
Invented by Galvin; Brian
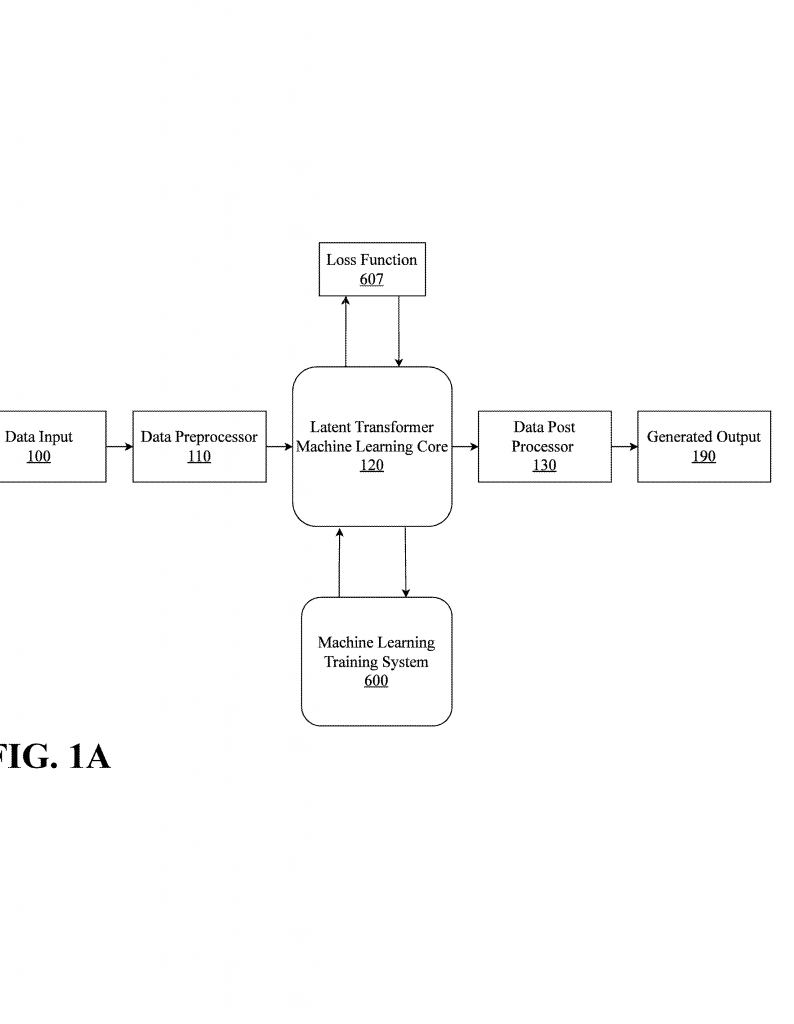
Time series prediction is everywhere: from weather forecasting and stock prices to predicting electricity demand. But building systems that make these predictions accurately, quickly, and with real-world confidence is tough. A recently published patent application describes a new deep learning system that tackles these challenges in a unique, efficient way. In this article, we break down this invention so you can understand both the big picture and the details, even if you’re new to AI or patents.
Background and Market Context
Technology is changing the way we predict future events. Businesses and organizations rely on time series forecasts to make important decisions. From predicting how much energy people will use, to when a store will run out of stock, or how hospital patient numbers will rise or fall, these forecasts help save money, plan resources, and even save lives.
Classic prediction methods, like ARIMA or even regular neural networks, often fall short. They may not handle sudden changes, struggle when there’s not much past data, or fail to explain how confident they are about their guesses. As the world generates more and more data—financial transactions, sensor readings, social media activity—there’s a push for smarter, faster, and more reliable forecasting tools.
Deep learning, especially models called Transformers, has revolutionized fields like language processing (think chatbots or translation tools). These models are good at learning from huge amounts of data. But most are designed for language—not for time series, which has its own challenges (like missing data or patterns that change over time).
Companies and researchers need systems that can:
- Process different types of time series data (short or long, with or without missing values)
- Give predictions for different time frames (like next hour, next day, or next week, all at once)
- Say how confident they are in their predictions (giving a “confidence interval” instead of just a single number)
- Learn from related data (for example, if you have lots of data for one hospital and only a little for another, can you use what you know to help both?)
The invention described in this patent application is designed for these real-world needs. It aims to predict future values in any time series, do so quickly, and show how reliable those predictions are. It’s flexible, efficient, and can be used in many fields: finance, health, industry, and beyond.
Scientific Rationale and Prior Art
To see why this new system matters, let’s look at the tools that came before it.
Traditional models like ARIMA or exponential smoothing are easy to use, but they can’t handle complex relationships or missing data well. More recent machine learning approaches, like LSTM (Long Short-Term Memory) networks, can model patterns over time, but they often need lots of data and can be slow to train.
Transformers, a type of deep learning model first used in natural language processing, have recently been adapted for time series. Transformers use “self-attention” to look at all parts of an input sequence at once, which helps them pick up on long-range patterns. But standard Transformers are built for text—they use “embedding” and “positional encoding” layers to help the model understand the order and meaning of words. These layers add complexity and use a lot of memory.
This new invention removes the embedding and positional encoding layers, making the model simpler and more efficient for time series tasks. Instead of using dense vector representations (which can slow things down), it works in “latent space”—a compressed, hidden representation learned by the model. This makes the system flexible: it can work with numbers, text, or even images, and handle different lengths and types of data.
Past systems also tend to predict just one point in the future. Real-world users need forecasts for several time frames (like predicting both the next 10 minutes and the next hour). They also want to know how certain the model is about its predictions. Previous models often ignored these needs, or required complex add-ons to provide “confidence intervals.”
In addition, traditional models use fixed-length sequences and basic padding (like filling missing values with zeros). This can distort the underlying patterns. The new system described here uses “adaptive padding”—it learns the best way to fill in missing or future values based on the actual data, making the predictions more accurate.
Another challenge is making good predictions when there’s not much data. If you only have a few months of sales records for a new store, can you improve predictions by borrowing knowledge from similar stores? This is called “transfer learning.” Classic models don’t do this, but the new system includes a way to share and reuse patterns across different time series.
Finally, earlier systems might focus only on predicting the next number in a sequence, without caring if the overall trend (going up or down) is right, or if the statistical properties of the sequence (like average and variance) are preserved. The invention here introduces “multi-objective” training—optimizing for accuracy, trend direction, and statistical consistency all at once.
Invention Description and Key Innovations
Now let’s dive into how this system works in plain terms.
The core idea is simple: take a chunk of recent data (say, the last 1000 readings), remove the last few points (say, the last 50), and replace those missing points with smart padding. Then, use a deep learning model to “guess” what the missing points should be, based on the rest of the data. During training, the model learns by trying to reconstruct the full sequence, including the missing part. When making real predictions, the missing part is the future—you’re asking the model to tell you what comes next.
Here’s a step-by-step view of the system:
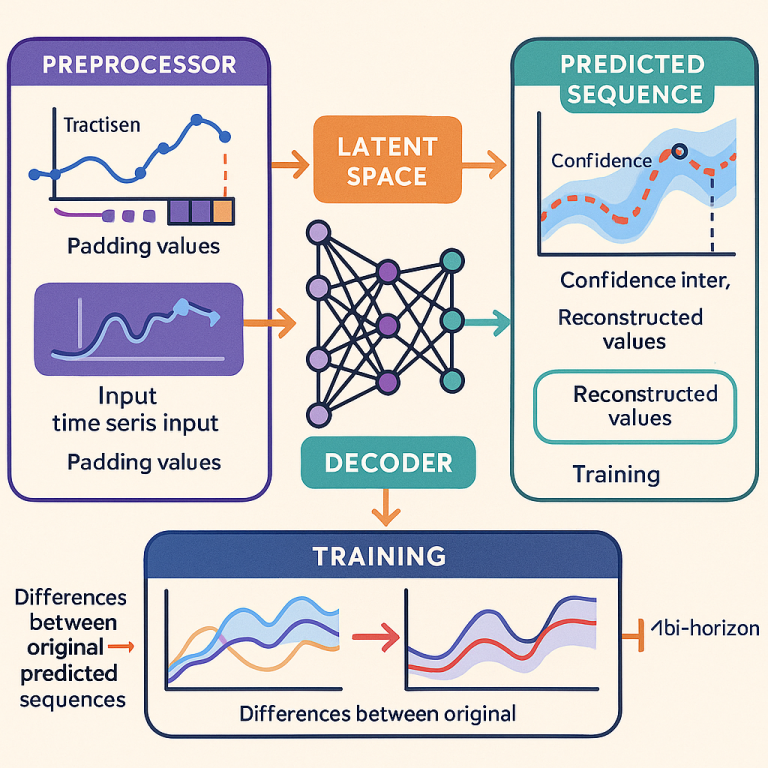
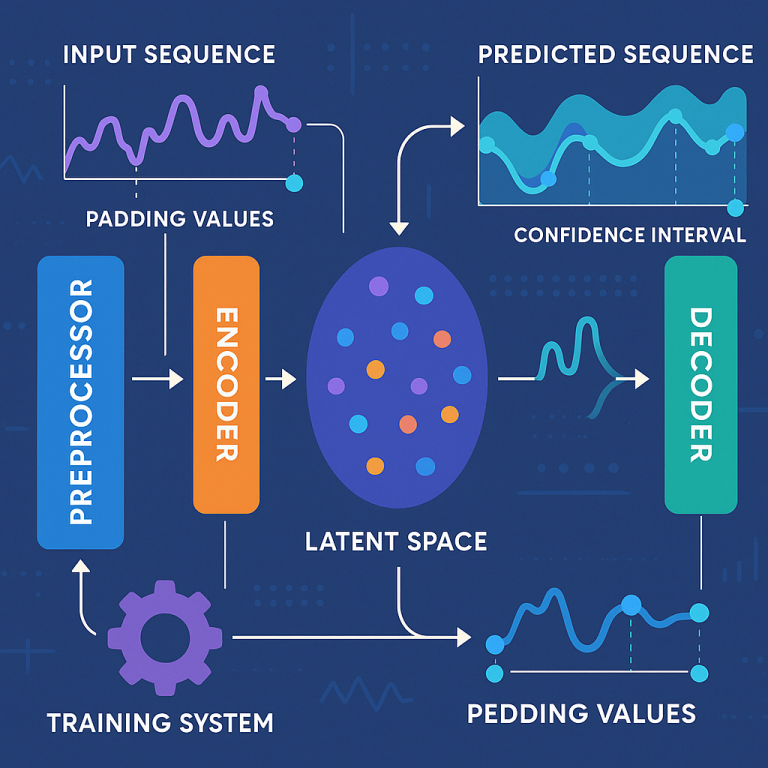
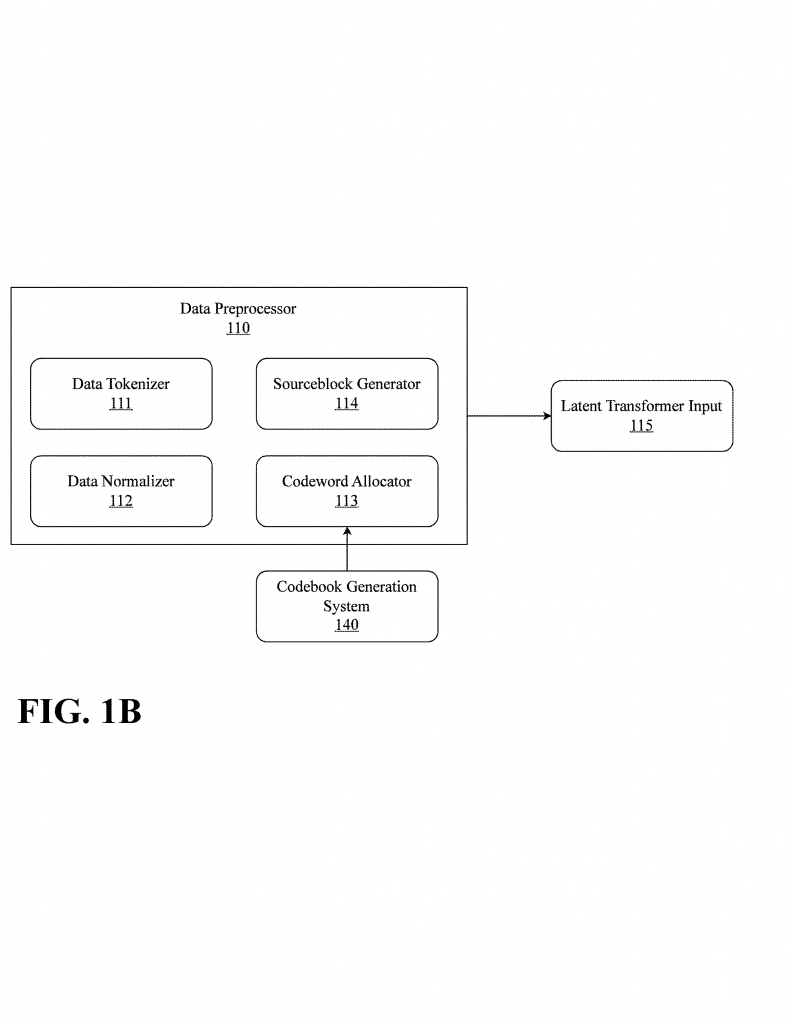
1. Data Preprocessing: The system takes your input sequence, trims off the last few data points, and creates a “truncated” sequence. It then adds padding values to keep the sequence length the same. But instead of just adding zeros, it can learn what type of padding works best for your data (maybe repeating the last known value, or using a statistical guess).
2. Encoding: The padded sequence is passed through an encoder—a special type of neural network (often a “Variational Autoencoder” or VAE). This encoder compresses the data into a “latent space”—a small, dense representation that captures the most important patterns.
3. Decoding: The “latent space” vector is then passed to a decoder, which tries to reconstruct the full original sequence. The decoder is trained to pay special attention to the missing (padded) parts, learning how to predict them accurately based on the historical data.
4. Multi-Horizon Prediction: Instead of predicting just the next point, the decoder can predict several future time frames at once. For example, it might predict the next 10, 25, and 50 points. The system can give more importance to one time frame if needed.
5. Confidence Estimation: The system uses a trick called “dropout” during prediction. It runs the model several times, each time randomly turning off some parts of the network. By looking at how much the predictions vary, it can calculate how confident it is in each prediction, giving you a confidence interval.
6. Historical Pattern Matching: The system keeps a library of past patterns (“latent vectors”) and their outcomes. When making a new prediction, it can search this library to find similar situations from the past, and adjust its prediction based on how those turned out.
7. Cross-Series Knowledge Transfer: If you have multiple related time series (like sales for different stores), the system can learn shared patterns and apply them to a new series with little data, improving accuracy.
8. Multi-Objective Training: The system doesn’t just focus on point accuracy. It also tries to preserve the statistical properties of the sequence (like mean and variance) and get the overall trend direction right. You can choose how much weight to give each goal.
9. Transformer-Based Architecture Without Embeddings: Unlike classic Transformers, this system works directly on latent space vectors. It skips the embedding and positional encoding steps, which means it uses less memory and is faster, while still picking up complex patterns.
10. Modular and Scalable Design: The system is built in pieces. You can use just the core parts for a lightweight setup, or add advanced modules (like multi-horizon prediction or cross-series learning) for more power.
These innovations mean the system is:
- Flexible (works with many types of data and prediction needs)
- Accurate (captures complex patterns and relationships)
- Efficient (uses memory and computation wisely)
- Trustworthy (provides confidence intervals and preserves important properties of the data)
- Adaptable (learns from related data and updates its approach as new data comes in)
In practice, you can use this system for things like:
- Predicting electricity demand across the grid, including confidence bounds for each forecast period
- Forecasting patient vital signs in hospitals, with early warnings for clinical deterioration
- Anticipating equipment failures in manufacturing by analyzing sensor readings
- Making short- and long-term financial predictions using both market data and news sentiment
The system is designed to handle missing data, adapt to changing patterns, and provide actionable, reliable forecasts in real time.
Conclusion
This deep learning system for time series prediction, as described in the patent application, is a big step forward. By combining smart data preparation, powerful neural network architectures, adaptive padding, multi-horizon forecasting, confidence estimation, and transfer learning, it addresses real-world challenges in forecasting.
It moves beyond older, rigid models by being flexible, efficient, and trustworthy. Whether you’re managing a power grid, running a hospital, trading stocks, or monitoring industrial equipment, this system offers a practical, scalable way to make better predictions—and to know how much you can trust them.
For anyone building or using predictive systems, this invention shows how modern AI can be made more useful, transparent, and reliable. It’s not just about getting the next number right—it’s about understanding the patterns, knowing the risks, and making smarter decisions every day.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363334.