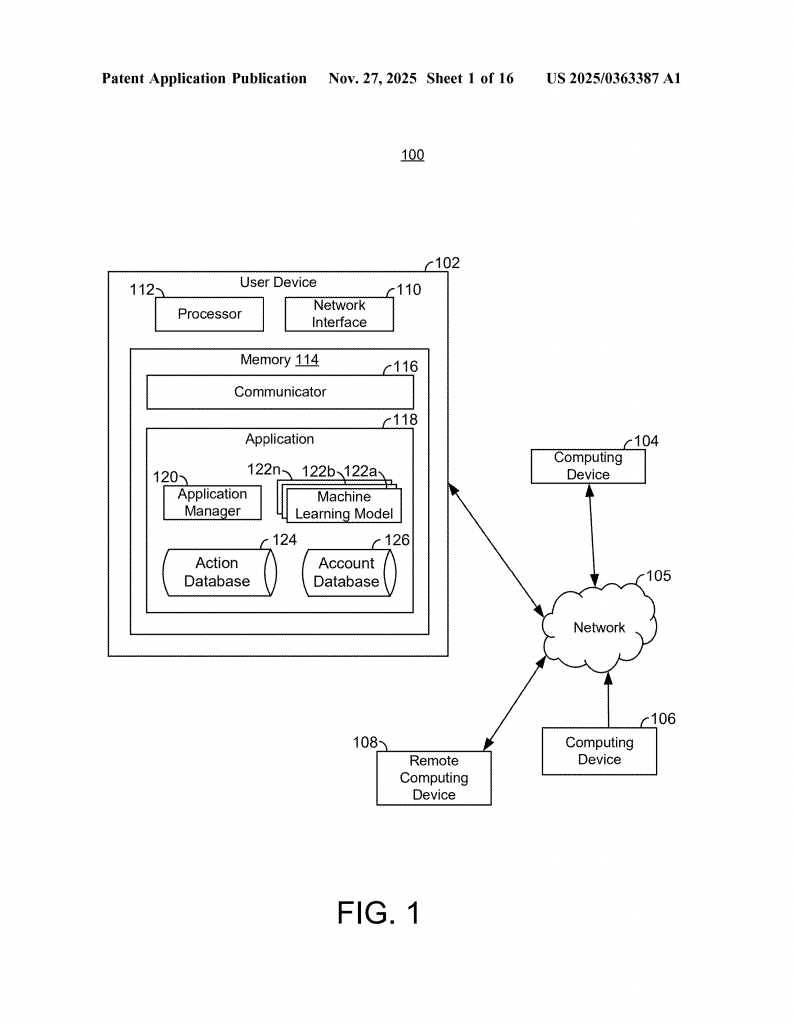
Invented by Sharma; Rahul, Kunchakarra; Narasimha ‘Murthy’ M, U.S. Bancorp, National Association
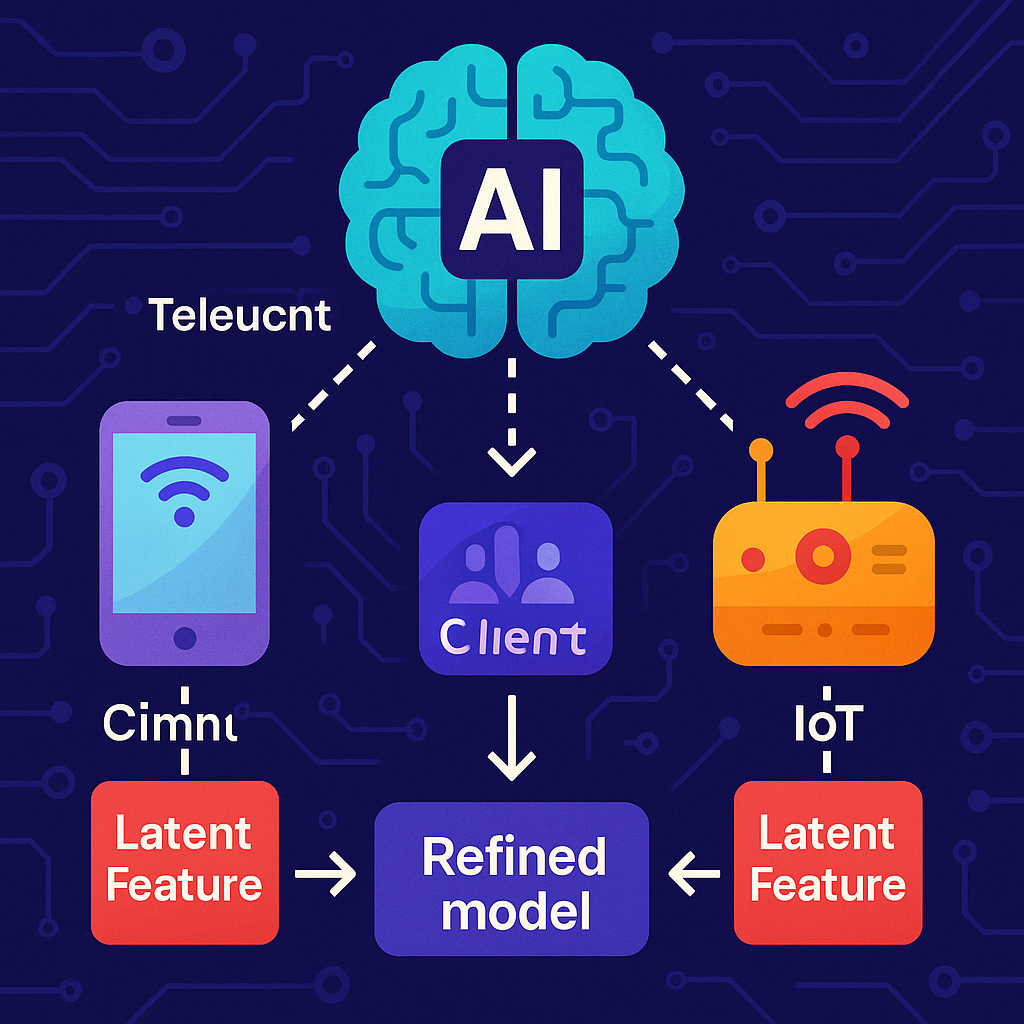
Let’s dive into a new patent application that aims to make machine learning smarter and faster by using hidden data patterns, called latent features, spread out across many devices. This technology wants to help computers learn from lots of different users, without sending too much information over the internet or making one computer do all the work. We’ll break down this idea in three easy-to-follow sections to help you understand what the invention is all about, why it matters, and how it’s different from what has come before.
Background and Market Context
In today’s world, computers are everywhere. They help us shop, bank, learn, and even play. A lot of these experiences are powered by smart systems called machine learning models. These models look at what we do and try to predict what we might want or need next, like suggesting a new movie, detecting fraud, or offering the best route when driving.
But making these models really smart takes a lot of data. Usually, all this information is sent to big, powerful servers where the models are trained. This can create some problems:
First, sending a lot of data over the internet uses up a lot of bandwidth, making things slow and sometimes expensive. Second, putting all this information in one place can make privacy harder to protect. Third, having one server do all the work can make it a bottleneck, slowing everything down when too many users are involved.
To fix these problems, a new way of learning called federated learning has become popular. In federated learning, instead of sending all the raw data to one place, small models are sent out to many users’ devices. Each device learns from its own user and sends back only small updates, not the whole dataset. This keeps data more private, spreads out the work, and can make the whole system faster.
However, even federated learning has limits. Sometimes devices still need to send too much information, or the updates are too big. Also, not all the computers are the same—some are fast, some are slow, and they all might be looking at different kinds of data. This means the system needs to be smart about what information really matters, so it doesn’t waste time and bandwidth.
This is where the new patent comes in. It focuses on picking out the most important “hidden” features from each device, sending only those, and using them to make the machine learning models better and faster. By using these special features (called latent features), the system can do more with less data, save bandwidth, and allow more devices to help with training without slowing down the network or overloading a central server.
The market for this kind of technology is huge. Banks, online stores, social networks, and health apps all use machine learning to make decisions. As more people care about privacy, and as more devices connect to the internet, there is a strong need for systems that can learn from everyone without collecting all their private details in one place. Saving bandwidth and keeping things fast and private are key selling points for these industries.
Scientific Rationale and Prior Art
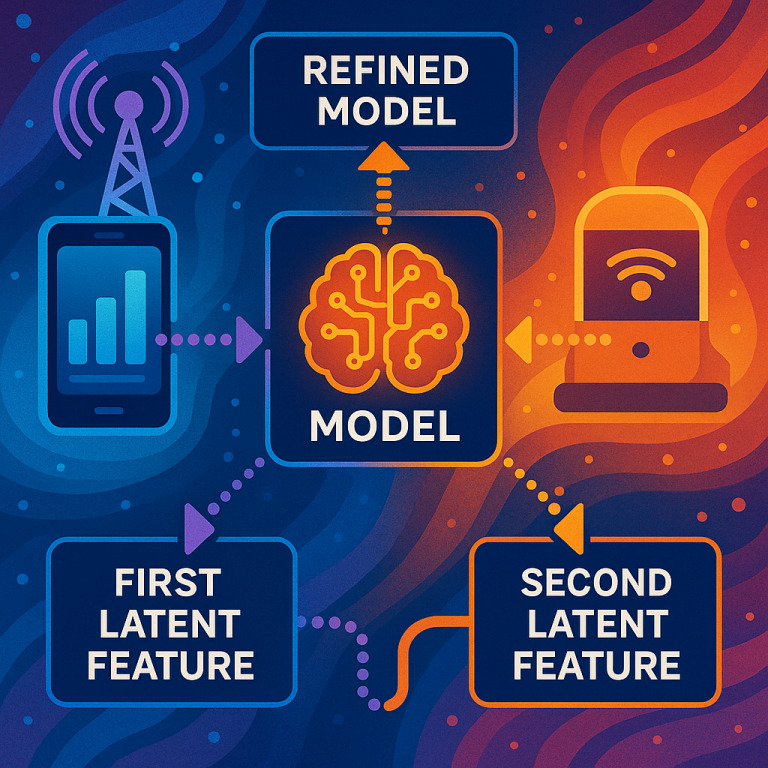
To really understand what this patent is trying to solve, let’s look at how machine learning and federated learning have worked before, and what problems have been hard to fix.
Traditional Machine Learning: In the past, when companies wanted to train a machine learning model, they would collect as much data as possible in one big database. This data could be anything from what you click on, to how long you spend in an app, to what you buy. Then, they would use powerful servers to train models that try to find patterns in all this data. The more data, the better the model—at least in theory.
But as more and more data is created, it’s hard to keep up. The servers get overloaded, the network slows down, and privacy risks grow. Not only that, but not every piece of data is equally useful. Some features—like how many times you click a button, or how fast you type—tell the computer a lot about what you might do next. Others don’t matter as much. The challenge is to find these important pieces without looking at everything.
Federated Learning: To make things better, federated learning was introduced. Here, instead of sending all the data to a central place, small versions of the model are sent to your phone or computer. Your device learns from your actions, then sends back only updates to the model—never the raw data. The central server uses these updates to improve the main model and sends out new versions to all devices.
While this helps with privacy and spreads out the work, there are still issues. When devices send back their updates, these can sometimes be very large, especially if the model is complex. If many devices are involved, the server still gets overloaded. Plus, if each device is looking at different types of actions (say, shopping vs. banking vs. social media), the updates might not even fit together very well.
Latent Features: In science, a “latent feature” is a hidden pattern or signal that is not directly seen in the data, but can be figured out by combining or transforming the data. For example, instead of looking at every click you make, the computer might figure out that “users who click the buy button after watching a video are more likely to make a purchase.” That pattern is a latent feature.
Using latent features can make models smarter and more efficient. But figuring out which latent features matter, especially when you have many devices all with different data, is hard. In the past, either the central server had to do all the work (which is slow and expensive), or only simple features were used (which makes the models less accurate).
Prior Solutions: Some systems tried to pick out important features on the device, but these often worked only when all devices had the same data, or when the features were already known. Other systems tried to compress the updates to make them smaller, but this sometimes lost important information. None of these approaches really solved the problem of picking out the best hidden features across lots of different devices, especially when those devices are very different or when privacy is a concern.
In summary, previous systems either sent too much data, put too much work on the server, or didn’t do a great job picking out the best information from each device. There was a need for a system that could let each device figure out its own most important hidden features, send back only those, and have the central server learn from all of them without getting overloaded or using too much bandwidth.
Invention Description and Key Innovations
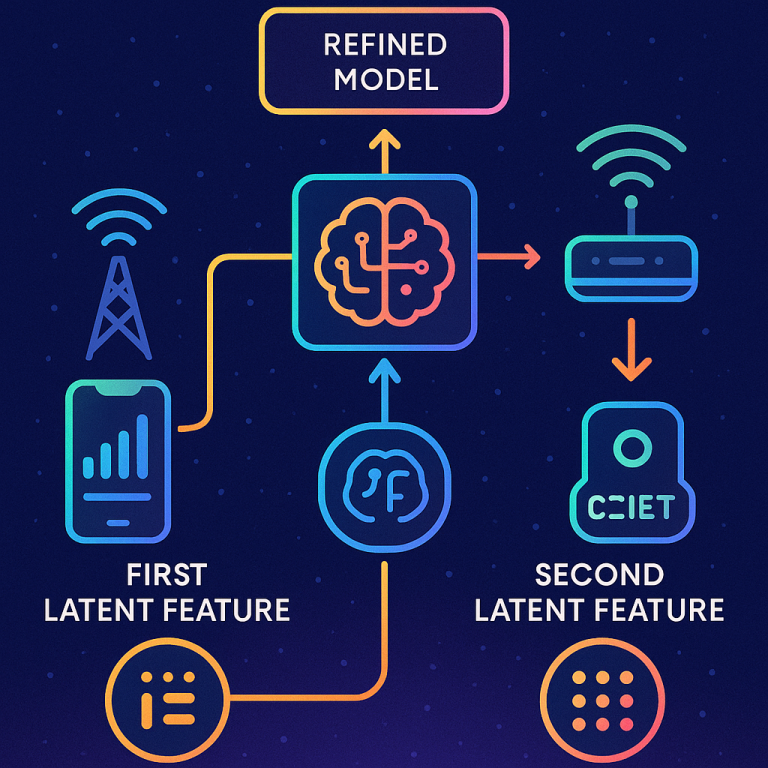
Now let’s look at what this patent actually covers, and what makes it different and better than what came before.
The Main Idea
The heart of this invention is a smart computer system that sends a learning model to groups of devices (like your phone or laptop). Each group figures out which “hidden” features in their data matter the most for making good predictions. These are the latent features. Instead of sending all their data or even all the updates, each device sends back only these key latent feature values to the central server. The server uses these to make the main model smarter, and can even tell which features are helping the most.
Here’s how it works in simple steps:
1. The central computer (server) creates or updates a learning model and sends it out to groups of devices. These groups can be based on user type, device type, or anything else.
2. Each device collects data on what the user does—like which buttons they click, how long they use the app, or what actions they take. Each device uses the model to figure out which combinations or summaries of these actions (the latent features) are most useful for predicting what the user will do next.
3. Each device sends back to the server only the values for its most important latent features. These are much smaller than sending all the raw data, and they are often more private, since they hide the details of individual actions.
4. The server collects these latent feature values from all the devices, and uses them to train or improve the main model. It can even combine latent features from different groups to learn new patterns.
5. When new data comes in, the server uses the latest model (now trained on the best latent features from everywhere) to make predictions, send messages, or trigger actions—like offering a new product, sending a security alert, or updating a user’s account.
What’s New and Different?
This approach brings several new ideas to the table:
– Each device can have its own set of latent features. Unlike old systems where every device had to send the same kind of data, now each device (or group of devices) finds the best hidden patterns for its own users. This makes the system more flexible and able to learn from many different types of users or apps.
– The system can mix and match latent features from different groups. The server can take the best features from group A and group B, and combine them into a new, smarter model. This lets it learn richer patterns that it could not see from just one set of users.
– Bandwidth is saved. Because only the most important latent feature values are sent, the amount of data moving over the network is much smaller. This is good for users (less data used), companies (lower costs), and the planet (less energy).
– Privacy is better protected. Latent features are combinations or summaries of actions, not the raw details. This makes it harder for someone to reconstruct exactly what a user did, helping keep personal data safer.
– The system can guide devices on what features to look for. The central server can send instructions to devices about which types of features to measure, or even send out parameters for autoencoders (special models that find hidden patterns automatically). This keeps all the devices working together, but still lets them find what is most useful locally.
– The system can dynamically update what features are sent. If the central model learns that some features are no longer useful, it can tell devices to stop sending those, or to start looking for new ones. This keeps the model up-to-date as user behavior changes.
– Noise filters can be applied for extra privacy. Devices can add random “noise” to the latent feature values before sending them, making it even harder to guess the original data. The system can still learn useful patterns, but personal details are better protected.
– The approach works for many kinds of machine learning models. The system can use neural networks, support vector machines, random forests, or other types of models. It can also build new layers or combine models as needed to make use of the incoming latent feature values.
– The invention supports downstream actions. Once the improved model makes a prediction, the system can trigger actions like sending a message, locking a user account, or offering a new product. This makes the system not just smarter, but also more useful in real-world settings.
Real-World Example
Imagine a bank wants to detect fraud in its app, but doesn’t want to collect every detail of every user’s transactions. It sends a model to all its customers’ phones. Each phone figures out if patterns like “high spending after midnight” or “multiple logins from new places” are good signals of fraud for that user. The phone sends back just a few numbers (the latent features) to the bank’s server. The server mixes these numbers from all users to build a better fraud detection model, without ever seeing the full list of purchases or locations. If the model spots something odd, it can alert the user or freeze the account—all quickly and privately.
Flexibility and Extensibility
The patent also covers:
– Letting devices choose latent features randomly or with special rules.
– Combining features from different types of models.
– Training new models that use only latent features, or mixing latent and raw features.
– Adding or removing features and models as user needs or behaviors change.
This makes the system ready to grow as new devices, apps, and user behaviors appear.
Conclusion
This patent application presents a smart and efficient way for computers to learn from many users, without putting too much load on any one server or sending too much data over the network. By letting each device pick out its own most important hidden features, and sending only those to the central computer, the system saves bandwidth, protects privacy, and builds better machine learning models. It’s a powerful step forward for federated learning, making it more practical for big, diverse networks where privacy and speed both matter.
If you are building apps or services that rely on machine learning, especially across many devices, this technology could help you serve your users better, keep their data safer, and keep your costs down. As more devices and smarter apps appear in our daily lives, approaches like this will be key to making sure machine learning stays both smart and responsible.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363387.