, where, and what is being done to fix it. This gives users confidence and keeps business running smoothly.
Let’s walk through a simple example. Imagine you have three storage sites: Site A, Site B, and Site C. You want to copy data from A to B and also from B to C. If the copy from A to B fails, the system knows that the copy from B to C depends on the first copy finishing. So, it can tell you that the second job can’t start until the first one is fixed. If the system can roll back the failed copy, it does so and tries again. If not, it tells you exactly what happened and what needs to be done next.
Another key innovation is that the system can work whether all sites are in the cloud, all on company premises, or a mix of both. This makes it flexible and future-proof, ready for any setup a company might use.
The system’s building blocks include:
– Units that generate and update interdependence data as jobs are started and finished
– A fault identification unit that uses the interdependence records to find out exactly where and why a fault happened
– A recovery unit that can roll back or retry jobs based on the actual links between tasks
– A notification unit that keeps users in the loop with clear, detailed updates
All of this is built on simple but powerful ideas: watch what’s happening, write down the links, and use those notes to solve problems fast. Unlike older systems that just hoped for the best, this new approach gives companies real control over their storage, even when things get complicated.
Conclusion
As businesses rely more on hybrid cloud storage, being able to manage, monitor, and recover from errors quickly is more important than ever. The patent application we explored brings a fresh, practical solution to this challenge. By carefully tracking how jobs and APIs depend on each other, and by using that information to pinpoint and fix faults, this system stands out from the crowd.
It doesn’t matter if a company is using all cloud, all on-premise, or a mix—the system adapts. It makes sure users are always informed, and it keeps data safe and business running smoothly. For anyone working in IT, cloud management, or data storage, understanding and applying the ideas in this invention can make a real difference in reliability, speed, and peace of mind.
In short, this is a big step forward in making complex storage setups safer, smarter, and easier to use.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363021.