Invented by WU; Ming, YU; Zhiguo, REDFORD; Elizabeth Sarah, LAI MILLER; Ivy

Let’s talk about something that matters to anyone who writes or works with software code: how we make sure code tools powered by AI keep getting better, not worse. There’s a new patent application that tries to solve a big problem in this space. If you work in software, care about AI, or want to understand how new inventions shape the tools we use every day, this article will give you a deep dive—without fancy words or tech-heavy jargon. We’ll explore the background, the science behind it, and finally, what’s truly new about this invention.
Background and Market Context
AI is changing how we write code. Tools like GitHub Copilot, Codeium, and others use very big models called large language models (LLMs). These models help programmers write code faster, answer coding questions, and even suggest fixes when things go wrong. The dream is that these tools get smarter over time, making coding easier for everyone.
But there’s a challenge. Every time someone updates one of these tools—maybe with a new model or a better prompt—how do we know it’s actually better? If we update too quickly, a new version might not be as good as the last one. If we wait too long, we miss out on big improvements. So, companies use something called a “quality gate.” This is a set of checks or tests that decide if the update should go live.
When it comes to code tools, these checks need to be very smart. Imagine a tool that writes code for many languages and many types of tasks. It’s impossible for humans to check every possible update by hand. Even if we tried, we would need lots of expert programmers, and it would take too much time. The solution people use now is to let another AI model do the checking. But what if this “checker” AI isn’t as good as we hope? What if it’s too nice, letting bad updates pass through? Or maybe it’s too strict and blocks good updates?
This is not a small problem. If the checking system isn’t reliable, the tool might get worse over time, or not improve at all. Programmers then lose trust, and the market for these AI tools could slow down. In a world where everyone wants smarter, safer, and more helpful code tools, having a reliable way to judge updates is not just important—it’s essential. That’s why companies are racing to build better ways to test and approve AI updates.
This patent application is about a new way to do just that. It lays out a system that uses both AI and human help to make sure only good updates get through. It promises to scale—meaning it can work even as the tools get bigger and more complex—while still being robust, or reliable, even if the tasks change over time.

Scientific Rationale and Prior Art
Let’s look at what the science tells us about this problem and what others have tried before.
First, big language models are very good at some things, but not all things. Even if a model is trained to write code, that doesn’t mean it’s perfect at every programming job. Sometimes, a model might give the right answer for simple code, but make mistakes in more complex tasks. And if you use one model to check another, there’s a risk they share the same blind spots. If both models are trained on the same data, or have similar weaknesses, the “checker” could miss mistakes.
Earlier systems to check code intelligence tools use two main methods. One is “reference-based,” where you compare the output of the tool to a set of perfect answers. This works well when you have a small, well-defined set of tasks. But as soon as you want to cover all the ways people use code tools, you need thousands—maybe millions—of reference answers. It becomes impossible to keep up.
The other method is “model-based.” Here, an AI model checks the work of another AI. This is fast and can handle lots of code, but there’s a risk. The checker model might rate things too high or too low, especially if it has learned from similar data as the tool it’s checking. This is called “pro-machine bias”—the checker is too friendly to the code tool, giving it better scores than it really deserves.
Why does this matter? Because if we let underperforming updates go through, the code tool gets worse and users get frustrated. If we block every update, we never improve. So, the challenge is to find a system that can scale to lots of updates, but also be accurate and fair.
Some companies have tried to solve this by mixing human checks and AI checks. Humans are very good at judging things like whether code is helpful, correct, and complete. But humans can’t check every update for every possible programming task. So, the best systems try to get the most out of human expertise, using it where it matters most, and letting AI handle the rest.
This is where the idea of “hierarchical criteria” comes in. Rather than just asking, “Is this code good?” these systems check for things like relevance (does the code answer the question?), truth (is it correct?), and completeness (does it cover everything needed?). By breaking down quality into smaller parts, we can judge AI updates more fairly and spot problems faster.
Before this patent, there were systems that used some of these ideas. Some tools let users rate answers with thumbs up or down. Others collect feedback from programmers in surveys. But none really combine all these pieces—AI checking, human feedback, detailed quality scores, and the ability to tune the checker itself if it’s not working right—in a way that scales to big, fast-changing code tools.
This patent application builds on all these lessons. It proposes a way to use a “two-tier” system: one AI evaluates the code tool, and another system (which can involve humans) checks the evaluator itself, tuning it as needed. The goal is to let human skill guide the process, but only where it makes the biggest difference, letting AI do the heavy lifting so updates can flow quickly and safely.
Invention Description and Key Innovations
Let’s break down how this new invention works and what makes it stand out. Remember, the goal is to make sure only good updates get into code intelligence tools, and to do this in a way that is both fast and reliable.
The system has a few main parts:
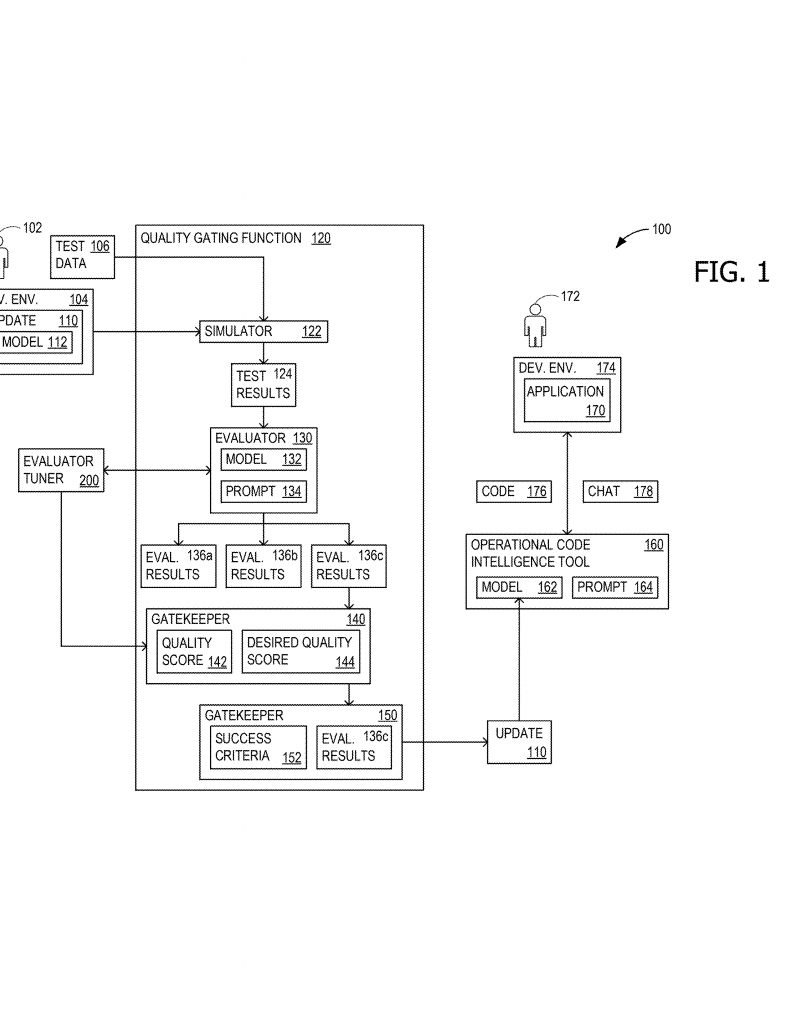
First, there’s the “quality gating function.” This is a set of software and instructions that receives a proposed update to the code intelligence tool. Think of it as the gatekeeper—it decides if the update can pass.
When a new update is ready, the quality gating function runs it on a big set of test data. This data covers many different coding tasks, to make sure the update is tested in lots of real-world situations. The results are called “test results.”

Next, an “evaluator” checks these test results. The evaluator is made of two parts: an evaluation model (an AI or machine learning model) and an evaluation prompt (the instructions or questions given to the model). The evaluator gives scores to the test results, producing what are called “evaluation results.”
But the process doesn’t stop there. The system also includes something called a “hierarchical quality criteria structure.” This is a way to judge quality using three big ideas: relevance (does the answer fit the question?), truth (is it correct?), and completeness (does it cover everything needed?). Each evaluation result is rated separately for these three things. This gives a more detailed picture of how good the update really is.
The system then gives the evaluator a “quality score” based on these detailed ratings. If the quality score isn’t high enough, the evaluator itself gets tuned. This means the people who run the system (or another AI) can adjust the evaluation model, the prompt, or both. They might change how the model is trained, or how it is asked to judge answers. The tuning keeps going—testing, scoring, tuning—until the evaluator is doing a good job, as shown by the quality score meeting a set goal.
The system uses real feedback to tune itself. It can use annotations from humans, data from user surveys (like thumbs up or down), and even compare the results to “ground truth” answers when possible. All this feedback helps the system know if it’s making the right choices.
Once the evaluator is tuned and the quality score is high enough, the system checks if the update to the code tool meets the “success criteria.” If it does, the update is approved and goes live. If not, it’s sent back for more work.
Here’s what makes this invention special:
It doesn’t rely on just one method to judge updates. It uses a mix of AI and human feedback, and it tunes the checking system itself whenever it starts to drift. This keeps the process honest and fair, even as the code tools and tasks keep changing.
By breaking down quality into smaller parts—relevance, truth, and completeness—it can spot problems that other systems might miss. And by letting humans focus only on tuning the evaluator (instead of checking every update), it scales to the huge number of updates and tests needed for modern code tools.
The invention can work for code completion, chat services about code, and other smart programming helpers. It can be used by any company that wants to keep its AI code tools sharp and reliable, while moving fast and keeping up with the market.
All of this is described in a system that can run on regular computers, in the cloud, or across many devices. It doesn’t need special hardware, and it can be adapted to fit different kinds of programming tools.
In simple terms, this invention is like a smart, learning gatekeeper. It watches over every update to your code tool, making sure only the best ones get through. It learns from every test, every user, and every bit of feedback, getting better all the time.
Conclusion
AI-powered code tools are here to stay, but making sure they keep improving is a real challenge. This patent application lays out a way to use both AI and human skill to judge every update, making the process fast, fair, and reliable. By focusing on detailed quality checks and by letting the evaluator be tuned and improved, the system sets a new standard for how we manage updates to code intelligence tools.
For software companies, this means safer, better tools that programmers can trust. For users, it means smarter suggestions, fewer bugs, and a better coding experience. As code tools become more important to every part of our digital world, having a system like this is not just smart—it’s essential.
If you want your code tools to keep getting better, or if you build tools that others rely on, understanding and using systems like the one in this patent could be your key to staying ahead.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335161.