
Invented by Li; Yun, Rusanovskyy; Dmytro, Karczewicz; Marta
Video is everywhere. Our phones, TVs, computers, and even billboards rely on fast video decoding. But as video resolution climbs and devices shrink, decoding must get smarter and more efficient. A new patent application introduces a game-changing way to use neural networks for video decoding—one that’s both powerful and perfect for today’s hardware. Let’s dive into what this means, why it matters, and how this invention stands out from what came before.
Background and Market Context
Video has become the world’s main form of communication. People stream movies at home, join video calls for work and school, and share clips on social media. Every device—from high-end TVs to pocket-sized phones—needs to decode video quickly and smoothly. As more people demand 4K, 8K, and even higher resolutions, devices have to work harder. The challenge is to make this happen without draining batteries, overheating chips, or making devices more expensive.
Modern video devices use advanced methods to pack video data tightly (encode) and then unpack it for viewing (decode). Common standards like MPEG-4, H.264/AVC, H.265/HEVC, H.266/VVC, and AV1 help devices play video in the smallest possible file size without losing too much quality. These standards are used in everything from TV broadcasts and streaming services to gaming consoles and mobile phones.
Video coding works by breaking pictures into small blocks. Each block is predicted using data from nearby blocks (spatial prediction) or from earlier/later frames (temporal prediction). After prediction, the difference (residual) between the original and the predicted block is stored. This process saves space but can add visible blockiness or blur, especially when the video is highly compressed.
To fix these problems, devices use filters after decoding. These filters smooth out block edges and remove noise, making the video look better. Filters like deblocking, sample adaptive offset (SAO), and adaptive loop filtering (ALF) are common. But as video keeps getting more detailed, traditional filters struggle to keep up. They can’t always remove all the artifacts, and they may not be flexible enough for every kind of video.

That’s where neural networks come in. These are computer programs that learn from data, just like our brains. They can find patterns and fix problems that old filters miss. But there’s a catch: neural networks, especially those with attention mechanisms (which help focus on the most important parts of an image), often use operations that are hard for chips to process efficiently. This can slow down decoding and use more power—bad news for phones, laptops, and other portable devices.
The market is hungry for a solution that brings the power of neural networks to video decoding, but in a way that’s simple, fast, and works well on all kinds of devices. This patent application aims to deliver just that.
Scientific Rationale and Prior Art
Neural networks, especially convolutional neural networks (CNNs), have started to change how video is processed. They can learn from millions of examples to remove noise, sharpen images, and even fill in missing details. CNN-based filters already outperform basic filters in many tests.
Recently, “attention” mechanisms, first made famous by transformer models in natural language processing, have been adapted to images and video. Attention lets the network focus on the most important or relevant parts of the data, capturing long-range relationships and subtle details. In video, this can mean better handling of motion, lighting changes, and complex textures.
But using attention in neural networks for video has a downside. Typical attention blocks rely on operations like normalization (to keep data in a certain range) and functions like exponentials and square roots. These are slow and power-hungry on most chips. They also make it hard to use fixed-point math (which chips prefer for speed and energy savings). As a result, even though attention helps, it’s often left out of real-world video decoders.
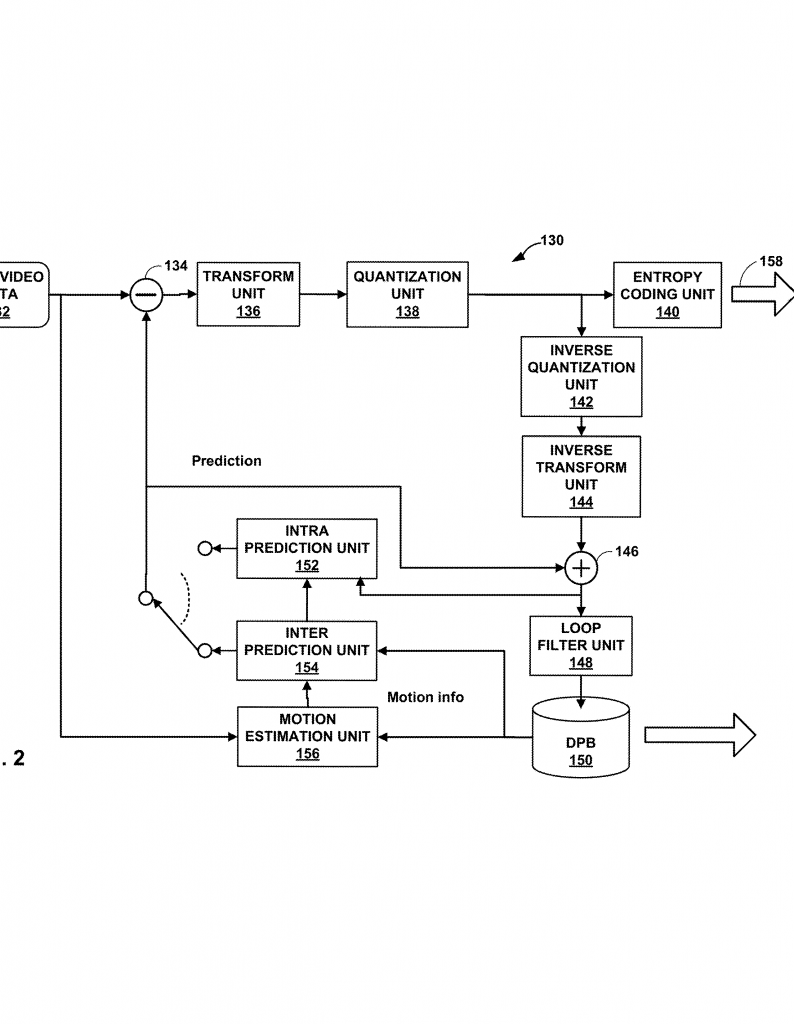
Earlier patents and standards have proposed using CNN-based filters for deblocking and denoising. Some have tried adding attention blocks, but they usually keep the complex operations, making hardware implementation tricky. Attempts to “quantize” (simplify) these networks often lead to lower accuracy and more video artifacts.
A few recent papers have suggested using “lightweight” attention, but they usually trade quality for speed, or they still require some form of normalization or non-linear math. No prior art has shown an attention block that completely skips normalization, uses only multiplication and addition, and still competes with the best filters in quality—all while being simple to build into chips.
The new invention tackles this problem head-on. It introduces an attention block that drops normalization and fancy math entirely. It processes raw, non-normalized data and sticks to just multiplication and addition. This makes it much easier and cheaper to implement in hardware, especially for mobile and embedded devices. By fitting attention neatly into the filter architecture without the usual baggage, this invention brings state-of-the-art neural filtering to everyday video decoding.
Invention Description and Key Innovations
Let’s break down what this patent application brings to the table—and how it changes the game for video decoding.
1. Neural Network-Based Filter with Backbone and Attention Blocks
At the heart of the invention is a neural network filter designed for video decoding. The filter is made up of several “backbone” blocks—think of these as the main building blocks of the filter. Each backbone block processes part of the video and passes the result to the next block. This design is inspired by “ResNet” architectures, popular in deep learning for their stability and performance.
But here’s the twist: at least one of these backbone blocks contains a special “attention” block. This attention block is different from the ones used in other neural networks.
2. The Hardware-Friendly Attention Block
Traditional attention blocks use normalization and non-linear math. This patent’s attention block skips all that. It does not normalize the input data—it works directly on raw data as it is. Inside, it only performs two types of operations: multiplication and addition. There are no exponentials, no square roots, and no softmax layers. This is a big deal, because multiplication and addition are very fast and easy for chips to handle.
This simple design makes the attention block much easier to build into real hardware, like the chips inside your phone or TV. It also means the filter can be quantized for even faster processing, without losing much (or any) quality.
3. Integration with CNN Layers
The attention block isn’t just bolted on. It’s carefully integrated with convolution layers that come before it. These layers work together to generate the “query,” “key,” and “value” inputs that attention needs—similar to how advanced transformer models work, but again, with only multiplication and addition.
4. Flexible Architecture for Real-World Devices
The filter can be made up of multiple backbone blocks (for example, 24), with one or more attention blocks placed at key points (such as after the 7th and 14th block, in one example). This lets designers choose the best balance between speed and quality for their device. The invention also describes how the attention block can be placed in luma (brightness) and chroma (color) branches, and how the number of channels and blocks can be tuned for different hardware targets.
5. Works with All Modern Video Standards and Devices
This invention isn’t locked into any one video format. It can be used with existing standards like H.265/HEVC, H.266/VVC, AV1, and their successors. It works during both encoding (when video is created or compressed) and decoding (when video is played back). It can be added to all sorts of devices, from cameras and set-top boxes to phones, tablets, TVs, and even servers.
6. Simple to Use and Deploy
The filter can be built into dedicated chips, run on processors, or even used as software. Because it avoids complex math, it is much easier to optimize for battery-powered devices. The patent also covers how the filter can be stored as software instructions or as part of a hardware design.
7. Actionable Impact
If you design chips for video, this invention makes it much easier to include powerful neural network filters with attention. You don’t need to worry about supporting tricky math operations, and you can keep your chip’s power and cost down. If you write video software, you can deliver better quality on more devices, with less code and fewer headaches.
If you’re a device maker, you get the best of both worlds: the flexibility and quality of neural networks, and the efficiency needed for real-world products. And for viewers? It means smoother, clearer video on every device, no matter how demanding the content.
Conclusion
This patent application marks a big step forward for video decoding. By rethinking how attention blocks work inside neural network filters, it brings top-tier video quality to every device—without slowing things down or wasting energy. The key is simplicity: using only multiplication and addition, and processing data as-is, the invention sidesteps the roadblocks that have held back neural filters in the past.
For chip designers, software developers, device makers, and anyone who cares about video quality, this is welcome news. It means high-quality video that’s fast, efficient, and ready for the next wave of high-resolution content. As video keeps growing, inventions like this will be crucial in making sure technology keeps up—delivering the best experience to everyone, everywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220209.