
Invented by Liu; Juncheng, Woo; Gerald, Liu; Chengao, Sahoo; Doyen
Predicting what will happen next is at the heart of many smart systems today. From weather to stock prices, from traffic to machines in a factory, being able to see into the future, even if just a little, is very valuable. A new patent application shows a fresh way to use neural networks for predicting things that change over time, especially when there are many things changing at once. In this article, we’ll break down what makes this invention special, how it compares to older ideas, and why it matters.
Background and Market Context
Let’s start with a simple question: Why do we care about time series forecasting, and why is it so tricky when there are lots of things changing together?
In the real world, things rarely happen in isolation. Think about a city’s traffic. The flow of cars on one street affects another. The weather, time of day, and even special events all play a part. Now imagine you want to predict what traffic will look like an hour from now. You can’t just look at one street or one factor. You need to consider everything — all at once. This is what we call multivariate time series forecasting: predicting the future when there are many things (or “variates”) that change together over time.
The need for better forecasting tools has exploded recently:
- Telecommunications: Network providers want to predict internet traffic to avoid slowdowns.
- Finance: Investors use forecasts to make smarter trades or spot risks ahead of time.
- Manufacturing: Factories monitor machine sensors to prevent breakdowns before they happen.
- Smart cities: Planners look at energy use, traffic, and public safety data to make cities run better.
The challenge is not just having lots of data, but making sense of how these different signals are connected and change together. Old methods could handle one piece at a time, or maybe a few together, but as the number of variables grows, things get complicated very fast.
The market wants tools that are fast, accurate, and can work with huge, complex data sets. These tools should also be able to adapt, so as data patterns change, the predictions don’t get stale. This is where new neural network designs, especially those inspired by recent advances in artificial intelligence (AI), come in. The invention in this patent aims to fill this gap: to make better, faster, and more flexible forecasting possible for everyone from network engineers to business leaders.

Scientific Rationale and Prior Art
Let’s look at how people have tried to solve this problem before, and why those attempts haven’t been good enough.
The classic approach to forecasting is to use statistical models. These models — like ARIMA, or even simple linear regression — work fine if you’re only looking at one thing, like the temperature or the price of a stock. They can sometimes work for a few related things, but when you have dozens or hundreds of variables, they struggle. They don’t always “see” connections between things that aren’t obvious.
More recently, machine learning has changed the game. Neural networks, and especially a design called the Transformer, have shown they can handle complex data. Transformers were first made for language — to translate sentences or answer questions. But because they can “pay attention” to different parts of the data at once, people started using them for time series too.
Here’s how most existing methods work:
First, they break the data into small chunks, called “patches.” Then, they use the Transformer’s attention mechanism to look for patterns. The attention mechanism lets the model focus on different parts of the data, capturing relationships that might be missed otherwise.
However, these Transformer-based methods have big problems when it comes to multivariate data — that is, when you have lots of different time series all together. The main issues are:
- Missed Connections: Most models either look at each variable on its own (“intra-variate”), or only consider simple links between variables (“cross-variate”). They don’t do both at the same time, so they might miss important signals that come from the way different variables interact over time.
- Memory Overload: Transformers are powerful but expensive. When you flatten all your data and try to connect every patch to every other patch, memory use grows very quickly — what experts call “quadratic complexity.” For big data sets, this means you can run out of memory fast, even on the best computers.
- Indirect Learning: Some methods use two separate attention steps — one for time, one for variables — but this is clunky. It doesn’t let the model directly learn the fine-grained, patch-level connections between different variables and time periods.
Several research works have tried to fix these issues. For example:
iTransformer and PatchTST use different attention strategies. FEDformer and Crossformer add special ways to handle frequency or cross-dimension information. These are improvements, but they still run into the same basic problems: They either can’t handle the full richness of the data (so they miss hidden patterns), or they use too much memory.
What’s missing is a model that can:
- See both types of connections at the same time, for every little piece of data (every patch).
- Handle lots of variables without blowing up memory use.
- Learn these connections directly, not in a roundabout way.
This is where the new invention steps in. It offers a unified way to learn all these connections, using a special mechanism called a “dispatcher,” which keeps memory use low while still letting the model learn everything it needs to know.
Invention Description and Key Innovations
Now let’s explore what this patent application introduces, and why it’s a real step forward for time series forecasting.
At its core, the invention describes a method and system for training a neural network to predict time series data, especially when you have a lot of variables that all change over time.
Here’s how it works, in simple terms:
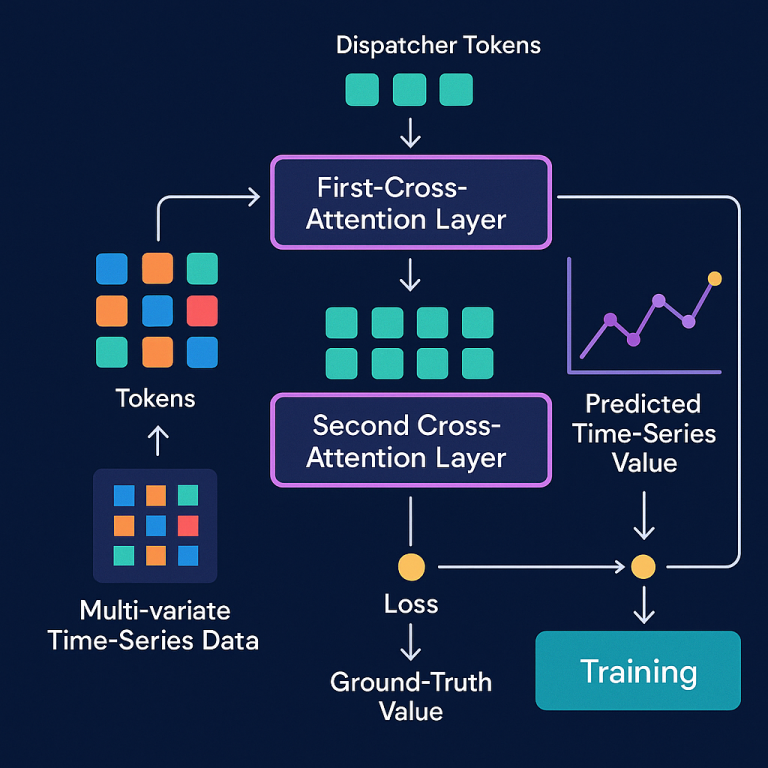
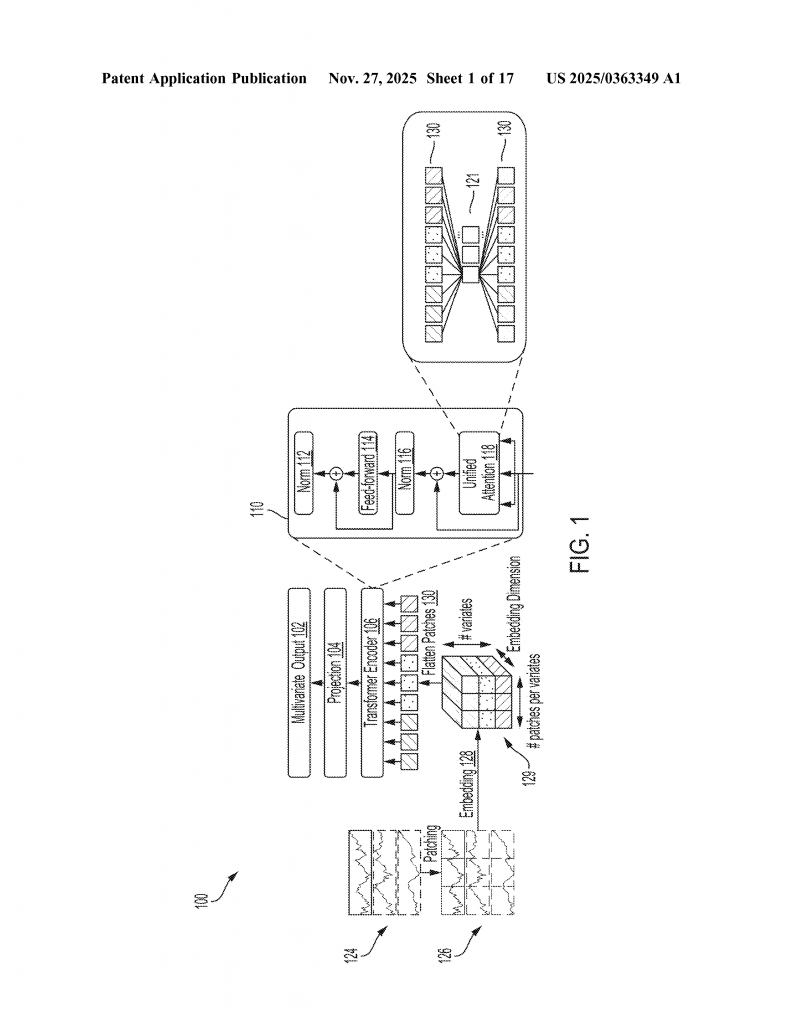
1. Data Preparation: Flatten and Patch
The system takes in multivariate time series data. Imagine a big table where each row is a variable (like temperature, humidity, wind speed, etc.), and each column is a time step. The data is first split into small “patches” — chunks of time for each variable. These patches are then “flattened” into a long sequence, mixing up all the variables and time periods together. Each patch is turned into a “token,” which is just a way for the neural network to treat it as a single unit of information.
2. Embedding and Position Encoding
These tokens get embedded — that is, turned into numbers the neural network can understand. Special position codes are added so the model knows the order of the patches and which variable each one came from.
3. The Dispatcher Mechanism: Unified Attention, Less Memory
This is the real breakthrough. Instead of making every patch look at every other patch (which uses too much memory), the model introduces a small set of “dispatcher tokens.” Think of dispatchers like managers who collect information from all the workers (the data tokens), sort out what’s important, and then send helpful signals back.
The process goes like this:
- First, the dispatcher tokens “ask” questions to all the data tokens using an attention mechanism. They learn what’s going on across every variable and every time period — all at once. This creates a “first intermediate representation.”
- Next, the data tokens “ask” the dispatcher tokens for helpful information. This back-and-forth exchange lets the model build a “second intermediate representation” that now contains both intra-variate and cross-variate knowledge, but without needing to connect every data patch to every other patch directly.
Because there are usually only a few dispatcher tokens (much fewer than the number of data tokens), memory use stays low. The model can be trained even on big data sets with many variables.
4. Prediction and Training
The model uses the second intermediate representation to make its prediction — what it thinks the next value(s) in the time series will be. It compares this prediction to the real, known answer (called the “ground truth”) and calculates how far off it was. This difference is called the “loss.”
The model then uses a process called backpropagation to update its internal settings (including the dispatcher tokens) to do better next time. Over many rounds, it gets better and better at making predictions.
5. Flexibility and Real-World Use
The invention isn’t just a method — it covers systems (hardware and software) and even the way the code can be stored and used. It can run on regular computers, or special hardware like GPUs or TPUs, which are good at doing lots of calculations fast. It can be used for all sorts of forecasting tasks: predicting network traffic, machine health, chemical levels, weather, and much more.
Key Innovations That Set This Invention Apart
There are several areas where this approach stands out:
- Unified Attention: By flattening all the patches and using one attention mechanism across all variables and times, the model sees connections that older methods miss.
- Dispatcher Tokens: This clever trick keeps memory use low, making it possible to train on large, complex data sets that would crash other models.
- Direct Learning of Fine-Grained Dependencies: The model doesn’t just look at whole variables or whole time periods. It can pick up on subtle, patch-level patterns — for example, how a change in one variable at a certain time might affect another variable much later.
- Broad Applicability: The patent covers methods, systems, and code, so it can be built into everything from cloud services to on-premise machines. It’s not tied to a specific business or industry.
- Real-World Proof: Tests against other top models (like iTransformer, PatchTST, and Crossformer) show big improvements in accuracy — sometimes up to 13% better. And the dispatcher system saves enough memory that even large problems can be handled on regular hardware.
The invention also allows for further tweaks: you can change how many dispatcher tokens you use, how you split up the patches, or which loss function you use when training. This makes it easy to adapt to different types of data or business needs.
Finally, the patent covers not just the neural network structure, but also how it can be trained, including methods where only part of the model is updated (for example, only the dispatcher tokens), or where training is done in steps (first on one set of data, then fine-tuned on another).
Conclusion
This new approach to multivariate time series forecasting is a leap forward. By combining the power of unified attention with the efficiency of dispatcher tokens, it solves problems that have held back earlier models. The result: faster, more accurate predictions, even when working with huge and complicated data. For businesses and researchers who need to see the future, this invention opens the door to smarter, more responsive systems. As data continues to grow in size and complexity, tools like this will be key to turning information into action, and staying ahead of the curve.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363349.