
Invented by Jain; Sanil, Menegali; Marcelo, Luong; Thang, Ghiasi; Golnaz, Le; Quoc, Cohen; Aaron, Chae; Elle

Artificial intelligence is changing how we work, create, and share ideas. One of the latest steps in this journey is using large language models (LLMs) to turn simple words into rich, helpful slide decks and guides—automatically. This blog post will walk you through the new patent application for such a system. We will start by looking at why this invention fits today’s needs, then see how older solutions worked (and what they missed), and finally, break down how this patent brings something new and powerful to the table. Let’s dive in.
Background and Market Context
People everywhere—from school kids to office workers—need to make slide presentations. Sometimes, it’s for a class project, sometimes for a big meeting, and sometimes just to explain how to do something, like setting up a new router at home. Traditionally, making a slide deck means sitting in front of a computer, opening up PowerPoint or Google Slides, searching for pictures, typing in points, and arranging everything just right. It’s slow, and it takes know-how and patience.
Now, imagine if you could just talk to your phone or type a request, like, “Can you make a slide deck about the history of pizza?” In seconds, you’d get a set of slides—with text, images, even speaker notes—all ready to use. That’s the dream this patent is moving toward.
Why is this so important today? There are a few big reasons:
First, devices are getting smaller. Lots of us use tablets or phones, with tiny screens and no mouse or keyboard, to get work done. Creating slides on these devices is not easy. Second, not everyone has the same abilities. Some people find it hard to use standard computers, and need simpler, more natural ways to get help or create content. Third, we live in a world where time is short. People want quick answers and tools that just work.
Current slide-making apps and assistants are not up to the job. They may offer slide templates or design help, but you still have to pull in all the content and arrange it yourself. Even so-called “smart” assistants might give you a text summary or a list of steps, but not a finished, ready-to-use slide deck with both words and images in the right places. And when they do offer images, they often just stick them before or after the text, making the experience clunky and confusing—especially on small screens.
This patent application is aimed right at these pain points. It wants to let you use simple, everyday language—typed or spoken—to ask for presentations or guides. Then, using AI, it builds a full slide deck for you, with both text and images (or even video or audio), putting everything in the right spots. The result is a smoother, faster, easier way to create and use slides, whether you’re at home, at work, or on the go.
Scientific Rationale and Prior Art

To understand why this new system is a leap forward, let’s look at what has come before, and what problems have stood in the way. In the last few years, large language models (LLMs) like GPT, BERT, and others have shown they can answer questions, write stories, and even chat with people in natural ways. These models are trained on huge amounts of data—websites, articles, books—so they have a wide base of knowledge. Many tools now use them to power search engines, chatbots, or writing aids.
But when it comes to making slides, things get tricky. The main challenge is combining words and pictures so they make sense together. For example, if you ask for “steps to change the oil in a Honda Civic,” you want each step to have both the text (“remove the oil cap”) and the right picture (showing where the cap is). Most systems today don’t do this well. If they add images at all, they just stick them at the top or bottom—so the user has to scroll, guess which image matches which step, and maybe drag things around to make it usable.
Another issue is flexibility. People may want different things: some may want more pictures than words, others want detailed speaker notes, and others need the slides in a certain file format. Existing systems are not good at listening to these wishes or changing the output based on device, user, or context. There’s also a challenge with updates. What if you want to change just one picture or point on a slide? Most tools make this hard, requiring you to start over.
Let’s talk about “prior art”—the older inventions or methods this patent builds upon (and improves). Before now, here’s what the world had:
– Slide-making apps with templates: You pick a style, but you do all the writing and image-finding.
– Chatbots or assistants that answer questions: Useful for quick info, but they don’t give you full, formatted slides.
– Some smart tools that add images to text, but not in a smart way—just before or after, without matching them to the right step or point.
– A few systems that try to summarize documents or split text into steps, but don’t arrange it as slides with images and speaker notes.
What was missing? In short: a way to go from a natural language request to a set of slides, where each slide has the right text, the right images (or videos or audio), and even speaker notes, all placed exactly where they should be. Plus, older systems didn’t make it easy to request changes or control things like the number of slides, the amount of media, or the format of the output.
This is where the new patent comes in. It uses a trained LLM not only to understand your request, but also to decide, for each slide, what text should go where, what picture or video (or prompt for a generative model) should be added, and how it all fits together. It can even fetch media from different sources, or use generative AI to create a new image or video when nothing suitable is found. The system is smart enough to handle extra settings (like “make 10 slides” or “use more pictures for kids”), and can output everything in a format ready for PowerPoint or Google Slides.
In sum, the scientific leap here is using a single, smart system to turn your words into a full, multi-modal slide deck, tailored to your needs, with all the parts (text, media, notes) in the right spots. That’s something no previous tool could do.
Invention Description and Key Innovations
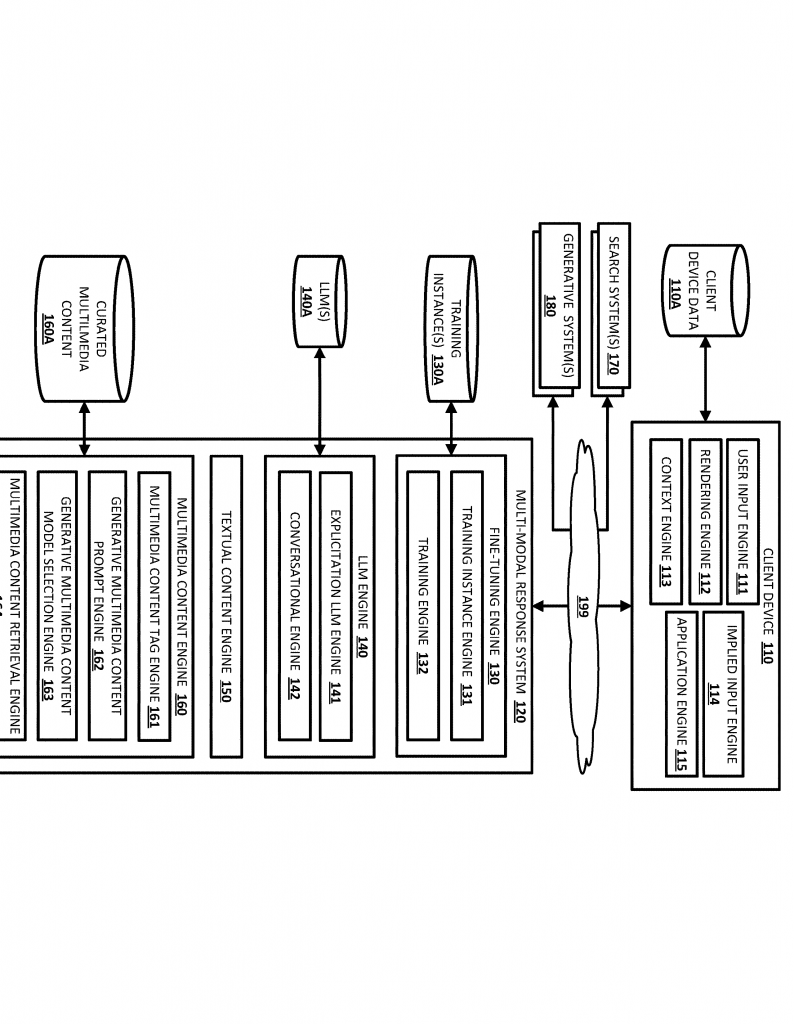
Now, let’s break down what this patent actually does and why it matters. The system starts when you (the user) ask for a set of slides or help with a task, using natural words. This could be typed or spoken, and you can use your phone, laptop, or even a smart speaker. For example, you might say, “Show me how to set up my new printer,” or, “Make a slide deck about the planets for my class.”
Here’s how the invention works, step by step, in very simple terms:
1. Understanding Your Request
The system listens for your input—what you want slides about, or what task you need help with. It can read extra hints, like “make it for kids,” “I need 5 slides,” or “add a video.”
2. Using a Trained Language Model
It sends your request to a large language model (LLM), which has been specially trained not just to write good text, but also to know where to put pictures, videos, or other media, and how to break things up into slides. This training is done using lots of examples: old requests matched with slide decks made by people, showing the right way to arrange text and media.
3. Building the Slide Deck
The LLM decides, for each slide:
– What the title should be.
– What text or bullet points to add.
– Where to place pictures, videos, or audio.
– If needed, what speaker notes (extra text just for the presenter) to include.
It can even decide to fetch a picture from the web, or, if nothing is available, write a prompt for a generative model (like DALL-E or Midjourney) to create a new image or video.
4. Finding and Creating Media
If the slide needs an image or video, the system checks if it can find one. If not, it tells a generative AI to make a new one based on the prompt from the LLM (“draw a car engine from above,” for example). The media is then slotted into the right place on the slide.
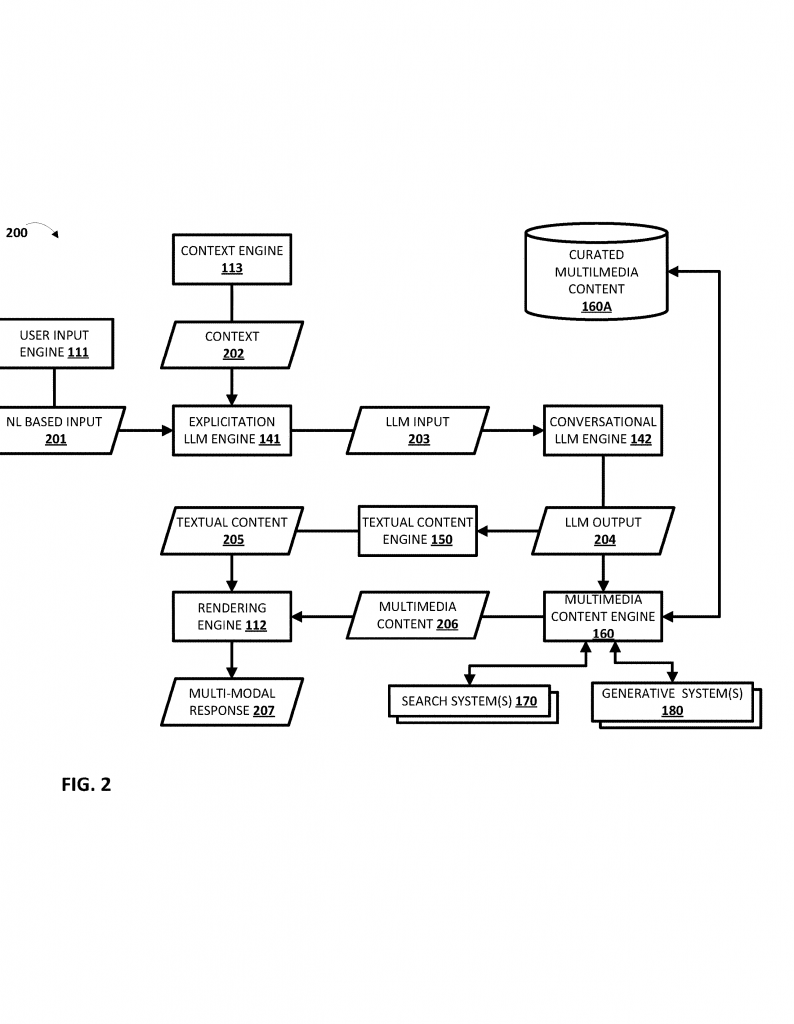
5. Arranging Everything Logically
Unlike old systems, this one puts each piece of text and media in the right spot—no more scrolling up and down to match pictures to words. The slides are ready to use, with images next to the right points, and speaker notes shown separately if you need them.
6. Output and Flexibility
The finished slides are sent to your device. You can see them right away, and the system can give you the file in a format you can open in PowerPoint, Google Slides, or another app. If you want to change something (“add more images,” “make it simpler,” “change to 7 slides”), you just say so, and it updates the slides—no need to start over.
7. Smart Customization
The system can adjust the output based on your device (phone, tablet, desktop), your needs (for kids, for experts), or even your preferences (more images, less text). It remembers your requests and can use context (like what app you’re in, your past choices, or your settings) to make better slides.
Key Innovations and Advantages
– Real Multi-Modal Output: The system doesn’t just slap images onto slides. It matches each image, video, or audio clip to the right part of the text, arranging everything so it makes sense and is easy to follow.
– Fine-Tuned AI: This isn’t a generic language model—it’s trained with many slide-making examples, so it knows how real people like their slides to look and work.
– Flexible Media Handling: The system can pull images or videos from the web, or create new ones using AI if nothing fits. This means you always get the right picture—even for rare or new topics.
– Device and User Awareness: It can adjust slides for small screens, people with disabilities, or special needs, making sure everyone can use it.
– One-Step and Iterative Creation: You can make a full slide deck in one go, or ask for tweaks and changes later, just by asking in plain language.
– Reduced Effort and Faster Output: By arranging everything as you ask, the system cuts down on time and effort. No more dragging pictures around or hunting for the right format.
– Source Transparency: The system can show where each image or piece of text came from, letting you check for accuracy and avoid “hallucinations” (wrong or made-up info from the AI).
– Plug-and-Play Integration: It can work as a stand-alone app, a plug-in for PowerPoint or Google Slides, or even as part of a chat assistant.
– Smart Configuration: You can say things like, “make it for a 10-minute talk,” “use more pictures,” or “focus on step-by-step instructions,” and the system listens and adapts.
– Automatic Updates: If your needs change (“that image is for the wrong model—show me one for the 2005 version”), just say so, and the system updates the slides, media, and notes.
All of these features work together to create a tool that turns your ideas, in your own words, into ready-to-use, multi-modal presentations or guides, while saving you time and making the process much easier.
Conclusion
The patent we’ve explored brings a big step forward for anyone who needs to make slides, guides, or step-by-step instructions. With its smart use of natural language AI, flexible media handling, and deep understanding of both user needs and device limits, this system promises to make slide creation faster, easier, and much more natural—especially for people on the go, working with small devices, or needing extra help.
By letting you use plain language to request, change, and customize your slides, and by arranging both words and images in the right spots, this invention closes the gap between what people want and what technology can deliver. Whether you’re a student, a teacher, a business leader, or just someone who wants to explain how to fix a leaky faucet, this new approach could change how you share your ideas.
As AI continues to grow, tools like this will only get better—helping everyone turn their words into clear, beautiful, and useful presentations, with just a few clicks or spoken words. The future of slide-making is here, and it’s as simple as asking.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217585.