Invented by Galvin; Brian
Understanding how to make artificial intelligence run faster, use less energy, and keep our data safer is one of the big goals in tech today. A recent patent application sets out a way to do this using “hierarchical smart caching” for machine learning codeword responses. In simple words, this means building a system that remembers answers to questions (prompts) in a smart way, so that when similar questions come up again, the computer can reply quickly, securely, and without having to do all the work from scratch.
Let’s break down this new invention, why it matters, and how it fits into the bigger world of AI and data security.
Background and Market Context
We are living in a time when computers are asked to do more and more, especially when it comes to understanding language, pictures, sounds, and even numbers from sensors. Companies want to use AI to answer questions, analyze trends, make predictions, and help people in real-time. But the biggest challenges are speed, privacy, and cost.
Think about using a voice assistant on your phone, or an AI chat system on a website. When you ask a question, you want a smart answer right away. Behind the scenes, these answers often come from huge computers in the cloud, which process your question, look for patterns, and generate a reply. But what if your device could remember good answers from before, so it doesn’t have to “think” as hard every time? What if your device could also share what it’s learned with other devices, making the whole network smarter, all while keeping your private information safe?
This is important not just for consumers, but also for hospitals, banks, and factories. In healthcare, for example, patient data is private and can’t be shared easily. In finance, security is everything. In both cases, a system that can process information, remember smart answers, and keep everything private is a game-changer.
As more devices become “smart”—phones, watches, cars, even refrigerators—there is a need for these devices to do more on their own (this is called “edge computing”). They need to answer questions and make decisions locally, but also learn from each other without sending too much data back and forth. The market is racing towards faster, safer, and more private AI that can scale across millions of devices.
That’s where this new patent comes in. It offers a blueprint for a computer system that “remembers” answers, shares them smartly, saves time and power, and protects user privacy. This is not just a win for speed and cost, but also for trust and security—two things every industry cares about.
Scientific Rationale and Prior Art
The core of the invention is built on top of three main ideas from the world of computer science:
1. Deep Learning and Transformers:
AI models called deep neural networks, and especially a type called transformers, are the engines behind modern language models (like ChatGPT), image recognition, and many other smart systems. Transformers break down input (like a sentence) into pieces (tokens), and use layers of math to understand how these pieces relate to each other. They can generate smart, context-aware answers.
2. Data Compression and Encryption:
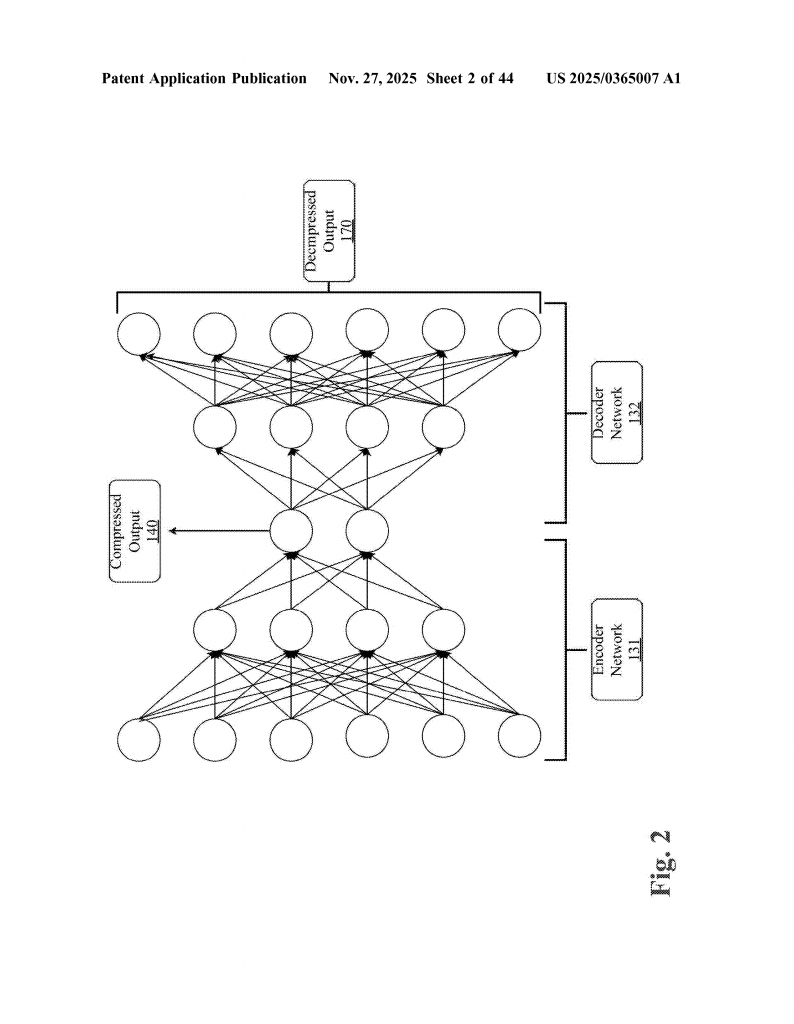
A big problem with AI is that it often needs lots of data and computing power. To save space and speed things up, systems use data compression. But when privacy is important, you can’t just compress—you also need to encrypt (scramble) data so no one can see the private details. Some advanced methods, like homomorphic encryption, let you do math on encrypted data without ever decrypting it. Variational autoencoders (VAEs) are a type of neural network that can “squeeze” data into a smaller, hidden form (latent space) and then “unsqueeze” it back, while preserving important features.
3. Caching and Smart Memory:
Web browsers and servers have long used caches—a kind of memory that stores answers to common questions so they can be reused quickly. But caches can be dumb (just storing exact matches), or they can be smart (finding similar answers, learning which ones are most useful, and sharing across systems).
Past research and patents have focused on each of these areas. There are systems that use transformers for deep learning; there are methods for encrypting and compressing data; there are caching systems for web pages and distributed databases. Some companies have looked at privacy-preserving AI, where you can train models on encrypted data. Others have tried to make AI models faster on edge devices by pruning (shrinking) models or using more efficient math.
But putting these pieces together—combining deep learning, strong compression/encryption, and a multi-level, smart caching system for AI responses—is new. What’s different here is the use of “codewords” (compressed representations of tokens), the ability to store and reuse responses at both the device and network level (local and global caches), and the use of relevance scoring and context aggregation to make the cache truly smart.
Previous work might have let you store results, but it didn’t always handle privacy, security, and efficiency together. Nor did it offer a way to share knowledge safely across many devices, or adaptively learn which cached answers are most important. This invention leverages recent breakthroughs in AI, encryption, and distributed systems, and marries them into a system that is more than the sum of its parts.
Invention Description and Key Innovations
Let’s look at how this new system works, using simple words.
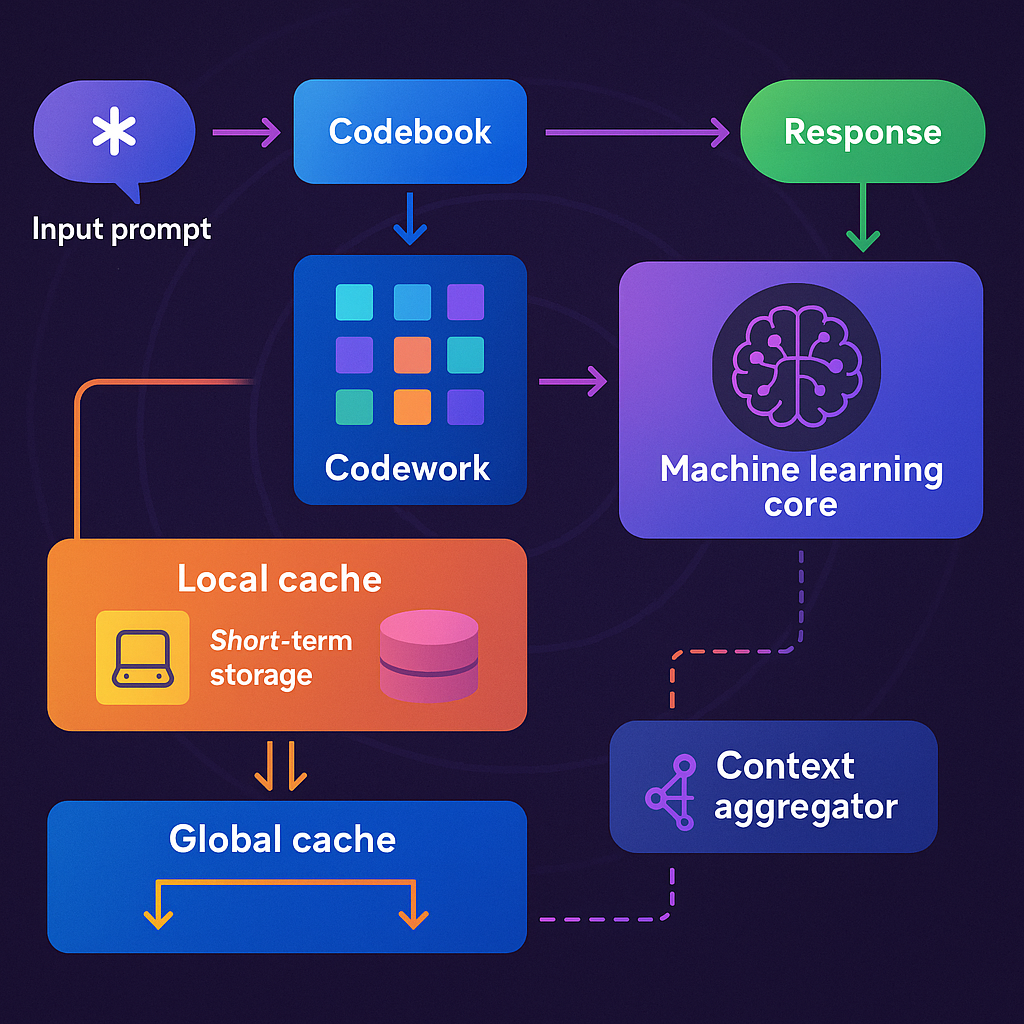
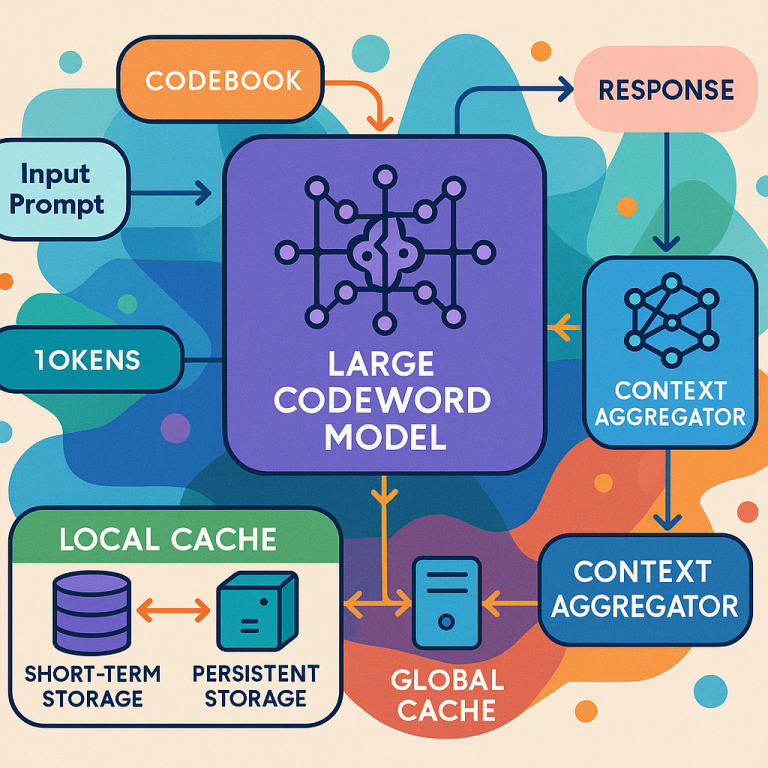
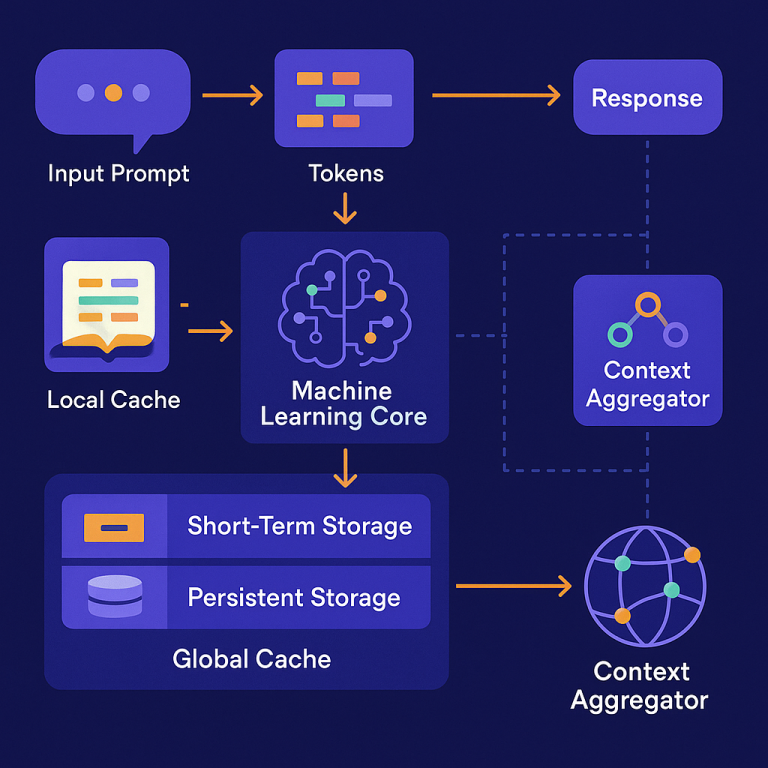
Imagine a computer that gets a question (prompt) from a user. First, it breaks this question into tokens (like words or smaller pieces). Each token is then turned into a “codeword” using a codebook—a kind of dictionary that maps tokens to special, compressed codes. This makes the data smaller and more manageable.
These codewords are then processed by a machine learning core. This core can be one of two types:
- A conventional transformer (like in most language models), which uses embedding and positional encoding layers to understand the sequence and meaning.
- A latent transformer core, which uses a variational autoencoder (VAE) to compress the codewords into an even smaller, hidden space (latent vectors), and then runs a transformer on these vectors. This is useful for high-dimensional data, and skips some steps to save time and power.
Once the core processes the codewords, it creates a response, also in codeword form. Here’s where the caching magic happens:
Hierarchical Caching:
The system stores these codeword responses in two places:
- Local cache: This is on the device itself (like your phone or laptop). It remembers recent or frequently used responses, so if you (or your app) ask a similar question again, it can fetch the answer instantly without running the AI model again. This saves time and battery.
- Global cache: This is shared across many devices or users (like in the cloud). It stores responses that are useful to more than one person or device. This lets the whole network get smarter over time. For example, if someone else already asked a question similar to yours, you might get their answer (if allowed).
Each cached response is scored for relevance—how likely it is to be useful again. Old or rarely used answers get pruned (removed), while the best ones are kept and shared. When a similar prompt comes in, the system first checks the local cache, then the global cache, and only runs the full AI model if needed. This reduces computation, saves money, and speeds everything up.
Context Aggregation:
The system also looks for connections between cached answers. If several related questions have been asked, it can combine their answers to build a richer, more complete response. This is handled by a context aggregator, which uses pattern recognition and relationship mapping to link related responses.
Security and Privacy:
All data is compressed and encrypted using advanced methods (like homomorphic and dyadic encryption), so even when answers are stored in the cache or shared between devices, private information stays safe. The system uses cryptographically secure random numbers and can protect against side-channel attacks (where hackers try to infer secrets by watching how the computer behaves).
Smart Adaptation:
The system is designed to learn and adapt over time. It tracks which cached answers are most useful, updates relevance scores, and continuously refines how it stores and retrieves responses. It can also learn new codewords as new types of data come in, and expand or shrink the cache as needed.
Multi-Modality:
While most of the description uses text as an example, this system can work with all sorts of data—images, audio, sensor data—by mapping each type into codewords and handling them through the same pipeline. This makes it flexible and future-proof.
Edge and Cloud Synergy:
Because the system can run on both edge devices and in the cloud, it gives you the best of both worlds: fast, local answers when possible, and shared, network-wide intelligence when needed. Devices can work offline using their local cache, and sync up with the global cache when they reconnect.
Key Innovations Summed Up:
– Turning all inputs into codewords for efficient, secure processing.
– Using both local and global caches to store, score, and share AI responses.
– Applying advanced encryption so data can be processed and shared without exposing secrets.
– Scoring and pruning cached responses for maximum efficiency.
– Aggregating context from related answers for better, richer responses.
– Supporting multiple data types (text, images, audio, etc.) with the same pipeline.
– Allowing the system to run on both edge devices and in the cloud, with smart syncing.
This approach dramatically reduces the need to redo expensive AI computations, saves energy, speeds up replies, and keeps user data private and secure. It’s not just a smarter cache—it’s a new way for AI systems to learn, remember, and share knowledge safely across the entire network.
Conclusion
This invention is a leap forward in making AI systems faster, safer, and smarter. By combining deep learning, strong data compression and encryption, and a truly intelligent two-level caching system, it opens the door to AI that can scale across millions of devices, save money and energy, and keep our private information safe.
In a world where every second counts and privacy is gold, this system shows how remembering and sharing the right answers—in the right way—can make all the difference. Whether in healthcare, finance, consumer gadgets, or the smart factories of tomorrow, hierarchical smart caching for machine learning codeword responses could become the backbone of the next generation of AI.
If you’re building or using AI systems and care about speed, cost, privacy, and scalability, this is a technology to watch.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250365007.