Invented by Galvin; Brian
In this article, we’ll break down and explain a new patent application for a deep learning system that handles real-time time series forecasting using a compound large codeword model. We’ll keep things simple, clear, and practical. Let’s see how this technology fits into the world, why it was needed, and what’s unique about it.
Background and Market Context
Every day, we are surrounded by data that comes in waves over time: stock prices, weather changes, website visitors, sensor readings, and even the number of steps you take. This type of data is called time series data. Many industries, like finance, healthcare, energy, and retail, rely on making quick and accurate predictions from this data. The faster and more precise the forecasts, the better decisions they can make.
Traditionally, forecasting time series data required a lot of hard work, rules, and manual tuning. Tools like ARIMA or even early neural networks could not always keep up with the complex, fast-moving, and mixed nature of real-world data. The big leap came with deep learning—a way for computers to learn patterns from massive amounts of data, often beating human experts.
The most popular deep learning tools for text and language are called Transformers. They power chatbots, translation apps, and content generators. But when it comes to other kinds of data, like numbers, images, or combining data from many sources (say, stock prices and news headlines), Transformers can struggle. They need a lot of memory, are slow with big data, and often lose track of important relationships when the data isn’t just text.
The market now needs smarter, more efficient, and more flexible forecasting systems. Businesses want to mix data from different sources—like blending weather reports with sales numbers—to make better predictions. They want these systems to adapt on-the-fly as new data streams in, without having to stop and retrain everything.
That’s where the invention described in this patent comes in. It promises to be faster, more accurate, and more adaptable than old methods. It does this by using compact codewords to represent data, combining ideas from the latest deep learning research, and allowing the system to update itself as it learns. This is a big deal for anyone who relies on real-time data forecasting.
Scientific Rationale and Prior Art
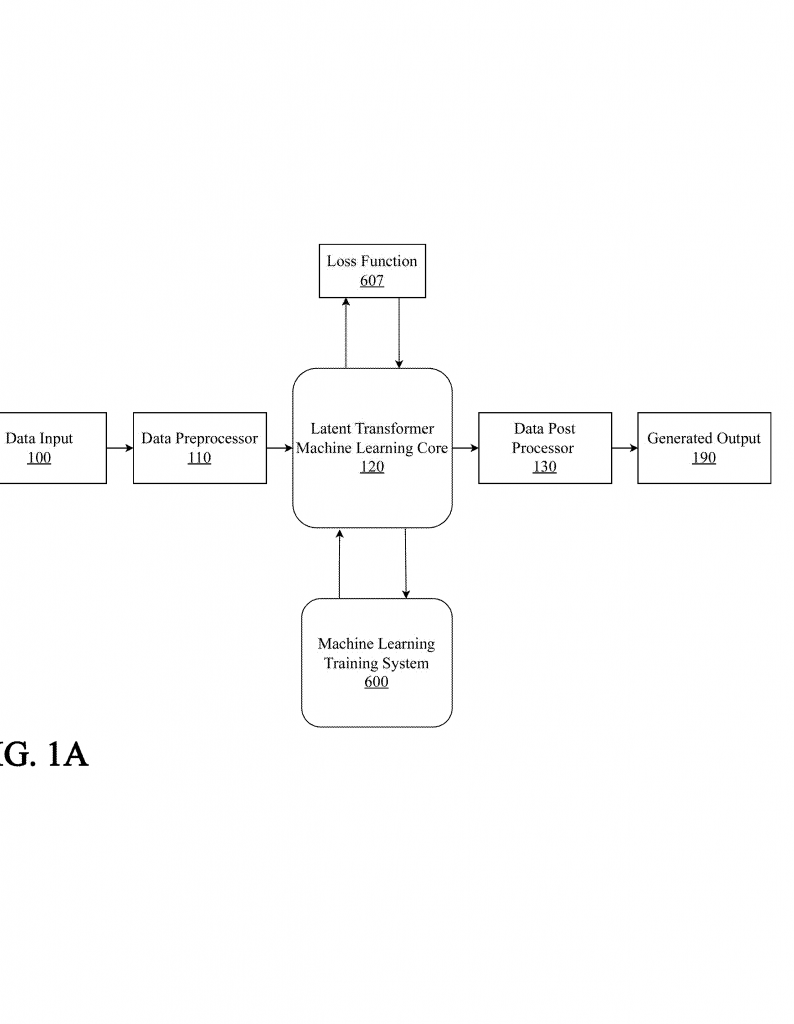
Let’s take a step back and look at the science behind this invention. For years, deep learning models have used something called embeddings—dense, high-dimensional vectors—to represent words, images, or numbers in a way that computers can understand. Transformers, for example, take text, break it into tokens, turn those tokens into vectors, and then process them to find patterns.
But this approach has some problems:
- It eats up a lot of memory and computing power, especially for very large models.
- It isn’t great at handling different types of data at once (like mixing text and numbers).
- It can’t easily adapt to new or changing data without restarting the training process.
Scientists and engineers have tried several ways to improve this. Some used Variational Autoencoders (VAEs), which compress data into a “latent space”—a smaller, smarter way to represent key features of the data. Others experimented with codebooks—collections of short codes or “codewords” that stand in for bigger chunks of information. This is similar to how Morse code uses dots and dashes for words and letters.
People have also explored adaptive systems that can change their structure as they learn, but most attempts so far either slowed things down or made the models too unstable.
The prior art includes:
- Standard Transformer models that use dense embeddings and positional encodings.
- Autoencoders and VAEs for compressing and reconstructing data.
- Basic codebook methods for data compression, but not for real-time learning or forecasting.
- Simple neural network pruning or expansion, but without smart, real-time supervision.
None of these earlier approaches fully solved the main problems: being able to mix many data types, handle them efficiently, and adapt continuously as the world changes—all while making fast, accurate predictions in real time.
Invention Description and Key Innovations
Now, let’s dig into what makes this invention special. The system described in the patent is built to process real-time time series data from many sources, blending different types of information (like numbers, text, and more) to make the best possible forecasts. Here’s how it works, step by step, using clear language.
1. Receiving and Preparing Data
The system starts by receiving data from multiple sources. Imagine it as a smart hub that gets price data, news articles, sensor readings, and more—all streaming in at once.
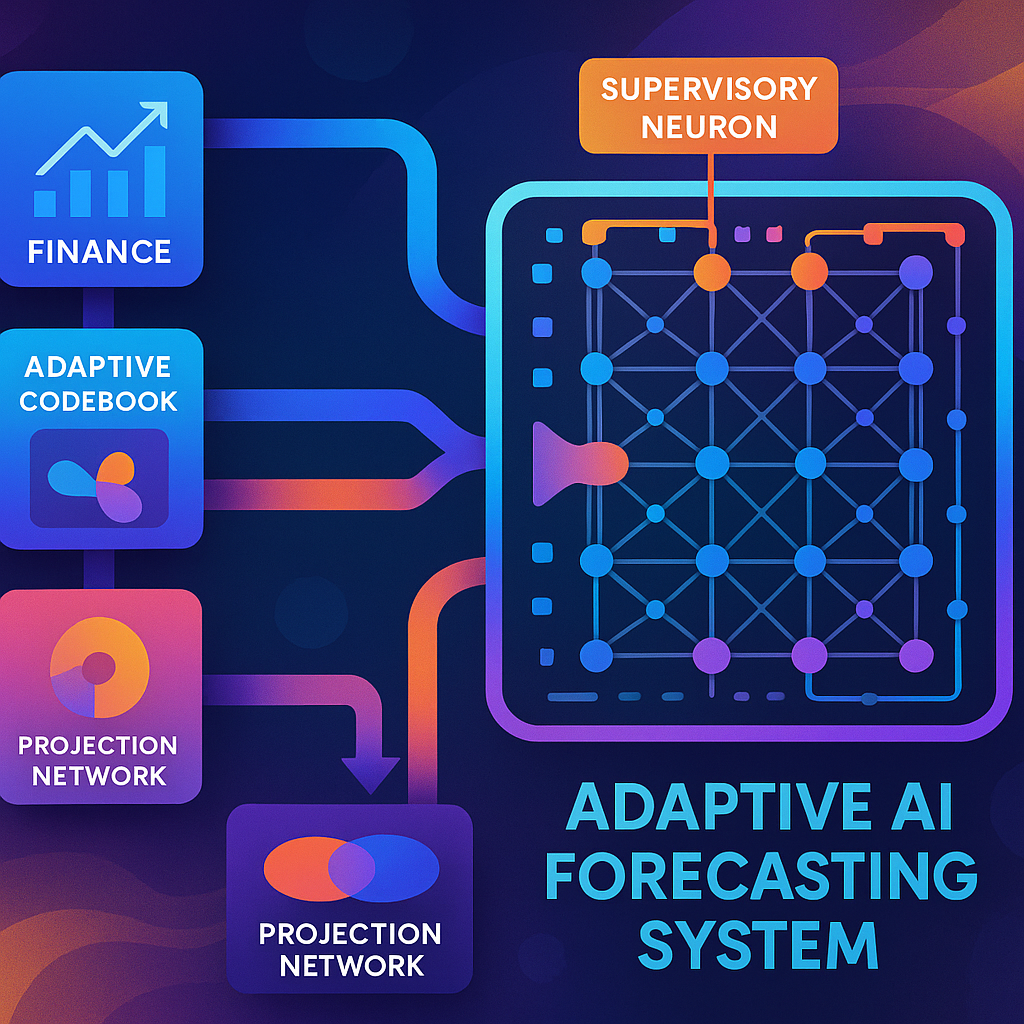
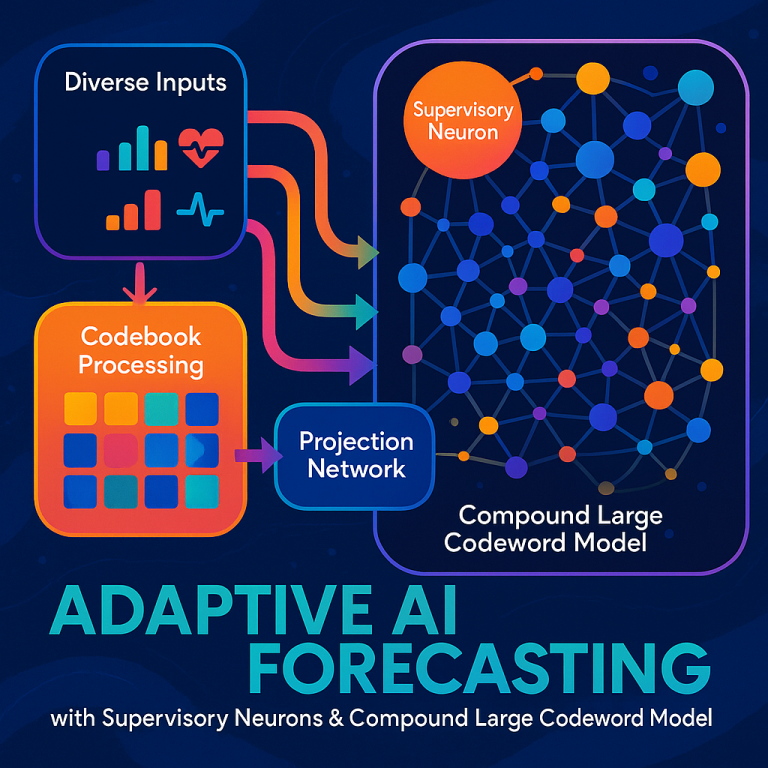
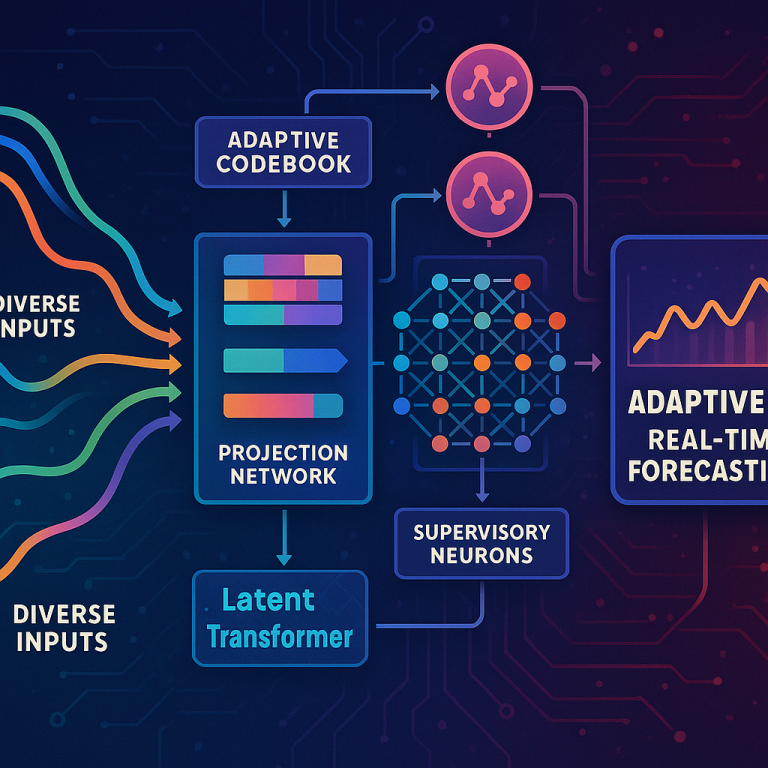
Each data type (for example, text or numbers) is handled by its own adaptive codebook. This is like having a special dictionary for each type of data, where each “word” or “unit” in the incoming data gets converted into a short, unique codeword. These codebooks can update themselves as new data patterns appear, so the system never gets out of date.
2. Fusing Codewords and Creating Unified Representations
Once all the data is turned into codewords, the system uses a projection network to blend them together. This projection network is designed to combine codewords from different sources while keeping their relationships intact. Think of it as mixing ingredients to make a cake while still being able to taste each flavor.
The result is a single, unified codeword representation that captures all the important connections between the original data sources.
3. Deep Learning Core: The Latent Transformer
This unified codeword is fed into the system’s machine learning core, which is a modified Transformer. But unlike normal Transformers, this one doesn’t use heavy embedding or positional encoding layers. Instead, it works directly on the compact codeword representations, making it faster and more efficient.
The machine learning core is organized into small regions, each with its own set of operational neurons (the workers) and a supervisory neuron (the manager). The operational neurons process the data and make predictions, while the supervisory neuron watches over them, collecting information about what’s happening.
4. Supervisory Neurons: Real-Time Adaptation and Optimization
Here’s where it gets really interesting. The supervisory neurons are like tiny coaches embedded in the network. They monitor the activity of the operational neurons—tracking things like which ones are busy, their input and output levels, and how they change over time.
The supervisory neurons use advanced analysis (like Fourier transforms and wavelet analysis) to spot patterns and trends. If they notice something is off—like a group of neurons becoming less useful—they can:
- Prune (remove) underused neurons
- Add new neurons (neurogenesis) to handle new patterns
- Change how neurons are connected
- Tweak weights and biases for better performance
All these changes happen smoothly and in real time, so the system keeps running without interruption. If a change doesn’t make things better, the supervisory neuron can roll it back. This feedback loop keeps the network sharp and responsive.
5. Forecasting and Output
With all these moving parts, the system can generate short-term forecasts based on the latest codeword representations. These forecasts are updated continuously as new data arrives. The output is a live, rolling prediction of what’s likely to happen next—be it stock prices, weather, or any other time series.
Because the system is always updating its codebooks and network structure, it stays accurate even as data patterns shift—something traditional models can’t do without retraining.
6. Continuous Learning and Scalability
One of the biggest strengths of this approach is its ability to scale up and handle new situations. Multiple supervisory neurons can communicate with each other, sharing what they’ve learned to coordinate changes across the whole system. This means the model can grow bigger, cover more data sources, and adapt to new tasks—without slowing down or losing accuracy.
The adaptive codebooks also ensure that the system compresses data efficiently, so it doesn’t get bogged down by unnecessary information. Everything is designed to work together in real time, making it suitable for fast-moving markets, industrial monitoring, and other dynamic environments.
7. Practical Applications and Benefits
This technology isn’t limited to finance or weather. It can be used for:
- Energy grid management (blending sensor data and market signals)
- Online retail (predicting demand by mixing sales, social media, and traffic data)
- Healthcare (combining patient records, wearable data, and medical imaging)
- Cybersecurity (detecting threats by fusing logs, network flows, and alerts)
The result is a system that delivers more accurate forecasts, adapts to changing data, and saves both time and computing resources.
Conclusion
The patent for real-time time series forecasting with a compound large codeword model introduces a new way to handle complex, fast-changing data in the real world. By turning mixed data into compact codewords, fusing them smartly, and enabling the network to adapt itself live, this system is set to redefine what’s possible in forecasting applications. It brings together the best of deep learning, data compression, and adaptive control—delivering speed, accuracy, and flexibility in one package.
If your organization relies on real-time predictions, or if you’re building systems that need to mix and match many types of data, this technology could be a game changer. Stay tuned as it makes its way from patent to practice.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363347.