Invented by Ian C. Schick, Kevin Knight, Specifio Inc
In recent years, the field of machine learning has seen tremendous growth and development. This has led to the emergence of various applications and systems that utilize machine learning algorithms to automate and streamline various processes. One such application is the creation of patent specifications based on human-provided information.
The process of creating a patent specification can be complex and time-consuming. It involves analyzing and understanding the invention, conducting a thorough search of prior art, and drafting a detailed description of the invention. Traditionally, this process has been carried out by patent attorneys and experts in the field, who possess the necessary knowledge and expertise.
However, with the advancements in machine learning and rules-based algorithms, it is now possible to automate and expedite this process. Systems and methods have been developed that can analyze human-provided information and generate a patent specification based on this input.
These systems utilize machine learning algorithms to understand and interpret the information provided by the inventor. They can extract key concepts, identify relevant prior art, and generate a detailed description of the invention. By automating this process, these systems can significantly reduce the time and effort required to create a patent specification.
One of the key advantages of using machine learning and rules-based algorithms in this context is the ability to analyze vast amounts of data quickly and accurately. These algorithms can process and analyze large volumes of prior art, scientific literature, and technical documents to identify relevant information and generate a comprehensive patent specification.
Furthermore, these systems can also ensure consistency and accuracy in the patent specification drafting process. By following predefined rules and guidelines, they can eliminate errors and inconsistencies that may arise from human error or oversight. This can greatly enhance the quality and reliability of the patent specification.
Another benefit of using machine learning and rules-based algorithms is the potential for innovation and improvement. These systems can continuously learn and adapt based on feedback and new information. As more patent specifications are generated and analyzed, the algorithms can improve their accuracy and efficiency, leading to better results over time.
However, it is important to note that while these systems can automate and streamline the process of creating a patent specification, they are not intended to replace human expertise entirely. The input and guidance of patent attorneys and experts are still crucial in ensuring the accuracy and validity of the patent specification.
In conclusion, the market for systems and methods for using machine learning and rules-based algorithms to create a patent specification based on human-provided information is rapidly growing. These systems offer significant advantages in terms of time efficiency, accuracy, and consistency. While they cannot replace human expertise entirely, they can greatly enhance the patent specification drafting process and contribute to the overall efficiency of the patent system.

The Specifio Inc invention works as follows
The disclosures include “Systems and Methods for using rules-based algorithms and machine learning to create a Patent Specification based on patent claims provided by humans, such that the Patent Specification is created without any human intervention.” Examples of exemplary implementations include: obtaining a claim set, obtaining a first datastructure representing the claim, obtaining a second and third data structures, and determining one or more sections in the patent specification using the first, second, and third data structures.

Background for Systems and Methods for Using Machine Learning and Rules-Based Algorithms to Create a Patent Specification Based on Human-Provided Patent Claims such that the Patent Specification is created without Human Intervention
Patent applications are prepared by patent practitioners who hold a license. These professionals are either patent attorneys (scientists/engineers with a law degree) or patent agents (scientists/engineers without a law degree). A patent application, once prepared, is submitted to the United States Patent & Trademark Office. It is then examined by a Patent Examiner. Each application is either rejected or issued as a U.S. Patent. Patent.
A patent application consists of three parts: the claims, specification and figures. The claims consist of a list of sentences that define the invention in detail. The claims are a way to distinguish between what’s considered prior art (i.e. useful, new and non-obvious) and what’s considered inventive. The longest section is the specification. The specification explains the steps to be taken in order to create and use an invention. The figures complete the specification by illustrating the claimed features.
The profitability of patent preparation has declined for law firms due to several factors. It is more than ever the market forces that drive fees for preparing patents, not practitioner expertise and experience. This collision between market-rate fees and escalating hourly rate for practitioners leads to a climate in which only non-attorneys or entry-level practitioners are able to be profitable. Some major law firms view patent preparation as a way to get a job in licensing or litigation. A talent shortage is also emerging, as client demand for patent drafters continues to increase while the number new patent practitioners being minted every year tends downward.
Example implementations enhance law firm leverage using cutting-edge machine language and learning technologies. Some implementations allow for the automated generation of patent application drafts using concise practitioner inputs, such as claim sets or drawing figures. Now, practitioners can maximize their expertise and time by focusing only on key aspects of patent preparation and the client’s experience. Exemplary implementations take care of the rest in a near-instantaneous manner. The present disclosure, for example, was generated automatically without any human involvement, except for this paragraph and the background section, based on only a single set of method claims prepared by a Patent Practitioner.
One aspect of this disclosure is a system that provides a data structure for patent claims. The system can include one or multiple hardware processors that are configured using machine-readable instructions. The processor(s), if any, may be configured in order to generate a claim set. The claim set can include a list of sentences numbered that define the invention precisely. The claim set can include one independent claim and up to three dependent claims. The dependent claims in the claim set can be dependent on the independent claims by referring to either the independent claim, or an intervening claim. The processors may be configured to handle a claim-line of the claim set. The claim line can be a text unit whose end is indicated by the presence of one or several end-of-claim-line characters. The processors may be configured so that they identify one or multiple features of the claim line in order to store them in the data structure. One or more of the features can be either a main feature, or a sub-feature. The processors may be configured to save the one or multiple features in the datastructure. The main feature can be a claimable process step, a claimed article of manufacture or machine, or component of a composition of matter. The sub-feature may expand or describe an aspect of the main feature.
Another aspect relates to the present disclosure. It is a method of providing a datastructure representing patent claims. A claim set may be obtained as part of the method. The claim set can include a list of sentences with numbers that define the invention precisely. The claim set can include one independent claim and up to three dependent claims. The dependent claims in the claim set can be dependent on the independent claims by referring either to the independent or an intervening claim. The method can include processing a line of a claim set. The claim line can be a text unit whose end is indicated by the presence of one of more characters at the end of a claim line. Methods may include identifying features from the claim line that will be stored in a data structure. One or more of the features can be either a main feature, or a sub-feature. The method can include storing one or more features within the data structure. The main feature can be a claimable step in a claimed manufacturing process, an actual part of the claimed machine, article or manufacture, or even a component within a claimed composition. The sub-feature may expand or describe an aspect of the main feature.
Yet another feature of the disclosure is a system that modifies data structures to represent patent claims so that they include language elements written in prose instead of patentese. The system can include one or multiple hardware processors that are configured using machine-readable instructions. The processor(s), if any, may be configured in a way to get a data structure that represents a claim set. The claim set can include a list of sentences numbered that define the invention precisely. The claim set can include one independent claim and up to three dependent claims. Each dependent claim may be dependent on the independent by referring to either the independent or an intervening claim. The processor(s), may be configured to perform natural language generation on the datastructure to provide a modified structure. The data structure can include a format that is specialized for organizing and storing information. This may include an array, list, two or three linked lists, stack, queue, graph, table or tree. The data structure can include language units taken from the claim set. The language units can be patentese. The language units can be organized according to one or several classifications of language elements. The modified data structures may have the exact same dimensions as those of the data structures representing the claims set, so that a data structure at a certain position in the data structure for the claim sets corresponds to the same data structure at the same place within the modified data structures.
Yet another aspect of this disclosure is a method to modify data structures that represent patent claims so that they include language elements written in prose instead of patentese. A data structure that represents a set of claims may be obtained as part of the method. The claim set can include a list of sentences that define the invention in detail. The claim set can include one independent claim and up to three dependent claims. The dependent claims in the claim set can be dependent on the independent claims by referring either to the independent or an intervening claim. The method can include performing a natural-language generation operation on the structure data to produce a modified structure data. The data structure can include a format that is specialized for organizing and storing information. This may include an array, list, two or three linked lists, stack, queue, graph, table or tree. The data structure can include language units taken from the claim set. The language units can be patentese. The language units can be organized according to one or several classifications of language elements. The modified data structures may have the exact same dimensions as those of the data structures representing the claims set, so that a data structure at a certain position in the data structure for the claim sets corresponds to the same data structure at the same place within the modified data structures.
Yet another aspect of this disclosure is a system that provides a data structure derived from the content of patent claims. The system can include one or multiple hardware processors that are configured using machine-readable instructions. The processor(s), if any, may be configured in a way to get a first datastructure representing a set of claims. The first datastructure may include language unit from the claim set. The language units can be patentese. The language units can be organized into the first data structure based on one or more classifications for individual language elements. The processor(s), if configured, may obtain a secondary data structure. The second datastructure may be the same size as the first one, so that an element of a datastructure at a certain position in the first structure corresponds with the same element within the second structure. The second datastructure may include language components associated with the claim sets. Language elements in the second data structure can be written in prose instead of patentese. The processors may be configured to identify the main features of the first data structure. The main feature can be a claimable process step, a physical component of an article or machine, or a part of claimed compositions of matter. Identify the sub-features in the second structure that correspond with the individual main features of the first structure. A sub feature can describe or elaborate on a particular aspect of the corresponding main feature. The processor(s), may be configured so that the sub features identified from the second structure are stored in a 3rd data structure, such that each sub feature identified is associated with the corresponding main feature in the 3rd data structure. The processor(s), based on initial and subsequent mentions identified, may be configured in such a way that they store in the third structure, and in association with the corresponding main feature of the second datastructure, sub features from the data structure which do not correspond individually to the main features of the first datastructure.
Another aspect of the disclosure is a method to provide a data structure derived from a patent claim with an ordered content. A first data structure that represents a set of claims may be obtained as part of the method. The first datastructure may include language unit from the claim set. The language units can be patentese. The language units can be organized into the first data structure based on one or more classifications for individual language elements. The method can include obtaining second data structure. The second datastructure may have the exact same dimensions as first datastructure, so that an element of a datastructure at a certain position in the first structure corresponds with the same element within the second structure. The second datastructure may include language components associated with the claim sets. Language elements in the second data structure can be written in prose instead of patentese. The method can include identifying the main features of the first data structure. The main feature can be a claimable process step, a physical component of an article or machine, or a part of claimed compositions of matter. Identify the sub-features in the second structure that correspond with the individual main features of the first structure. A sub feature can describe or elaborate on an aspect of the corresponding main feature. The method can include storing identified sub features in a second data structure so that each sub feature in the third structure is associated with the corresponding main feature. “The method can include, on the basis of identified initial mentions or identified subsequent mentions storing in a third data structure, and associating with corresponding main features, the sub-features from the second data structures that do not correspond individually to the main features within the first datastructure.

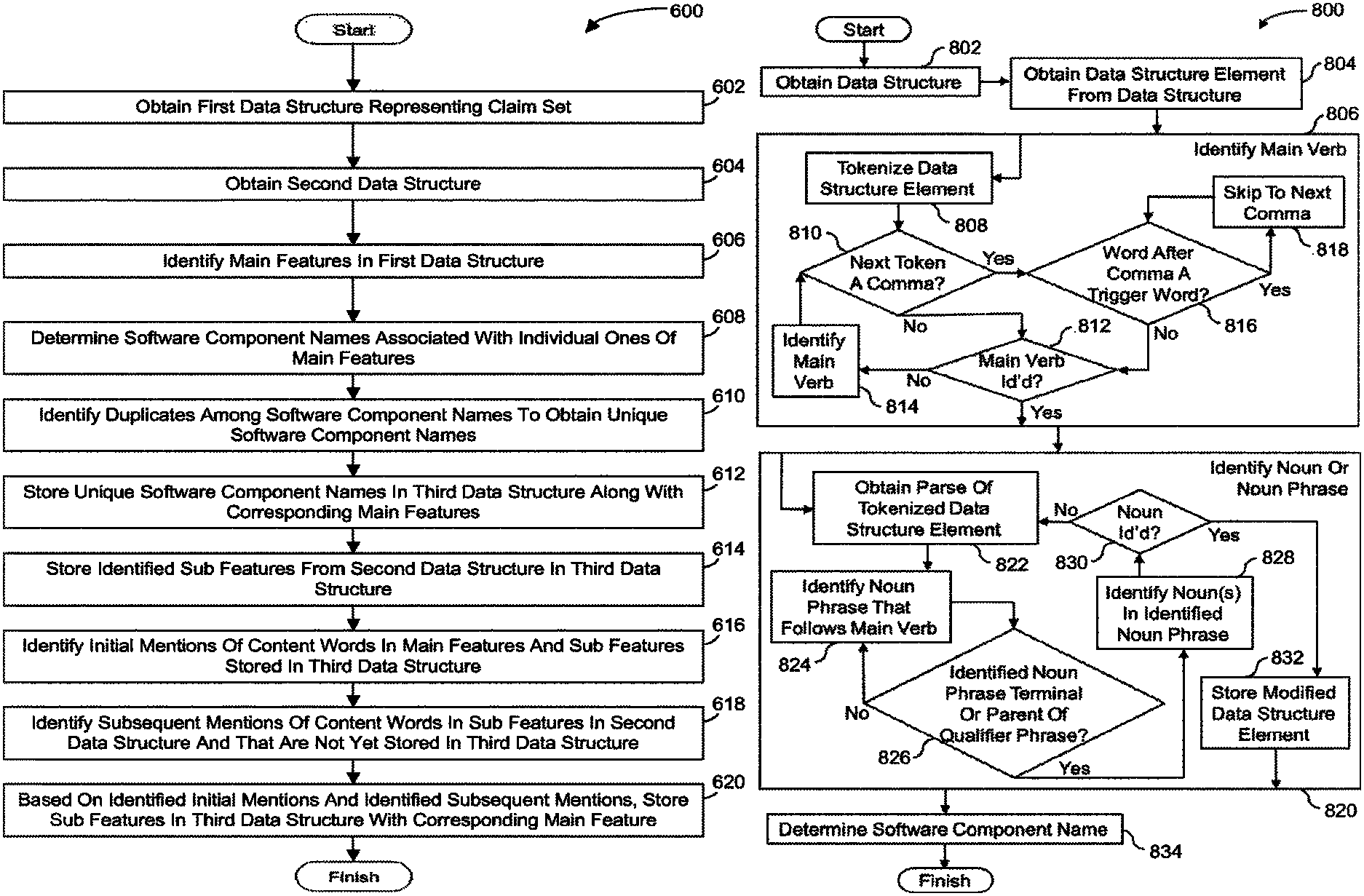
A further aspect of the present disclosure is a system configured to identify and name software components described in functional patent claim languages. The system can include one or multiple hardware processors configured using machine-readable instructions. The processor(s), if any, may be configured in a way to produce a data structure that represents a claim set. The data structure can include language units taken from the claim set. The language units can be patentese. The processors may be configured so that they can obtain a datastructure element from the datastructure. The main feature of the data structure element can be included. The main feature can include a claim process step. The processor(s), may be configured in such a way that they identify a main verb which is to be associated with the name of a software component that corresponds to a main feature. The main verb can describe the primary function of the feature. In response to identifying the main verb the processor(s), may be configured to identify a noun, or noun phrase, to be associated with a software component name. The processor(s), in response to identifying the main verb, may identify a noun or noun-phrase that will be associated with the software component name.
Another aspect of the disclosure is a method to identify and name software components using functional patent claim languages. A data structure representing a set of claims may be obtained as part of the method. The data structure can include language units taken from the claim set. The language units can be patentese. The method can include extracting a datastructure element from a datastructure. The main feature of the data structure element can be included. The main feature can include a claim process step. The method can include identifying the main verb that will be associated with the software component name corresponding to a main feature. The main verb can describe the primary function of a main feature. After identifying the primary verb, the method can include identifying a noun, or noun phrase, to be associated with a software component name. The method can include determining the name of the software component based on both the main verb identified and the noun or phrase identified.
Another aspect of the disclosure is a system that uses machine learning and rules based algorithms to create patent specifications based on patent claims provided by humans, so the patent specification can be created without the intervention of a human.” The system can include one or multiple hardware processors that are configured using machine-readable instructions. The processor(s), if any, may be configured in order to generate a claim set. The claim set can include a list of sentences that define the invention in detail. The claim set can include one independent claim, and possibly several dependent claims. Each dependent claim is dependent on the independent by referencing the independent or an intervening claim. The claim set was created by a person. The processors may be configured in such a way that they obtain a data structure that represents the claim set. The first datastructure may include language unit from the claim set. The language units can be patentese. The processor(s), if configured, may obtain a second structure. The second datastructure may be the same size as the first one, so that an element of a data structure at a certain position in the first structure corresponds with the same element within the second structure. The second datastructure may include language components associated with the claim sets. The language elements in the second data structure can be written in prose instead of patentese. The processors may be configured in a way to produce a third datastructure. The third datastructure may include content that is ordered and derived from the claims set. The third data structure can include ordered content based on claim structure, antecedent basis, or claim dependency. The processor(s), may be configured to determine a section of the patent specification using the first datastructure, the second datastructure, and the third.
And another aspect of this disclosure relates to the use of machine learning and rule-based algorithms in order to create a patent specifications based on patent claims provided by humans, such that the patent specifications are created without the intervention of a human.” A claim set may be obtained as part of the method. The claim set can include a list of sentences numbered that define the invention precisely. The claim set can include one independent claim, and possibly several dependent claims. Each dependent claim is dependent on the independent by referring back to the independent or an intervening claim. The claim set was created by a person. The method can include obtaining a data structure that represents the claim set. The first datastructure may include language unit from the claim collection. The language units can be patentese. The method can include obtaining second data structures. The second datastructure may have the exact same dimensions as first datastructure, so that an element of a datastructure at a certain position in the first structure corresponds with the same element within the second structure. The second datastructure may include language components associated with the claim sets. Language elements in the second data structure can be written in prose instead of patentese. The method can include obtaining third data structure. The third datastructure may contain ordered content derived directly from the claim set. The third data structure’s ordered content may be based on the claim structure, the antecedent basis, or the claim dependency of the claim. The method can include determining one of more sections of the Patent Specification based on the data structures.
The following description, the claims attached, and the accompanying drawings will make clear these and other features and characteristics, including the operation of related structural elements, the functions of those parts, and the economies of manufacturing. Like reference numbers designate the corresponding parts of each figure. The drawings should be understood to serve only as an illustration and description and not as a limitation of the invention. In the specification and the claims, singular forms of ‘a?, ‘an? and ‘the? are used. Include plural referents, unless the context clearly dictates that otherwise.
FIG. In accordance with a number of implementations, FIG. 1 shows a system 100 that is configured to provide a data-structure representing patent claims. In some implementations system 100 can include one or multiple servers 102. Server(s) may be configured to communicate to one or more computing platforms client 104 in accordance with a client/server architectural design and/or another architecture. Client computing platforms 104 can be configured to communicate via server(s), 102, or according to peer-to-peer architecture or other architectures. Users can access system 100 through client computing platforms 104.
Machine-readable instructions 106 can be used to configure “Server(s).” Machine-readable instructions (106), may include one, two or more modules of instruction. Computer program modules can be included in the instruction modules. The instruction modules can include one or more modules such as a module for obtaining a set of claims 108, an instruction module for processing claim lines 110, an instruction module for determining claim lines 112, a module to store claim lines 114, module to store portions 116, module that identifies features 118, module that classifies markers 120 and/or any other modules.
The “Claim Set Obtaining Module 108” may be configured in order to obtain a set of claims. The claim set can include a list of sentences numbered in order to define the invention. The claim number indicates the position of the corresponding claim within the numbered list sentences of the claim. The claim set can include one or more independent claims and one-or-more dependent claims. The dependent claims in the claim set can be dependent on the independent claim. They may refer to either the independent or an intervening claim.
Claim Line Processing Module 110 can be configured to process one claim line from the claim set. In order to determine whether a claim line belongs to an independent or dependent claim, it is necessary to check whether the line contains a reference to a different claim. Referencing another claim may indicate the claim line is part of a dependent claim. The claim line can be a text unit whose end is indicated by the presence of one or several end-of-claim-line characters. As an example that is not limited, one or more characters at the end of a claim line may be a colon or semi-colon or a carriage-return.
The Claim Line Determination Module 112 can be configured to determine if the claim line is the first claim line in a claim. If the claim number is present, it can be used to determine whether the claim begins with the claim number.

The Claim Line Determination Module 112 can be configured so that, if it is determined that the claim lines are the first claim lines of a claim then the module will determine whether or not the claim lines belong to an independent claim.

Click here to view the patent on Google Patents.