Invented by Saeedi; Ardavan, Venkataraman; Jagadish, Stremmel; Joel David, Hassanzadeh; Hamid Reza
Let’s jump right into a new way computers answer tough questions. This blog will walk you through a recent patent application that changes how machines find answers in big piles of text. You’ll learn why this matters, how it builds on what came before, and what is new and special about the invention. Let’s get started!
Background and Market Context
Today, people and businesses ask computers to answer all sorts of questions, from simple facts to tricky ones that need a lot of thought. Imagine a doctor looking for the right treatment in a stack of medical notes, or a lawyer searching for the right rule in hundreds of pages of law. The need for computers to help with these questions is growing fast. In banks, hospitals, factories, stores, and schools, everyone wants better answers, faster.
In the past, most computer systems used one big machine learning model to answer questions. These “monolithic” models could be good at one thing, like finding a fact or matching words, but they would often miss the mark on more complex questions. If a question needed several steps or types of thinking—like sorting events by time, handling “not” or “none” in the wording, or breaking down a big question into smaller ones—older systems started to fall apart. They might get lost in long documents, skip over important details, or mix up different types of information.
This is a real problem for businesses that need reliable, accurate answers. If a hospital system misses an important note in a patient’s record, it could make a wrong decision about care. If a bank fails to catch a key rule in a regulation, it might make a costly mistake. That’s why there is a big push for better question answering systems—ones that can handle more types of questions, work with different kinds of documents, and keep getting better over time.
The market for these systems is booming. Large companies and startups are investing in new tools for document search, compliance checking, clinical guidelines, and customer support. Artificial intelligence (AI) and machine learning are at the heart of these tools. But until now, most of them still relied on single, one-size-fits-all models that just aren’t flexible enough for the real world. Something needed to change. That’s where the invention in this patent comes in.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at what scientists and engineers tried before. Early on, question answering systems used simple keyword search. You typed in a word, and the computer looked for it in documents. This works for easy questions, but not for ones where the right answer uses different words, or when you need to understand the meaning behind the words.
Later, researchers built more advanced machine learning models. These models learned from lots of examples, so they could find answers even when the words didn’t match exactly. Some models used rules, some used statistics, and some used deep learning with neural networks. The biggest step forward came with large language models (LLMs) like BERT, GPT, and others. These models could read and understand long texts and answer questions in plain language.
But all these models had flaws. The big, all-in-one models could be very good at some tasks but bad at others. For example, one model might do well with direct questions but fail when a question needed understanding of time (like, “What happened first?”), or when the answer depended on saying “no” to certain things (“none of these apply”). They also had trouble breaking big questions into smaller parts and answering each one in turn. Plus, when you train one huge model, it’s hard to update or fix just one part if it starts making mistakes.
Some research tried to solve these problems by combining several models into a group, called an “ensemble.” Each model in the group focused on a different part of the problem. For example, one might match keywords, another might use deep learning to look for meaning, and another might check for specific patterns. The idea was that together, they could cover more ground than any one model alone.
But even these ensemble systems had their own problems. They often just took a simple vote to decide which answer was best, without thinking about how much to trust each model for each type of question. They didn’t have a smart way to weigh the different models’ answers, or to learn which models were best for which tasks. They also didn’t keep improving themselves as new kinds of questions came up. When new data or new question types appeared, the old ensembles could not keep up.
To sum up, the science so far gave us better and better models, but still left gaps. We needed a system that could use many models, pick the best one for each part of a problem, keep learning as it goes, and handle all the tricky details like time, negation, and question breakdown. The patent we’re looking at today steps in to fill these gaps with a dynamic, modular, and continuously learning approach.
Invention Description and Key Innovations
The invention described in this patent application is a new way to build question answering systems. Instead of one big model, it uses a group of smaller models, each focused on a different task. These models are combined in a smart way, using a special fusion model that learns how much to trust each part. The system can break down hard questions into smaller steps, find the best pieces of evidence in a set of documents, and put together the answer using the right kind of model for each situation.
Let’s walk through how it works, step by step, in very simple terms.
1. Getting Evidence from Documents
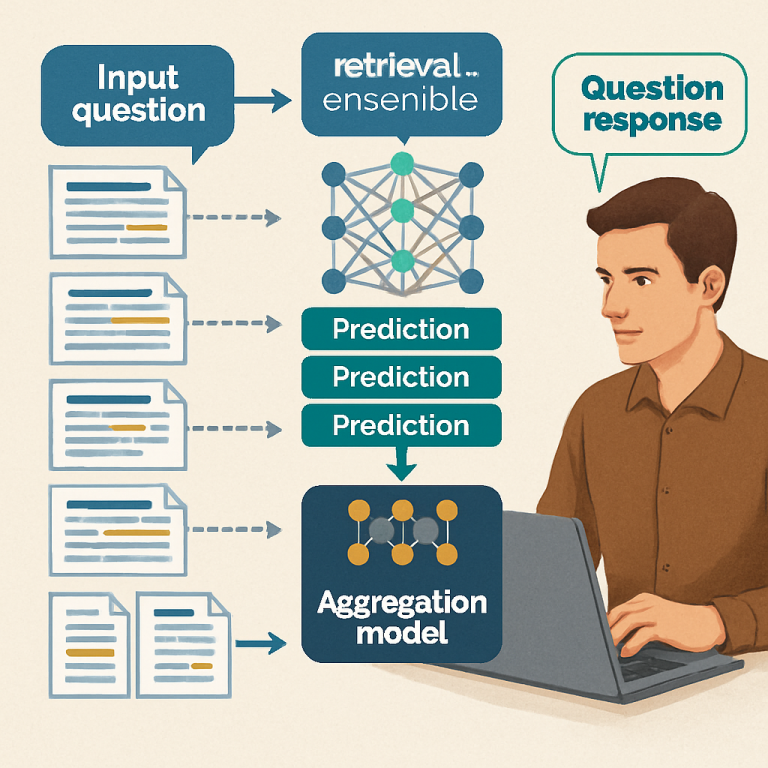
The system starts with an “input question” and a “document set.” The document set could be anything—a stack of medical notes, a bunch of legal files, a set of reports, or any collection of text. The system breaks these big documents into smaller pieces called “evidence passages.” Each passage is a chunk of text that might help answer the question.
2. Multiple Models Look at the Evidence
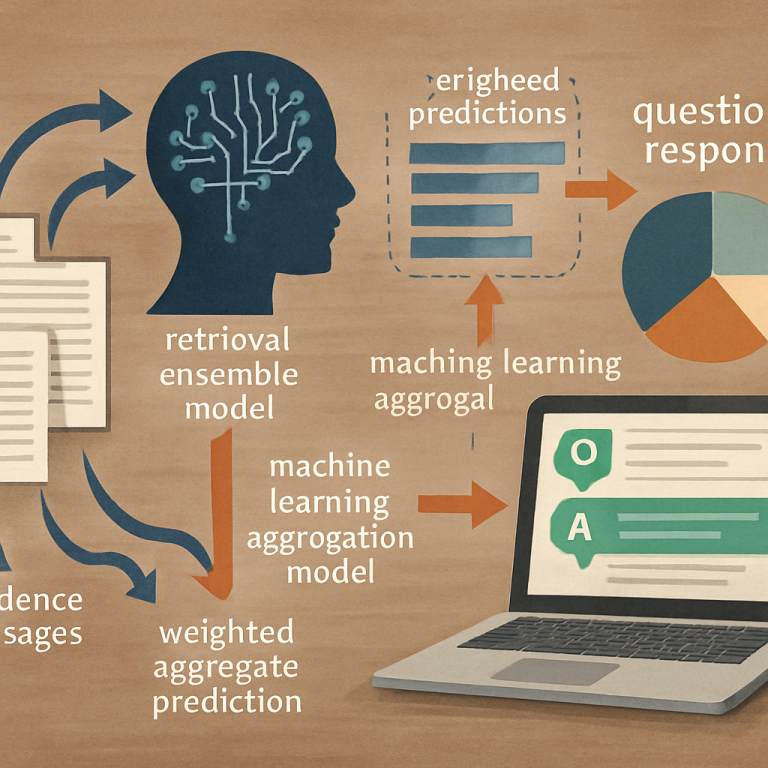
Now, the system uses several different machine learning models to look at each evidence passage and decide how well it matches the question. One model might be a simple keyword matcher—does the passage have the same words as the question? Another model might be a large language model that understands meaning. Others could be trained to look for time (when things happened), to handle “not” or “none” in the question, or to do other special tasks.
Each model gives a score (called an “evidence prediction”) for how much it thinks a passage is related to the question. For example, the keyword model might give a high score if the words match, while the language model might give a high score if the meaning matches, even if the words are different.
3. A Smart Fusion Model Combines the Scores
Here’s where the invention gets clever. Instead of just voting or averaging the scores, the system uses a “fusion model.” This is a special machine learning model that learns, from real examples, how much to trust each type of model for different questions. For example, for questions about when something happened, the system might learn to trust the temporal model more. For questions that have “not” or “none,” it might trust a model trained for negation more. The fusion model takes all the evidence predictions and produces a “weighted aggregate prediction”—a single score that reflects the best guess for that passage, based on all the models and their strengths.
4. Picking the Best Passages
The system uses the fusion model’s scores to pick the most likely passages from the document set. These are called the “set of input passages.” These are the chunks of text most likely to have the answer.
5. Routing to the Right Answer Model
Now, the system decides how to generate the answer. Different questions need different kinds of answers. Some questions want a “yes” or “no.” Some want a choice from a list. Others need a short phrase or a full sentence. The system uses a “routing module” to send the question and the best passages to the right kind of answer model. For example:
- If it’s a yes/no or multiple-choice question, it goes to an encoder-based model that’s good at picking the right choice.
- If it’s a question with many possible answers, it goes to a decoder-based model that can pick from a big set.
- If it’s a free-form question (“What is the reason for…?”), it goes to a generative model like GPT that can write out the answer.
6. Giving the Answer and Learning from Mistakes
The system gives back the answer, along with the passage that supports it. But it doesn’t stop there. It checks how well it did by comparing its answer to the correct one, using special “metrics” that measure accuracy. If the system gets something wrong, it uses another model to rewrite or create new training passages—this is called “synthetic data generation.” These new passages help the system learn from its errors and get better over time.
This whole process is modular, dynamic, and self-improving. The system can keep training itself, add new models for new kinds of questions, and get better as it handles more data. Because each part is separate but connected, you can fix or improve one piece without breaking the rest. This makes the system very flexible and robust.
Key Innovations:
– The use of multiple specialized models (for keywords, meaning, time, negation, and more) working together.
– A smart fusion model that learns how much to trust each model for each kind of question, based on real examples.
– A routing module that sends each question to the best answer model, depending on the type of answer needed.
– A self-improving loop that creates new training data when the system makes mistakes, helping it learn and adapt.
– The ability to handle complex, multi-step questions by breaking them into parts, finding evidence for each, and combining the results.
– Flexibility to work with different document types and domains, from healthcare to law to finance and beyond.
What does all this mean in practice? It means you can build question answering systems that work better and faster, even as the kinds of questions people ask keep changing. Instead of being stuck with a single model that struggles with new types of problems, you have a living system that keeps getting stronger and more accurate over time.
How This Can Help You
If you run a business that needs to find answers in big documents—whether it’s medical, legal, financial, or technical—this invention points the way to faster, more reliable, and more flexible answers. You can trust the system to pick the best tool for each job, handle tricky questions, and keep learning from its mistakes. You’ll spend less time searching and more time making smart decisions.
Conclusion
This patent application introduces a smarter, more flexible way for computers to answer tough questions. By breaking down the problem, using the best tool for each part, learning from its mistakes, and keeping all the pieces working together, this invention sets a new standard for question answering systems. Whether you work in healthcare, law, banking, or any field where good answers matter, this approach can save you time, reduce errors, and help you make better choices. As the world keeps asking harder questions, systems like this will be ready to answer them.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217403.