Invented by BANSAL; Gaurav
Introduction:
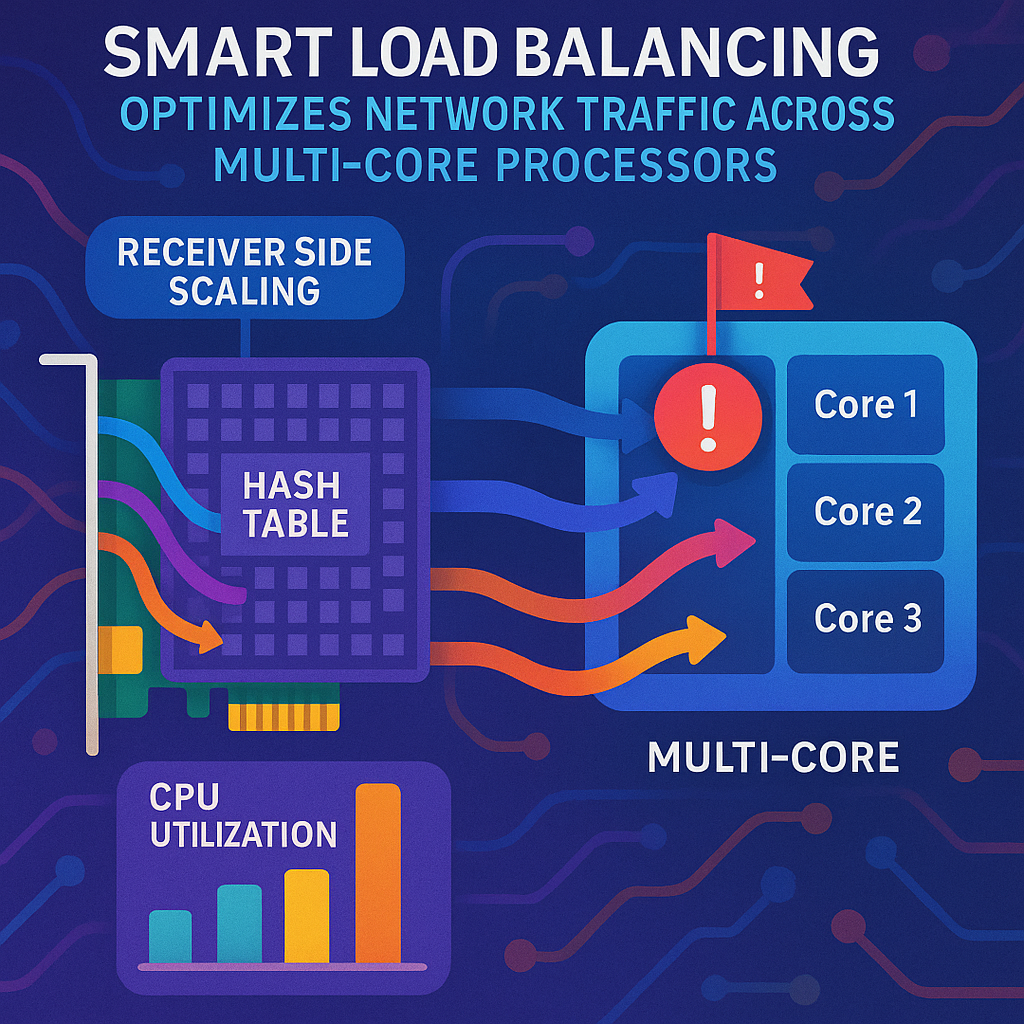
Managing network traffic for busy cloud servers is harder than ever. As more users connect online, servers handle tons of data. If traffic isn’t shared fairly across processor cores, some get too busy while others sit idle. This new patent application details a way for network cards to notice when one core is too busy and shift new traffic away from it, keeping things moving fast and smooth. Let’s look at why this matters and how the invention works.
Background and Market Context
In today’s world, almost everything runs on the cloud. From social media to banking, streaming, and even gaming, data centers are the heart of the action. These data centers are filled with servers, each with a powerful processor that has many “cores.” Each core is like a worker, helping to run software and process network traffic. To connect all these servers, special hardware called network interface cards (NICs) is used. These cards handle the flow of data in and out of the servers.
As networks got faster—thanks to 5G, 6G, and other new tech—the amount of data moving through these servers exploded. More data means more chances for slowdowns. If one core gets too much work while others don’t have enough, data can pile up and make everything sluggish. This is especially true in cloud environments, where lots of different apps and services are running at once, and users expect quick responses.
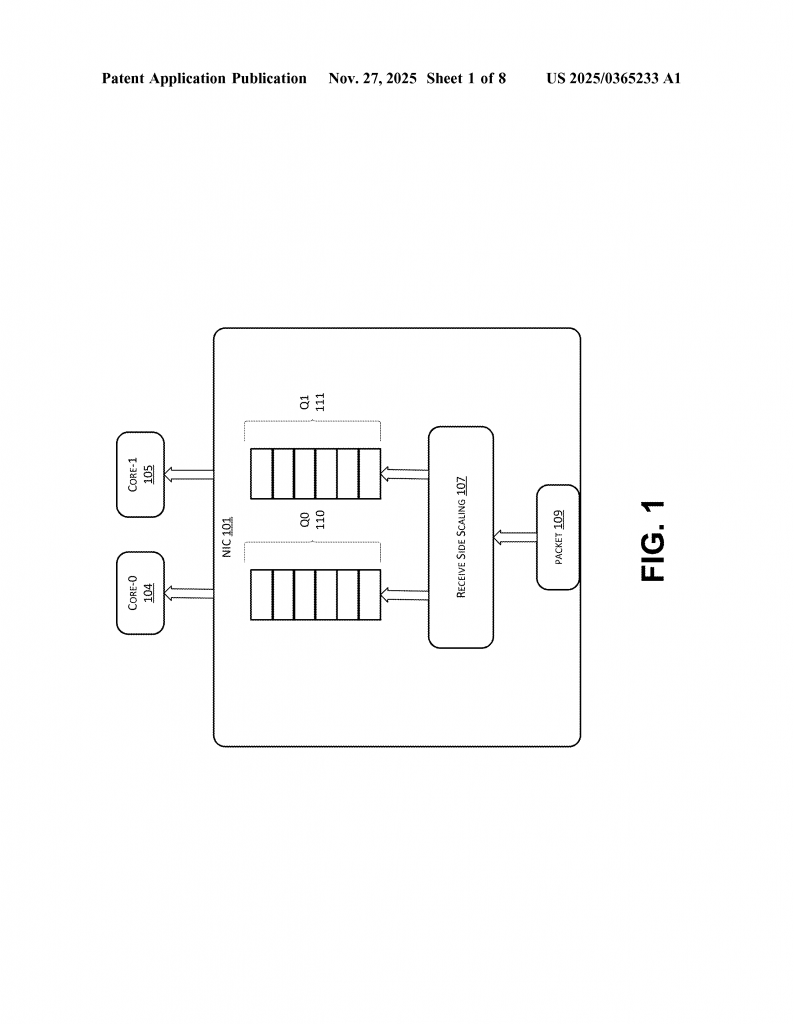
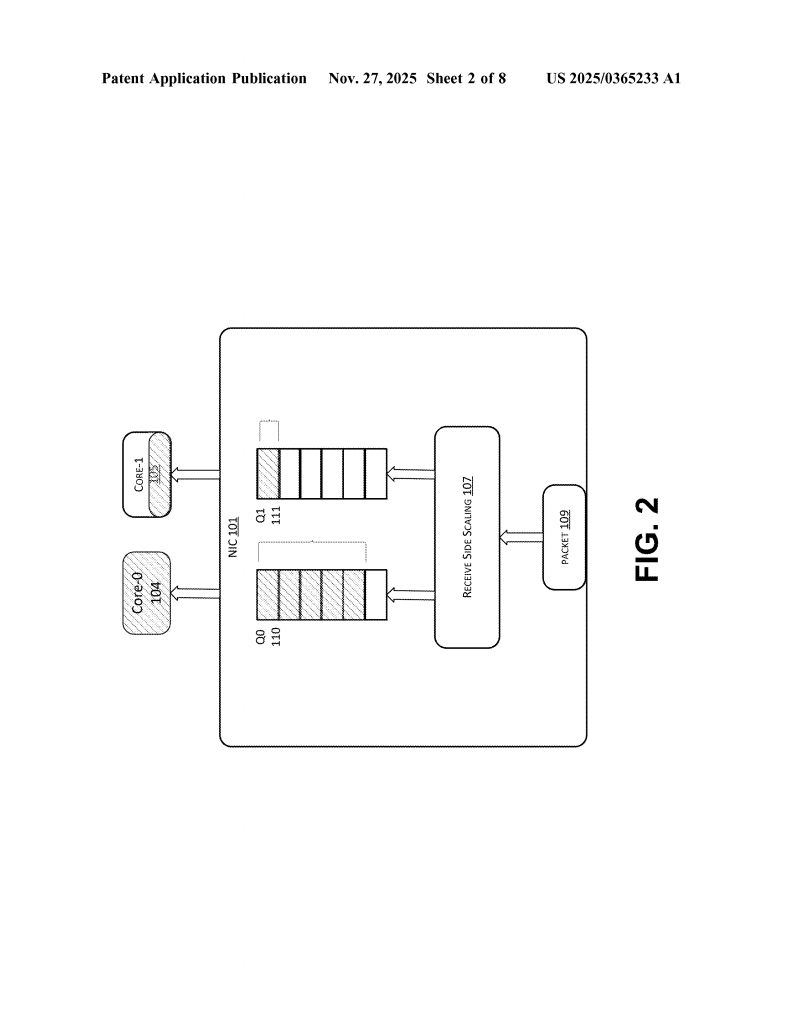
To keep things balanced, networks use something called load balancing. This is a way to spread out the work so one server or one core doesn’t get overwhelmed. There are many ways to do this. Sometimes, traffic is split between entire servers. Other times, it’s split between the cores inside a server. One popular way to split traffic between cores is called Receive Side Scaling, or RSS for short. RSS helps the NIC decide which core should handle each new piece of network traffic, using a kind of “hashing” trick based on details from the data packets.
But even with RSS, problems can happen. The NIC doesn’t always know if one of the cores is already too busy. So, the NIC might keep sending new traffic to an already overloaded core, while other cores are doing very little. This can waste resources and slow down the whole system. With user expectations always getting higher, and with more critical services moving online, these slowdowns can be a big problem for companies and end users alike.
That’s why companies are looking for smarter ways to manage traffic inside their servers. The goal is to use every core as much as possible without letting any single core become a bottleneck. The new invention described in this patent application aims to fix this problem using a clever tweak to RSS and some smart tracking inside the NIC itself.
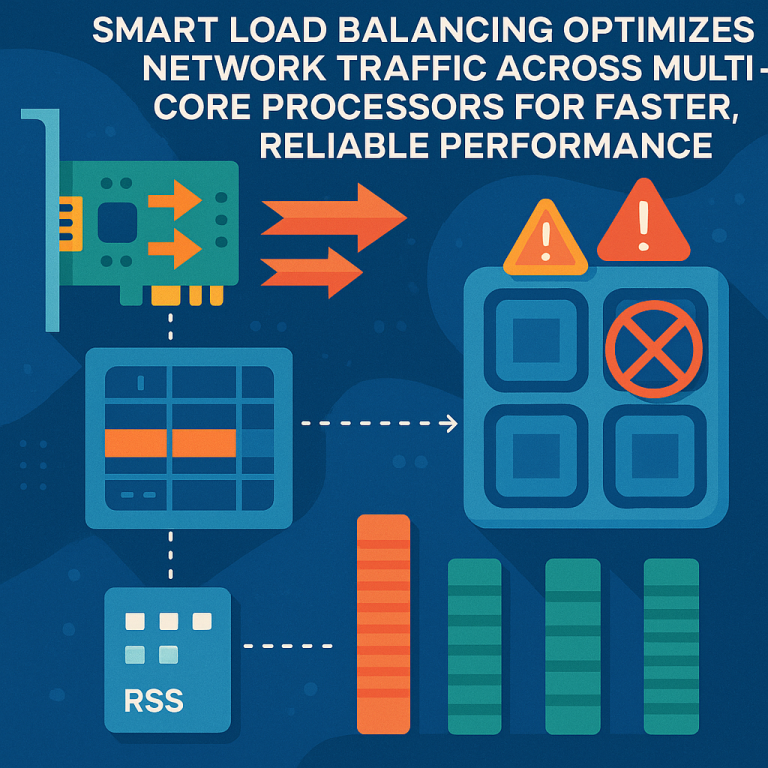
Scientific Rationale and Prior Art
Let’s look at how things worked before, and why those methods are starting to hit their limits. Traditionally, RSS gives the NIC a way to spread incoming network packets across multiple cores. When a packet comes in, RSS uses certain pieces of information from the packet—like source and destination addresses and ports—to create a “hash.” This hash is then used to decide which queue (and thus, which core) will handle the packet. Each queue is linked to a specific core. This way, network traffic is split up and sent to different cores, keeping things balanced.
But here’s the catch: the RSS process doesn’t actually know if a core is already too busy. RSS just uses the hash and sends the packet to the assigned queue, no matter how overloaded the core might be. If most new flows happen to get hashed to the same queue over and over, that core gets slammed with work, while others are barely used. This can cause packets to be delayed or even dropped, slowing down apps and frustrating users.
Some earlier attempts to fix this problem involved software-based load balancers or making manual changes to the RSS configuration. These approaches could help a bit, but they often added extra steps, made things slower, or required constant tweaking by administrators. Hardware-based solutions, like special chips or logic in the NIC, offered better speed but usually didn’t have a way to “see” if a core was overloaded in real time.
Another issue is memory use. If you try to track every single network flow (which can be millions at once), you need a lot of memory. Some prior solutions tried to store details about every flow, but this quickly fills up the NIC’s memory and slows down performance.
Finally, there’s the problem with different types of network traffic. TCP flows can be tracked easily because they have a clear “start” (the SYN packet), but UDP flows don’t always have such a clear marker. This makes it harder to spot new UDP flows and balance them properly. Some newer protocols, like QUIC (which is a type of UDP), do have recognizable starts, but most regular UDP flows do not. Prior art struggled to handle these cases without wasting more memory or adding complexity.
In short, the old ways of doing RSS were simple and fast, but blind to how busy each core was. Software fixes helped a little but weren’t fast enough. Hardware solutions were quick but lacked “awareness” of core overload. And tracking every flow was too costly in terms of memory. There was a need for a solution that could notice when a core was too busy, avoid sending new traffic to that core, and do so quickly and with minimal memory use—ideally, all inside the NIC hardware.
Invention Description and Key Innovations
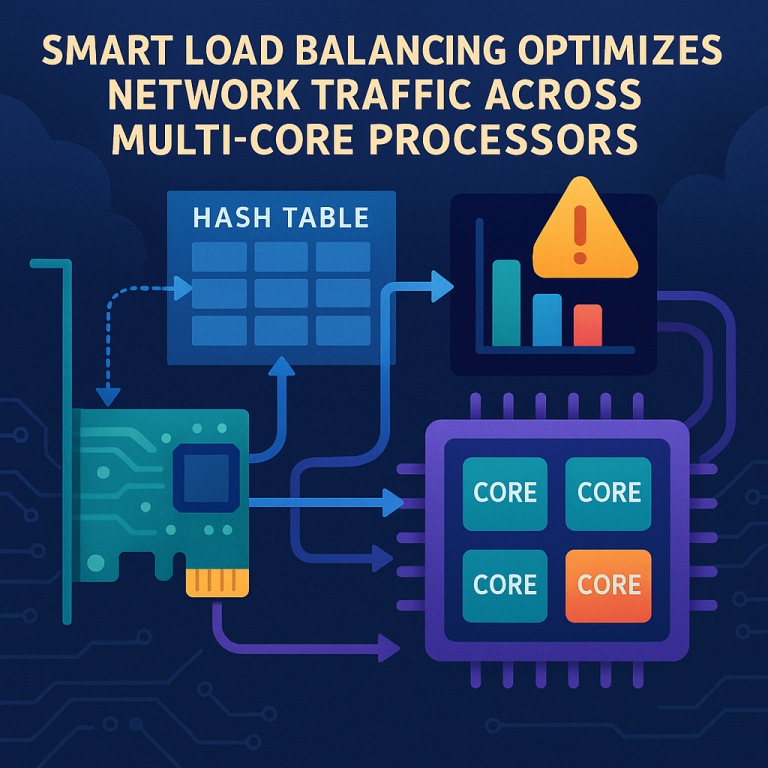
This invention gives the NIC the smarts to avoid overloaded processor cores on the fly. Here’s how it works, step by step, in simple words:
1. The NIC Watches Core Activity:
The NIC is connected to a processor with many cores. Each core has a “queue” for network traffic. The NIC keeps an eye on how busy each core is. When a core gets too busy—say, it reaches a certain usage threshold—the system sets a special “flag” for that core. This flag tells the NIC, “Hey, don’t send me more new work right now.”
2. Smart RSS Excludes Busy Cores:
When a new packet comes in for a new communication flow (like a new connection or session), the NIC checks the flags. If a flag says a core is overloaded, RSS will not use that core’s queue when balancing new traffic. So, only the cores that still have extra capacity are considered.
3. Using a Hash Table for Tracking:
To keep track of where each flow is assigned, the NIC creates a hash table. Think of this as a smart list showing which flow is linked to which core. The hash table uses a “five-tuple” from the packet (source IP, source port, destination IP, destination port, and protocol) as the key. This way, once a flow is assigned to a core, all packets for that flow go to the same core for consistency.
4. Assigning New Flows:
For every new flow, the NIC looks at the current flags. If a core is busy, the NIC leaves it out of the hash calculation. The RSS function (often a modulo operation based on the number of available cores or queues) is run only on the remaining, less-busy cores. The NIC picks a core from the available ones and assigns the new flow to it. The hash table is updated to show this assignment.
5. Saving Memory with Clever Rules:
The NIC doesn’t have to track every flow forever. If no cores are overloaded, the hash table doesn’t need to be updated for each flow—traffic goes out as normal. Only when a core is flagged as overloaded does the hash table get populated for new flows. To save more memory, the NIC can store entries only for TCP flows (which are easy to identify) or for QUIC flows (a major type of UDP traffic that has a clear start).
6. Dynamic Adjustment:
Once the overloaded core is no longer busy (the flag resets), it goes back into the pool. The NIC’s RSS function starts including it again for new flows. This way, the system can bounce back and forth, always keeping as many cores busy as possible but never letting one core get overwhelmed.
7. Works for Many Cores, Not Just Two:
While the examples use two cores for simplicity, the invention works for any number. If, for example, out of four cores, core 2 gets overloaded, only cores 0, 1, and 3 are considered for new flows. The RSS calculation is adjusted so it only picks from the available cores. This is handled with a simple mapping in the hash table.
8. Handles Different Types of Traffic:
Since TCP flows start with a SYN packet, the NIC can easily spot new flows and update the hash table. For normal UDP, it’s trickier, but for QUIC (a kind of UDP), the NIC looks for a “Client Hello” message. This means the system is efficient for the most common types of network traffic.
9. Minimal Overhead and High Speed:
Because all these checks and assignments happen inside the NIC, there’s no need for slow software tricks or manual changes. The NIC can make split-second decisions to keep traffic moving. The memory needed for the hash table is small compared to what the NIC already has, so it doesn’t slow things down or use up too many resources.
10. Simple Integration:
This approach fits right into existing NIC and RSS designs. It just adds a bit of extra logic to watch the flags and update the hash table when needed. There’s no need to redesign the whole server or write a bunch of new software. This makes it easy for data centers to adopt the innovation and see immediate improvements in network performance.
Key Benefits:
– Keeps overloaded cores from getting more work, so packets aren’t lost or delayed.
– Uses all available cores more evenly, boosting throughput.
– Adapts in real time as the server workload changes.
– Saves power and memory by only tracking what’s needed.
– Fits into current hardware and software, so upgrades are simple.
Technical Summary:
– The invention uses a flag system to indicate overloaded cores.
– The NIC’s RSS function dynamically excludes flagged cores when assigning new flows.
– A hash table tracks flow-to-core assignments, using a five-tuple index.
– The hash table is only populated when needed (e.g., when a core is overloaded).
– Optimizations allow tracking only for certain flow types, reducing memory use.
– The system applies to any number of cores and supports both TCP and QUIC flows.
– All processes run inside the NIC for maximum speed and minimal disruption.
Conclusion
This invention is a big step forward for keeping data center servers running smoothly, even as users and data demands grow. By letting the NIC watch for overloaded cores and shift new traffic away from them automatically, the system keeps network performance high and resource use balanced. It works quickly, uses little memory, and fits into the hardware and software already in use. For companies running cloud services, this means fewer slowdowns, better user experiences, and more efficient use of expensive server hardware. As more apps, devices, and users depend on fast and reliable networks, solutions like this will be key to keeping everyone happy and connected.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250365233.