Invented by Galvin; Brian
Welcome. In this article, we’ll take a close look at a cutting-edge patent for an adaptive neural network architecture, designed for real-time time series forecasting. This isn’t just another machine learning system—it’s a new approach that lets neural networks change themselves on the fly, monitor their own performance, and handle all kinds of data at once. Let’s break down what this invention means, why it matters, and how it stands out from everything that came before.
Background and Market Context
The world today runs on data. Every second, sensors, computers, stock markets, devices, and social media feeds pour out a stream of information—what experts call “time series data.” This is data that changes over time, like stock prices, weather updates, or even the readings from your smartwatch. Making sense of these streams is a huge challenge. Companies want to predict what comes next—will a price go up or down? Will the weather turn stormy? Will a machine break down? Accurate forecasting helps businesses make better decisions, save money, and avoid problems before they happen.
To tackle this, many have turned to artificial intelligence—especially deep learning models like transformers. These models, which power tools like ChatGPT and Google Translate, are great at understanding words and sentences. But when it comes to time series data, or when mixing text, numbers, and images together, they stumble. They often need a lot of memory, struggle with very large or fast-changing data, and can’t adapt quickly if things change.
In industries like finance, healthcare, and manufacturing, data doesn’t just come in one flavor. Stock market predictions, for example, need to look at news headlines, numbers, and even images. Hospitals want to combine sensor readouts, patient notes, and medical images. The challenge is clear: the old approaches are too slow and too rigid for the speed and mix of today’s data.
That’s where this new invention comes in. Its goal is to blend different types of information, adapt its own structure in real time, and keep working without having to pause and retrain. It’s designed for a world that never stops and never waits.
Scientific Rationale and Prior Art
Let’s step back and see how we got here. In the last few years, transformer models have changed the game for language tasks. Models like BERT and GPT can read and generate text with amazing fluency. They do this by turning words into dense vectors and using attention mechanisms to decide which parts of a sentence matter most.
But these models have limits. They expect input as a stream of tokens (like words), which doesn’t fit all data types. To process numbers or images, you need to add special layers called embeddings and positional encodings. These layers eat up memory and slow down processing. And if you want to handle new kinds of data, you often have to retrain the whole model from scratch.
Some researchers tried to fix this by using autoencoders (which compress data) or by adding more layers to handle different data types. But these fixes didn’t solve the root problem: how to let a neural network adapt itself on the fly, without stopping, and without losing what it already learned.
Earlier attempts to make neural networks more flexible included:
- Pruning (removing parts of the network that didn’t help)
- Neurogenesis (adding new neurons when needed)
- Sparse attention (focusing only on important parts of the data)
- Ensembles (using multiple models at once)
But each had trade-offs. Pruning could damage performance. Adding neurons could cause the model to “forget” what it already knew. Sparse attention worked in some cases but not others. Ensembles were too slow and costly for real-time use.
What was missing was a single system that could:
- Watch its own activity on every level (from single neurons to whole layers)
- Decide for itself how to change, based on what it sees
- Blend different types of data (text, numbers, images) in a single pass
- Keep track of what works and what doesn’t, and roll back bad changes
- Do all this while running, without stopping or retraining
This patent brings these ideas together for the first time.
Invention Description and Key Innovations
So, how does this invention work? At its heart, it’s a system that brings together several powerful ideas:
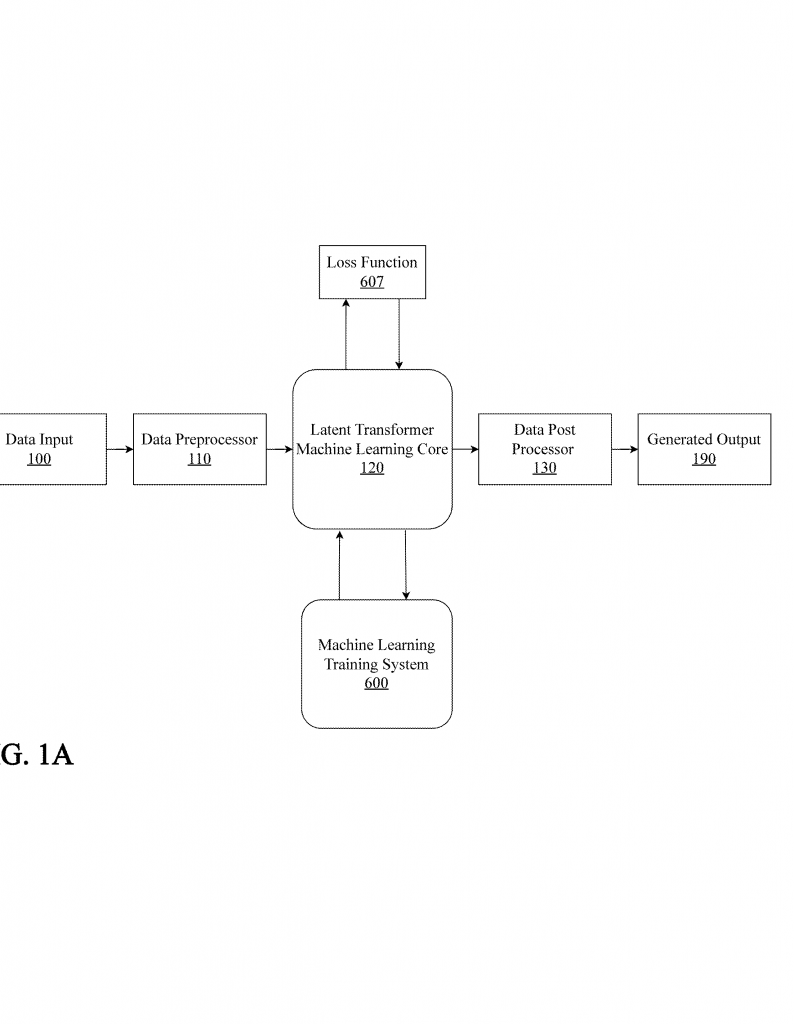
1. The Core Neural Network
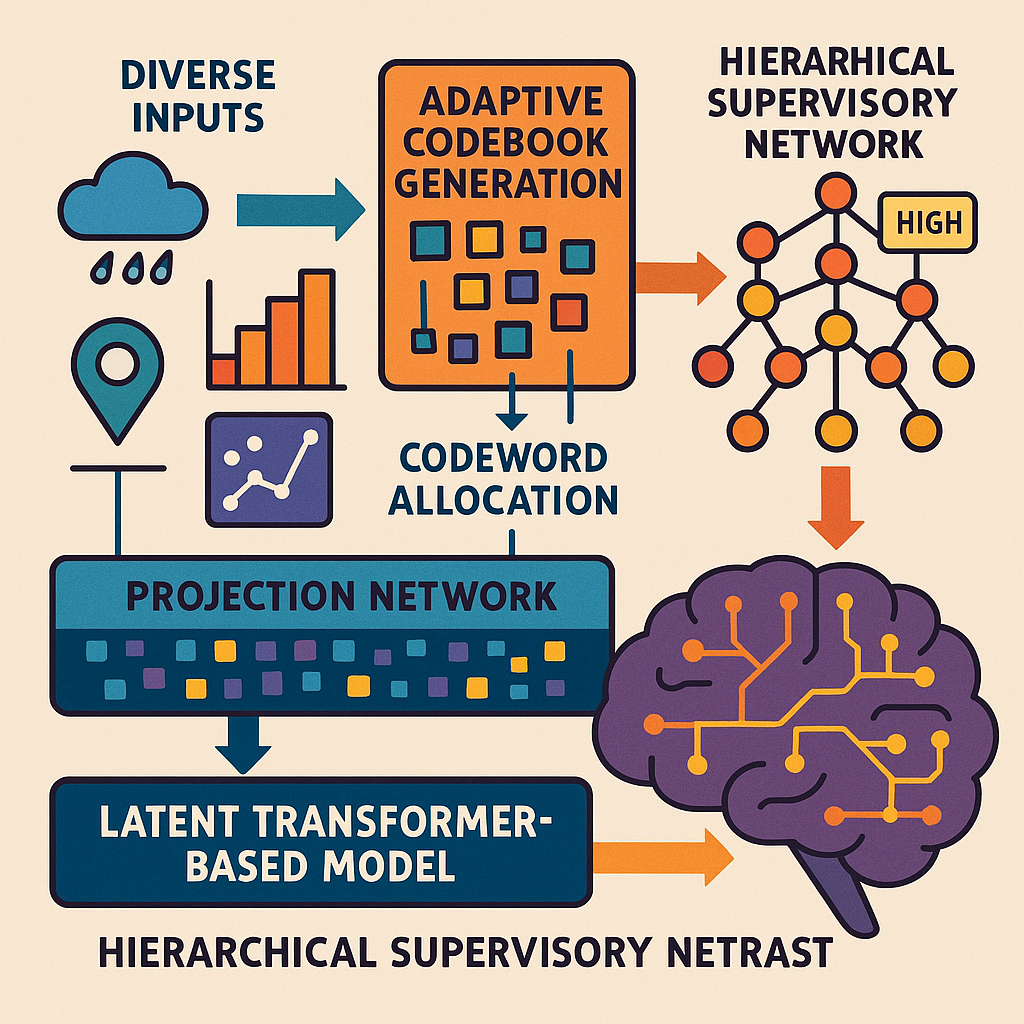
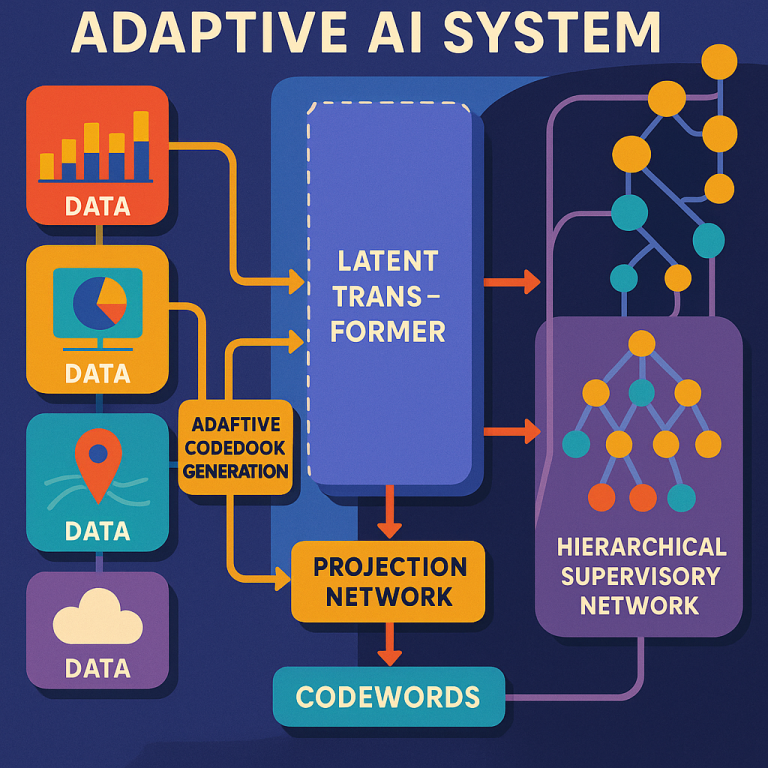
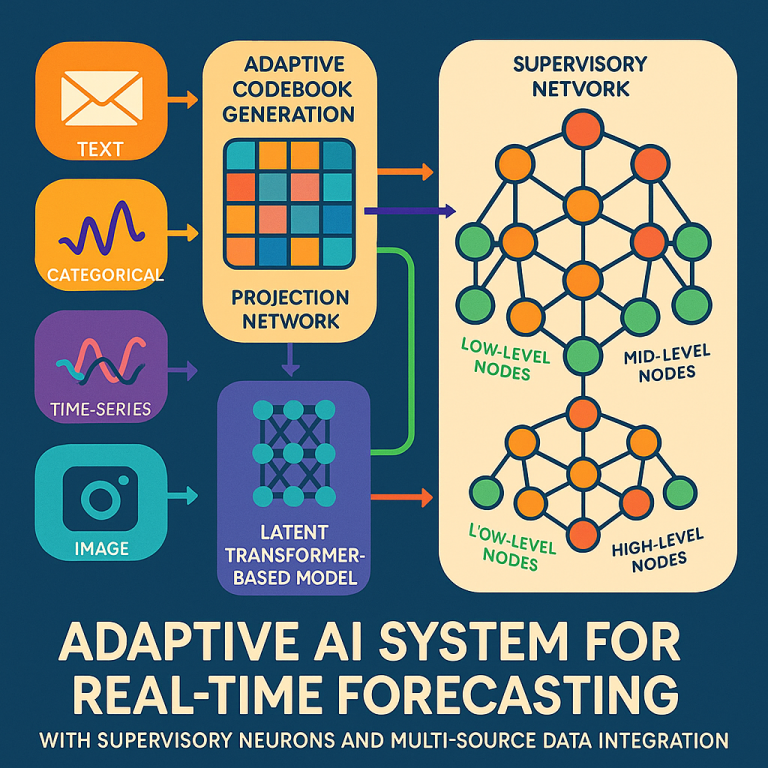
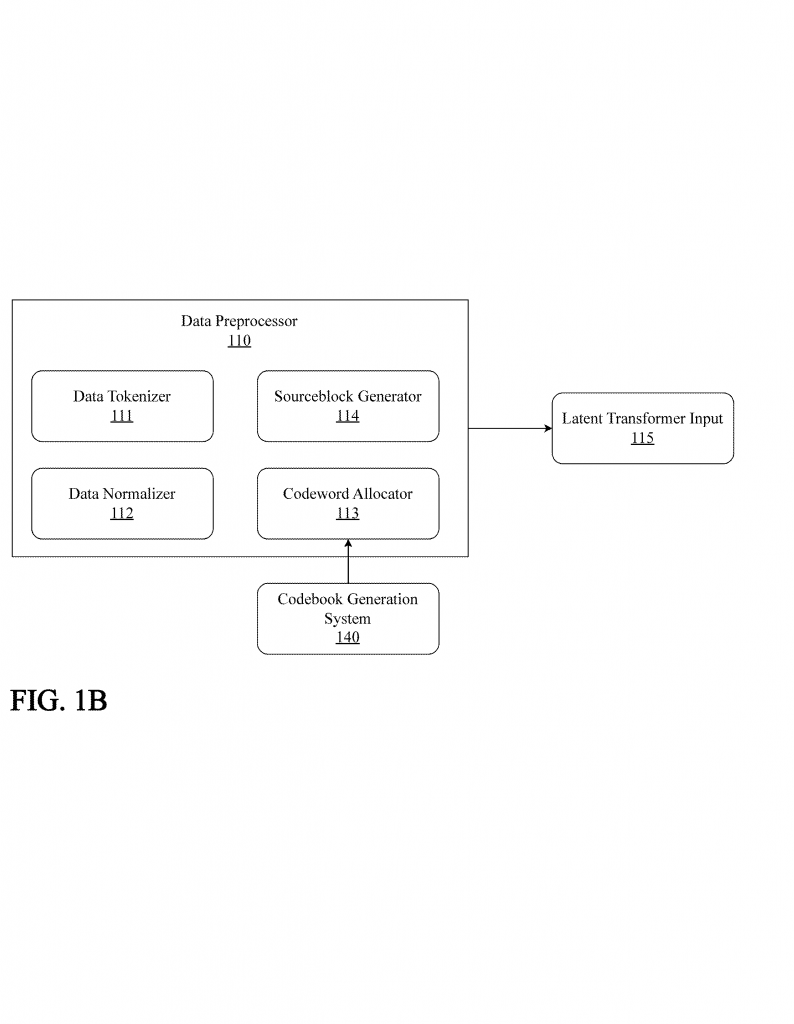
The main “brain” is a neural network made up of layers of neurons. Unlike past models, it doesn’t need separate embedding or positional encoding layers for each data type. Instead, it uses something called codewords. These are compact, expressive representations that stand in for any kind of input—text, numbers, or even images. This makes the system fast and memory-efficient.
2. Codeword Allocation and Fusion
Before data enters the core network, it goes through a codeword allocation subsystem. This part takes raw data, splits it into meaningful chunks (called sourceblocks), and assigns each one a codeword, based on a codebook. For example, a sentence, a series of numbers, or a patch of an image can each become a sourceblock. Codewords from different types of data are fused together, letting the network see all the information at once.
3. Variational Autoencoder (VAE) Encoding
The codewords are then compressed by a VAE encoder. This turns the mixed data into a compact “latent vector”—a kind of digital summary that captures what’s important, drops the rest, and makes things easier for the core neural network to handle.
4. The Latent Transformer
This is the heart of the innovation. The latent transformer processes the latent vectors using attention mechanisms, much like a classic transformer, but without the baggage of embeddings and positional encodings. It can process any kind of data and look for patterns across them. This means it can handle time series, text, images, and more—all at once.
5. Hierarchical Supervisory Network
Here’s where things get really interesting. Wrapped around the core network is a multi-level “supervisory” system. Think of this as a network of managers watching over every part of the neural network.
- Low-level supervisors watch small groups of neurons and can make small, quick changes (like splitting or pruning a neuron).
- Mid-level supervisors oversee groups of low-level nodes and can change how groups of neurons connect, or tweak local architectures.
- High-level supervisors look at whole layers or big blocks and can make large changes (like adding or removing entire subsystems).
- Top-level supervisors watch the big picture, setting goals and keeping everything running smoothly.
These supervisors talk to each other, share what they see, and coordinate changes across the network. Each can collect activation data (how busy each neuron is), do statistical analysis to spot trends or problems, and decide what changes will help most.
6. Real-Time Structural Modification
When supervisors spot an opportunity for improvement (maybe some neurons are always idle, or some connections are overloaded), they can order changes to the network—while it’s running. That means splitting a neuron into two, pruning out dead weight, or bundling connections for efficiency. The key is that changes happen smoothly, with no need to stop the system, retrain, or lose track of what’s happening.
7. Continuous Learning and Rollback
All changes are tracked and tested. If a modification helps (say, it makes predictions more accurate or faster), it’s kept. If not, the system rolls it back to the previous state. This feedback loop ensures the network only keeps what works, and never gets stuck in a bad configuration.
8. Adaptive Codebook Generation
The codebook itself—the mapping of data chunks to codewords—can adapt over time. If new patterns or data types emerge, the system can update its codebook, add new codewords, or retire old ones. This keeps the system fresh and relevant, even as the world changes.
9. Handling Multi-Modal, Real-Time Data
The whole system is designed to work in real time, taking in streams of data from many sources at once. Whether it’s a mix of numbers, text, pictures, or even sounds, the system can fuse them, spot relationships, and make predictions—fast.
10. Safety, Robustness, and Explainability
The system includes checks for errors, ways to recover from failures, and can even explain which parts of the data were most important for a given prediction. This makes it trustworthy for high-stakes uses, like finance or healthcare.
What Sets This Apart?
This invention isn’t just a tweak or a speedup. It’s a shift in how neural networks can adapt and thrive in a world of fast, messy, and ever-changing data. Unlike past models, it can:
- Adapt its own structure, at many levels, in real time
- Fuse and process multiple types of data at once, without custom layers for each
- Learn from its own history and performance, keeping what works and discarding what doesn’t
- Operate without downtime, making it fit for high-frequency, always-on environments
- Scale up or down, and handle everything from small edge devices to giant data centers
Use Cases and Impact
Imagine a bank predicting stock prices, and its model can instantly adjust if a new type of news event starts to matter. Or a hospital monitoring patient sensors and notes, and the system can spot new symptoms or adapt to new devices on the fly. Or a factory where the AI can keep running, even as machines are swapped out or new data streams are added.
For anyone building or using AI, this patent points the way to faster, smarter, and more flexible systems that are ready for the challenges of the real world.
Conclusion
The adaptive neural network architecture outlined in this patent is a leap forward for real-time forecasting and data fusion. By combining codeword-based representations, latent transformers, and a multi-level supervisory system, it offers a solution that can reshape itself, handle any data type, and keep running no matter what changes. For industries where speed, accuracy, and adaptability matter, this technology sets a new standard for what’s possible with AI.
If you’re looking to build AI systems that don’t just keep up with the future—but help create it—this invention is one to watch.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363358.