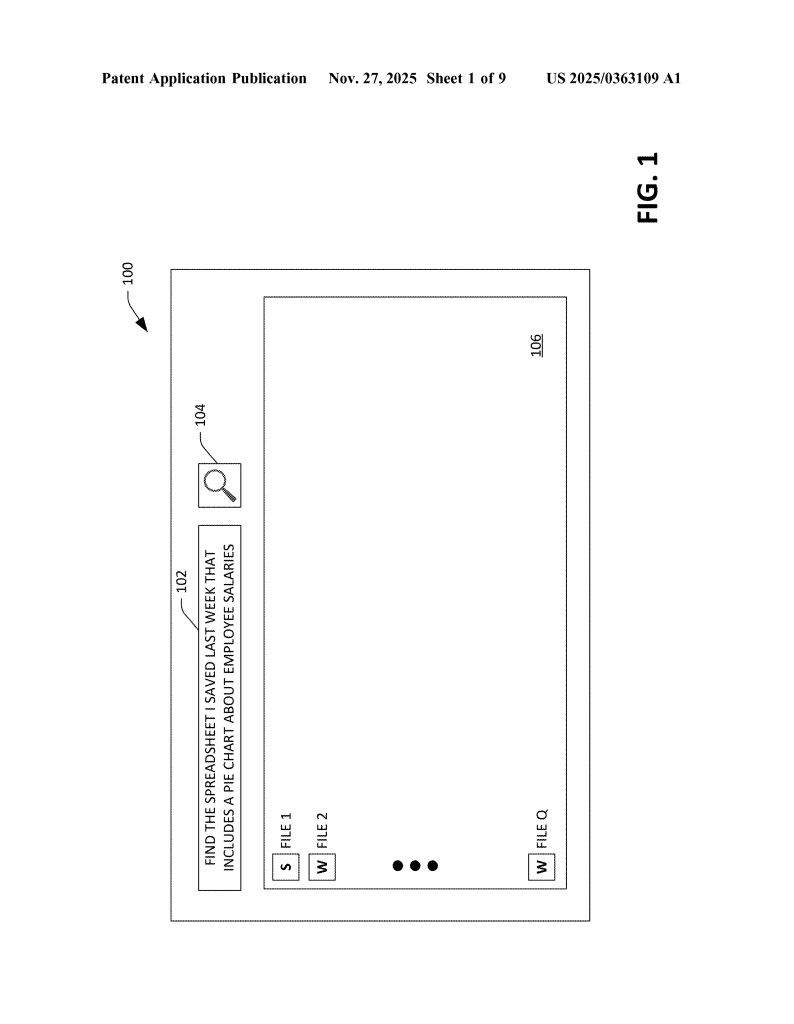
Invented by LI; Yinheng, Wagle; Justin James, Koishida; Kazuhito
It’s no secret that searching for files on your computer or in the cloud can be a nightmare. You type in what you remember, but the results just don’t match what you meant. A new patent application is trying to change this, letting computers understand the real meaning behind your words, even when your files include text, pictures, or charts. Let’s break down this invention, why it matters, how it builds on what came before, and what makes it special.
Background and Market Context
Today, we all depend on digital devices to store important files. From work reports to family photos, school projects to business presentations, everything is somewhere on a computer, phone, or in the cloud. But there’s a big problem: finding what you need, when you need it, is still much harder than it should be.
Most people use simple search tools. These tools can find words that match what you type. If you search for “cat adoption,” the computer looks for files with those exact words. But life isn’t that simple. What if you want the slide show your friend Tom sent you last month about pet adoption — the one that had a picture of a cat? If you just type “cat adoption Tom slide show last month,” most computers will either give too many files or none at all.
Here’s why: computers are good at matching words, but not very good at understanding what those words mean together. They struggle when you include more than one type of thing in your search, like when you want both text and images, or when your question is written the way you would talk to a friend.
In today’s world, people expect more from technology. Smart speakers and AI chatbots seem to understand us, so why can’t our file searchers? That’s where this new invention comes in. The patent describes a system that goes beyond matching words. It tries to understand the meaning behind your search, even if your files include different types of content — like text, images, charts, or audio. It’s a big step toward making computers search the way people think.
This is important for everyone, not just tech experts. Businesses lose time and money when workers can’t find what they need. Students get frustrated when they can’t locate the right notes or presentations. Even at home, finding a single photo hidden inside a big document can feel impossible. The market is huge, and the demand for smarter search is only growing.
Companies like Google, Microsoft, and Apple have all tried to make search better. But even their tools mostly use simple keyword matching. Some have begun using AI to understand language, but true multimodal search — where the computer understands both words and pictures, or words and charts — is still rare.
The patent application we’re exploring aims to solve this. It describes a new way to let computers search across different types of content at the same time, using both keywords and the real meaning behind your search. If it works as promised, it could change the way we all interact with our digital stuff.
Scientific Rationale and Prior Art
To understand the invention, we need to know how computer search works now, and what problems exist with older methods.
Most search tools use something called an “inverted index.” This is a big list that maps every word in your files to the places where those words appear. It’s fast and works well when you know the exact words you want to find. But it has limits. If you don’t use the same words, or if you’re looking for something that’s described in a different way, you might not find it.
Let’s say you’re searching for “cat adoption,” but the file says “finding homes for kittens.” A normal search might miss it, even though it’s the same idea. And if the file is mostly a picture with very little text, or a chart with almost no words, traditional search tools might not help at all.
Some newer systems use “semantic search.” This means the computer tries to understand what words mean, not just how they’re spelled. These systems turn words into “embeddings,” which are like maps of meaning. For example, “cat” and “kitten” would be close together in this map, so searching for one might find the other.
Still, even semantic search systems are mostly built for one kind of content at a time — usually text. If you want to search for both words and images, or for files that have both, the system often fails. That’s a problem because most files today mix different kinds of content. Think about a school project: it might have text, charts, and pictures all in one document.
There are also tools that do image search, but these usually look for pictures that match other pictures, not pictures that match words. Some systems use “object character recognition” (OCR) to pull text out of images and then search those words. But they don’t combine all these methods in a smart way.
The patent we’re looking at brings together several ideas from past work:
1. Using inverted indexes for quick keyword matching.
2. Using embeddings to understand meaning and find related content.
3. Applying these methods to different types of content, like text and images.
4. Searching all these indexes at once, so you can find files that match your search in more than one way.
The big leap here is combining all these steps. Instead of searching just one list, the system searches several. It looks at both the actual words and the real meaning, across text, images, and maybe more. It can even figure out what kind of thing you’re looking for — for example, a spreadsheet, a chart, or a photo inside a document. All of this happens quickly and in parallel.
This approach builds on older patents and products, but it’s more complete. It doesn’t just improve keyword search or add semantic search on top. It creates a bridge between the two, and lets the computer use both at the same time, for many types of content.
Another important point is that this system can be used on your own computer, or on a server in the cloud. It can work for one person or for many users at once. It’s flexible, and that makes it powerful.
Finally, the system can filter and rank results, so the most relevant files show up first. It can even learn what you mean when you type a complex question, using AI to pick out keywords and spot which types of content you care about most.
All these pieces have existed in one form or another, but not together, and not in a way that works for natural, human-like search across all your digital stuff.
Invention Description and Key Innovations
Now let’s dive into what the patent actually claims and why it’s a breakthrough.
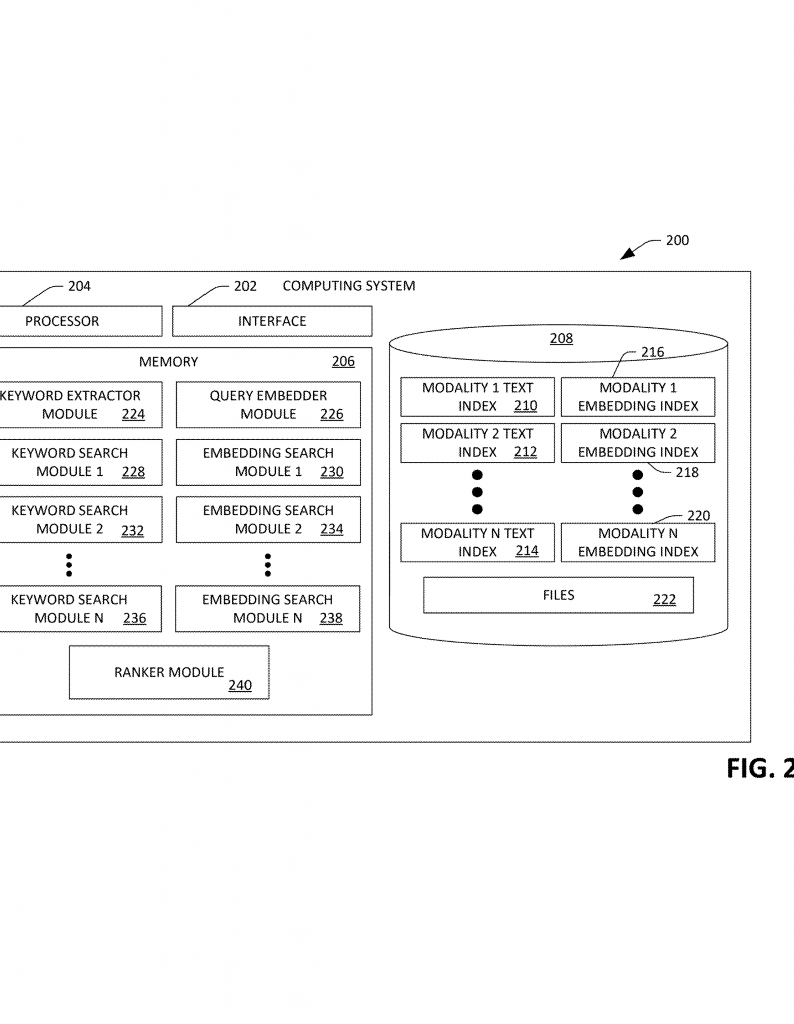
The invention is a computing system — it could be a desktop, a phone, a server, or any computer — that helps you find files based on what you say or type, even if your search is long and complicated. The system is built around a few main ideas.
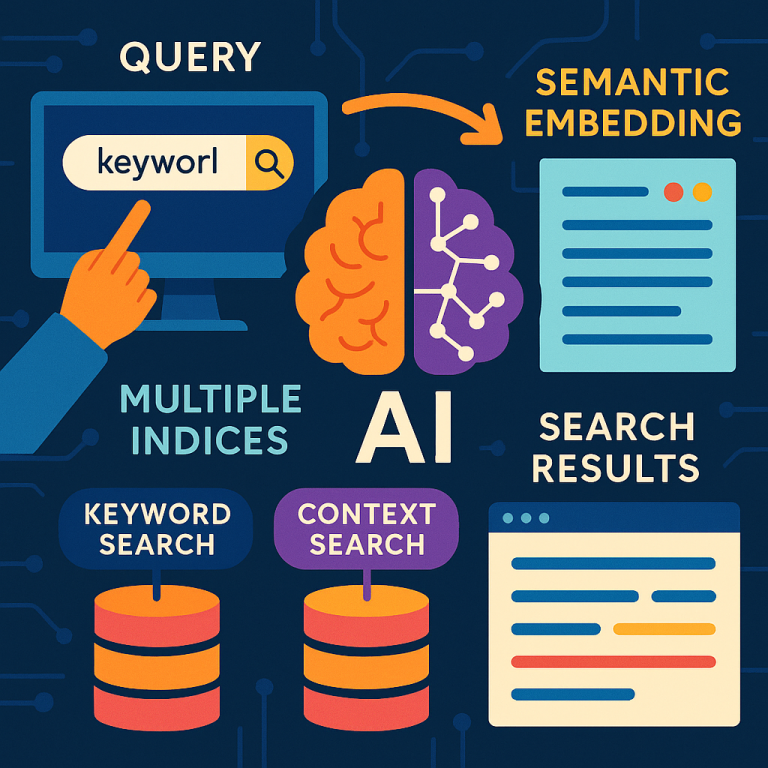
First, the system keeps several “indexes.” Think of an index as a special list that helps the computer find things quickly:
– There’s a text index for words found in your files (like normal search).
– There’s an embedding index for the meaning of those words (semantic search).
– There’s an index for words pulled out of images (using OCR).
– There’s an embedding index for the meaning of the image content.
When you enter a search, the system does a few smart things. It pulls out keywords from your search, using something called “named entity recognition.” This just means the computer figures out the important words or names in your question. At the same time, it creates an “embedding” of your whole search — a kind of map that shows the meaning behind your words.
The computer then searches all the indexes at once. It uses the keywords to look in the text index and the image text index. It uses your search embedding to look in the embedding indexes, both for text and images. All these searches happen in parallel, so there’s no waiting for one to finish before the next starts.
The results come from each search. The system gives each result a score, based on how well it matches your search. For example, a file with the exact words you typed gets a high score in the keyword search, while a file whose meaning is close to your search gets a high score in the embedding search.
But here’s the clever part: the system combines these scores, using weights that depend on what kind of thing your search is really about. If your search sounds like you want a picture, the system gives more weight to the image scores. If it’s about a chart, it boosts the chart scores. It figures this out using a “modality detector,” which is just a way to guess what types of content you care about most.
Once all the files are scored, the computer ranks them. The best matches go to the top. The system can also filter out files that don’t fit your request. For example, if you asked for a spreadsheet, it can hide everything that’s not a spreadsheet. If you asked for files from last week, it ignores older files.
This whole process can happen on your own computer, or on a server that serves many users. It can be used for searching your own files, or in a company where many people need to find things at once. It works for all types of files — documents, images, charts, audio, and more.
There are a few key innovations here:
1. Searching multiple indexes at once, for different types of content, using both keywords and meaning.
2. Combining the results in a smart way, giving more importance to the types of content most relevant to your search.
3. Using AI to pull out keywords, create embeddings, and guess which types of files you’re really looking for.
4. Applying OCR to images, so the text inside pictures can be found just like words in documents.
5. Letting the system work on any computer, or in the cloud, for one user or many.
6. Ranking and filtering results, so you see only what matters most, in the order that makes sense.
The patent also covers ways to update the indexes automatically, so new files or changes to old files get included. The process can run in the background, so you don’t have to wait. The system can split big files or images into smaller pieces, making it easier to find the exact bit you want.
The end result is a search tool that understands you, no matter how you ask or what kind of content you want. It acts almost like a human assistant who knows every detail of your files and can find what you need in seconds.
Conclusion
This patent application is all about making computers smarter and friendlier. By combining keyword matching, semantic understanding, and multimodal search, the invention lets you find files the way you think, not just the way the computer wants. Whether you’re a business owner, a student, or just trying to find a photo in an old email, this system could change the way you interact with your digital world. It’s a leap from the old days of basic search, opening the door to a future where computers really “get” what we mean.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363109.