
Invented by Lee; Jinhyuk, Dai; Zhuyun, Duddu; Sai Meher Karthik, Lei; Tao, Naim; Iftekhar, Chang; Ming-Wei, Zhao; Yuzhe
Finding the right document from a huge collection can be very hard. Today, we will break down a new patent application that uses neural networks to make this process much faster and more accurate. We will explain the market background, the science behind earlier solutions, and then show how this new invention changes the game.

Background and Market Context
Imagine searching for something on the internet. You type a question or a few words, and in seconds, you get a list of web pages, articles, or pictures that match. Behind this simple action, there are huge computer systems working very hard to find the best results for you. These systems handle millions, sometimes billions, of documents. Search engines, digital libraries, and even apps like voice assistants all need to pick the most relevant documents for any query.
People expect results to be fast and accurate. If they do not find what they want quickly, they might stop using the service. For companies, this means that smarter and quicker document retrieval is not just a technical challenge but a business need. The faster and more accurate the results, the happier the users and the better the business.
The demand for smart document search is growing. As more data is created every day, the need for improved search keeps rising. This is especially true as data is no longer just text—it can be images, videos, audio, or even a mix of these. Systems must adapt to handle this variety while keeping results both fast and useful.
Traditional ways of searching relied on matching words in the query to words in the documents. These systems worked, but as data grew, they became slow and often missed important connections. For example, searching for “dog training tips” might not show you a helpful article titled “Teaching Your Puppy Tricks.” The words are different, but the meaning is similar. Newer systems use advanced technology to understand the meaning behind words, not just the words themselves. This is where machine learning and neural networks come into play.

Big companies and small startups are racing to make search smarter and quicker. Cloud services, e-commerce shops, and social networks all want their users to find what they need instantly. If a system can handle more data, work faster, and give better answers, it can lead the market.
This patent application addresses these exact needs. It introduces a system that uses neural networks to process both queries and documents. Instead of looking at entire documents or simple words, it breaks everything down into smaller pieces called token vectors. These are like tiny building blocks that capture the meaning of words, sentences, or even parts of images or audio. The system then compares these blocks in a smart way, only focusing on the most useful ones, to deliver fast and accurate search results.
In summary, the market is hungry for better search and retrieval solutions. The new system described in this patent is designed to meet these demands by using the latest in machine learning to make searching smarter, faster, and more scalable.
Scientific Rationale and Prior Art
To really understand why this new system is special, we need to look at how earlier systems worked and what problems they faced.
Traditional search engines started with simple word matching. When you typed a word, the system looked for documents with the same word. This is called “keyword search.” It worked for basic needs but missed the deeper meaning of queries. For example, searching for “bicycle repair” would not find helpful articles about “fixing a flat tire on a bike.” The words are different, but the intent is the same.
To fix this, computer scientists started using models that could better understand the meaning behind words. They created “embeddings,” which are numerical representations of words or phrases. Think of it as turning every word into a unique point in a big space. Words with similar meanings are close together in this space. This approach worked better but still had limits, especially with longer texts or more complex queries.
As machine learning improved, neural networks became popular for search. Neural networks can learn patterns and relationships in data, making them perfect for understanding both queries and documents. Some systems used “dual encoders,” where one neural network processed the query and another processed the documents. Both turned their input into embeddings, and the system matched the query embedding with the document embeddings using similarity measures like cosine similarity or dot product.
However, these systems often looked at the entire document as one big block. They missed important details that might be hidden in a sentence or a specific part of the document. To solve this, newer methods started breaking documents into smaller pieces, called tokens. Each token (which could be a word, a word part, or even a piece of an image) was turned into its own embedding—a token vector.
Now, some advanced systems began looking at how each query token interacted with every document token. This made the matching much more expressive and could find deeper relationships. But there was a big problem: this approach required a huge amount of computer power and memory. Imagine having to compare every word in your question with every word in a million documents. It’s very slow and expensive, especially as data grows.
Some known models, like BERT, T5, and ColBERT, used these ideas. They achieved high accuracy by capturing token-level interactions but often at a very high computational cost. For example, ColBERT matched every query token with all document tokens and scored documents based on the best matches. This provided good results but was hard to scale in real-world settings where speed and efficiency are critical.
There were also attempts to balance speed and accuracy by using tricks like approximate nearest neighbor search, hashing, or pruning less important tokens. While these helped, they didn’t fully solve the problem of high resource use.
The result was a tradeoff: you could have fast search with less detail (and possibly less accuracy), or you could have slow, resource-heavy search with more detail. The market needed a solution that could do both—be fast and accurate, even as data grew larger and more complex.
This is the scientific landscape the new patent enters. It aims to keep the rich, expressive matching of token-level systems but solve the problem of speed and efficiency by cleverly limiting which token comparisons are made.
Invention Description and Key Innovations
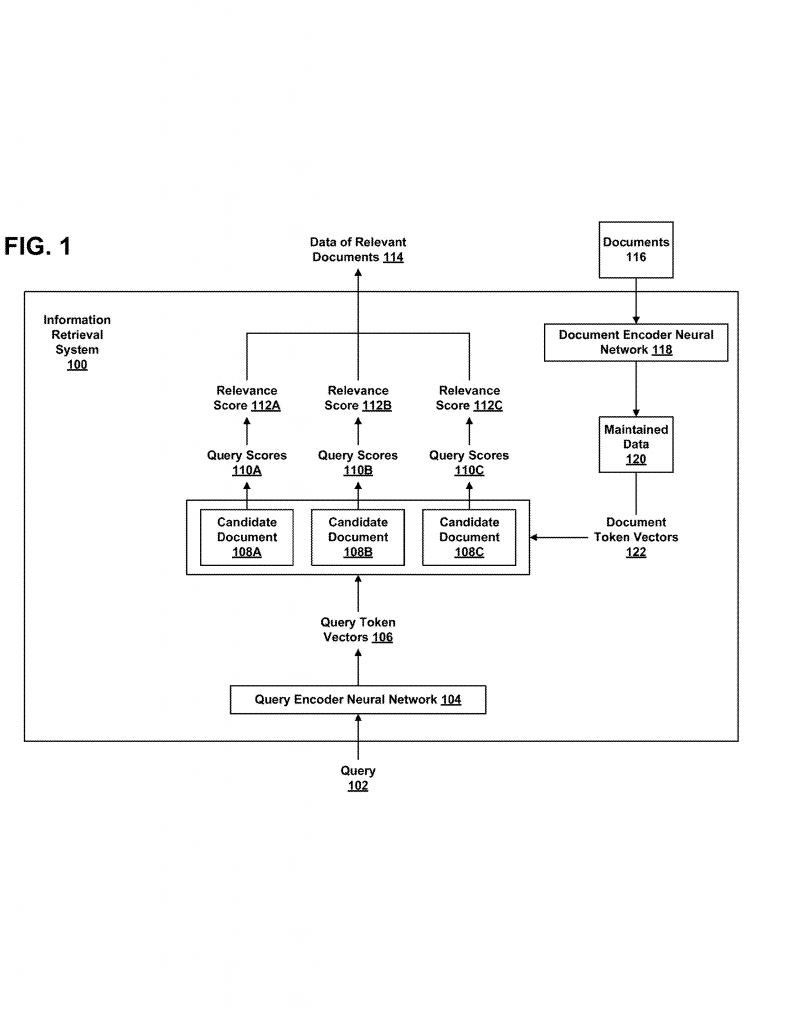
This invention is about a new and efficient way to find documents that match a user’s query using neural networks and token vectors. Let’s walk through how it works in simple words.
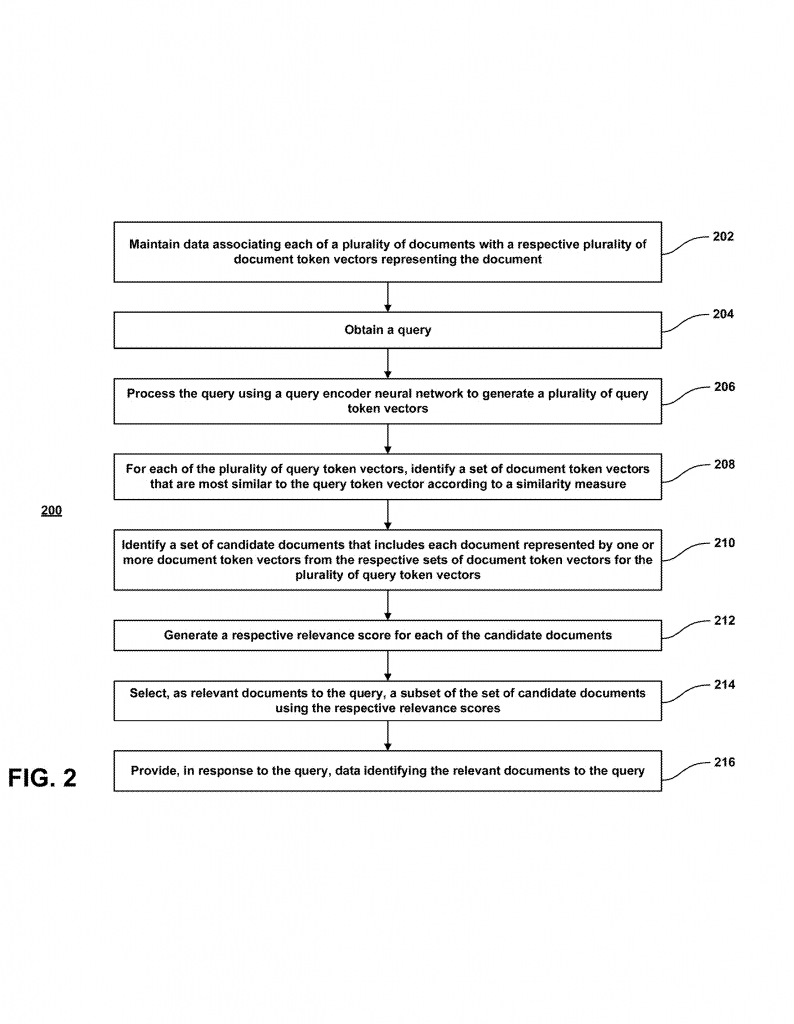
The system starts by processing every document and every query through neural networks called “encoders.” These encoders break down the text, image, or audio into smaller pieces called tokens. Each token gets turned into a vector, which is just a list of numbers that captures its meaning. For a document, you get many document token vectors. For a query, you get several query token vectors.
When a user enters a query, the system uses the query encoder to turn the query into a series of token vectors. Each of these vectors represents a part of the query’s meaning. At the same time, all the documents in the collection have already been processed into their own token vectors, and these are stored in a database or index for fast access.
Here’s the smart part: instead of comparing every query token to every document token (which is very slow and uses a lot of memory), the system does something more efficient. For each query token vector, it only looks for the document token vectors that are most similar to it. Similarity is measured using something like cosine similarity—think of it as measuring how close two points are in the vector space.
By focusing only on the most similar document token vectors for each query token, the system quickly narrows down the list of possible matching documents, called “candidate documents.” This is much faster than checking every possible pair. The candidate documents are those where at least one document token vector is among the most similar to at least one query token vector.
Next, the system scores how relevant each candidate document is. For every query token, it checks if any token from the candidate document is among the closest matches. If yes, it uses the highest similarity value as the score for that token. If not, it uses a fallback value called an “imputed value” (which could be zero or the lowest similarity in the set). This way, every query token gets a score for each candidate document, even if there isn’t a close match.
All the scores for a document are then combined, usually by averaging them, to get a final relevance score for that candidate document. The system then picks the top-scoring documents and returns them as the best matches for the query.
Training the system is also clever. It uses batches of queries and documents, marking some as relevant and others as irrelevant. The neural networks are trained to produce token vectors that help the system find relevant documents more accurately and efficiently. During training, if a candidate document has no close token matches, its score is set to zero, which helps the model learn to focus on real matches.
This approach has several key innovations:
First, it only uses the token vectors that are actually retrieved as close matches, not all token vectors from all documents. This saves a huge amount of computation and memory, making it possible to scale to very large collections.
Second, by focusing on token-level matching but limiting the number of comparisons, it keeps the rich, detailed understanding of the query and documents without the slowdown of previous systems.
Third, the use of imputed values for missing matches prevents relevance scores from being unfairly skewed when a document just happens to not have a close match for a token.
Fourth, the system can work with many types of data, not just text. It can handle images, audio, or combinations of data types, as long as the encoder can turn them into token vectors.
Finally, the system is designed for both speed and accuracy. Tests show that it can match or even beat the accuracy of older, slower systems while being much more efficient—sometimes using thousands of times less computation.
This invention is a big step forward for search systems. It makes it possible to build smarter, faster, and more scalable document retrieval tools that can keep up with the growing demands of users and businesses.
Conclusion
In today’s world, finding the right information is more important than ever. As data keeps growing, the systems that help us search and retrieve documents must get better. This patent application introduces a new way to use neural networks and token vectors to make document retrieval both fast and accurate. By focusing only on the most similar token vectors, it avoids the heavy computation of earlier systems while still capturing deep connections between queries and documents. This means users get better results, faster, and businesses can scale their search systems with less cost and more performance. As the market continues to demand smarter and quicker search, inventions like this will lead the way forward.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217373.