Invented by Galvin; Brian, McCord; Alan
This article explores a fascinating patent application for a computer system with a hierarchical thought supervision network. The technology aims to bring new efficiency and capability to machine learning and artificial intelligence by introducing smart, layered ways to manage, process, and adapt “thoughts” within a computer network. We break down what this means for the field, how it compares to earlier methods, and what’s truly new about this invention.
Background and Market Context
Artificial intelligence (AI) and machine learning (ML) have quickly become essential tools in business, science, and daily life. AI models, especially those handling language, images, and audio, are growing at a rapid pace. These models are getting better at understanding and generating complex data. However, with this growth comes a big challenge: large models require a lot of computing power, memory, and energy. They also struggle to handle information in real time or adapt well to new types of data or changing tasks.
Most modern AI, like popular large language models (LLMs), rely on architectures called transformers. Transformers process language by turning words into dense vectors (numbers) and then using attention mechanisms to figure out relationships between them. This approach has produced impressive results in tasks like translation, summarization, and image captioning.
But transformers have their limits. They need a lot of memory to hold all the vectorized data and struggle to keep track of information over long conversations or big data streams. Also, they are often designed for one type of data, like text, and require extra engineering to handle things like images or audio.
Companies and researchers want AI models that are not only accurate but also efficient, flexible, and able to adapt as tasks or data types change. There’s a strong market demand for systems that can process thoughts (chunks of information or reasoning steps) more cleverly, store and retrieve useful patterns, and adjust to new requirements on the fly. The patent we’re exploring directly addresses these pain points by introducing a new kind of multi-layered, adaptive network for handling “thoughts.”
In simple terms, this invention aims to make AI models smarter in how they manage their own thinking. By introducing layers that monitor, supervise, and optimize the flow and storage of thoughts, the system promises to deliver faster, more efficient, and more adaptable AI for a wide range of uses—everything from chatbots and search engines to robots and self-driving cars.
Scientific Rationale and Prior Art
To understand the need for this invention, it helps to know how current systems work and where they fall short.
Traditional transformer models process data by tokenizing input (like splitting sentences into words or smaller pieces), turning these tokens into dense vectors, and then running them through layers of attention and feed-forward networks. This method is powerful for finding patterns, but it has drawbacks:
– Memory and Speed: Dense vectors are big, and storing all the information needed for long conversations or big data sets is costly.
– Context Limitations: Transformers have a fixed “context window,” which means they can only look at a certain number of tokens at once. If the conversation or data stream is too long, important earlier information may be forgotten.
– Adaptability: Once a transformer model is trained, it is often hard to adapt to new tasks or data without retraining or fine-tuning, which is slow and expensive.
– Resource Waste: Many computations are repeated needlessly, especially when responding to similar queries or solving repeated problems.
Researchers have tried to address these problems in several ways:
– Caching: Some systems keep a memory of past computations (a cache) to avoid repeating work. However, these caches are simple and usually not well-organized or easily shared across different tasks or users.
– Hierarchical Models: Others have introduced layers of abstraction, where lower layers handle raw data and higher layers handle more abstract reasoning. These models can be complex and hard to tune.
– Dynamic Networks: There is growing interest in networks that can change their structure—adding, removing, or adapting nodes—based on performance or need. But integrating this with efficient caching and supervision has been challenging.
Prior art includes techniques like:
– Self-attention mechanisms that allow models to focus on different parts of the input as needed.
– Memory-augmented neural networks that try to hold on to important information across long tasks.
– Supervisory neurons or meta-learning, where parts of the network monitor or adjust how other parts work.
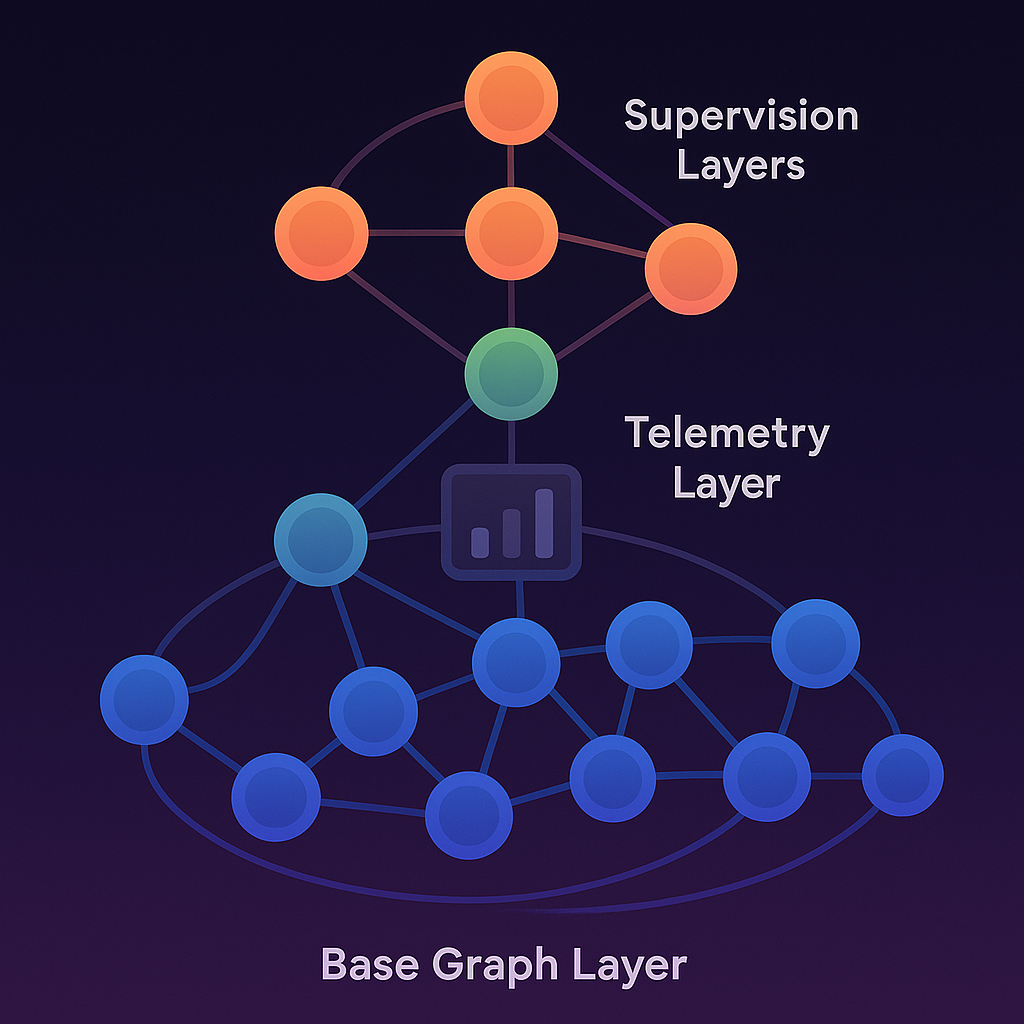
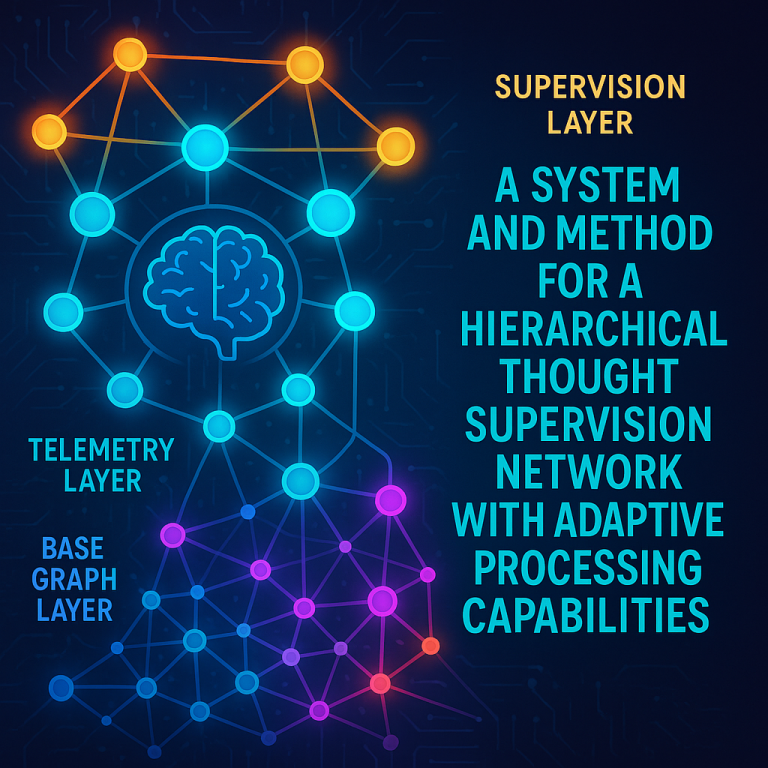
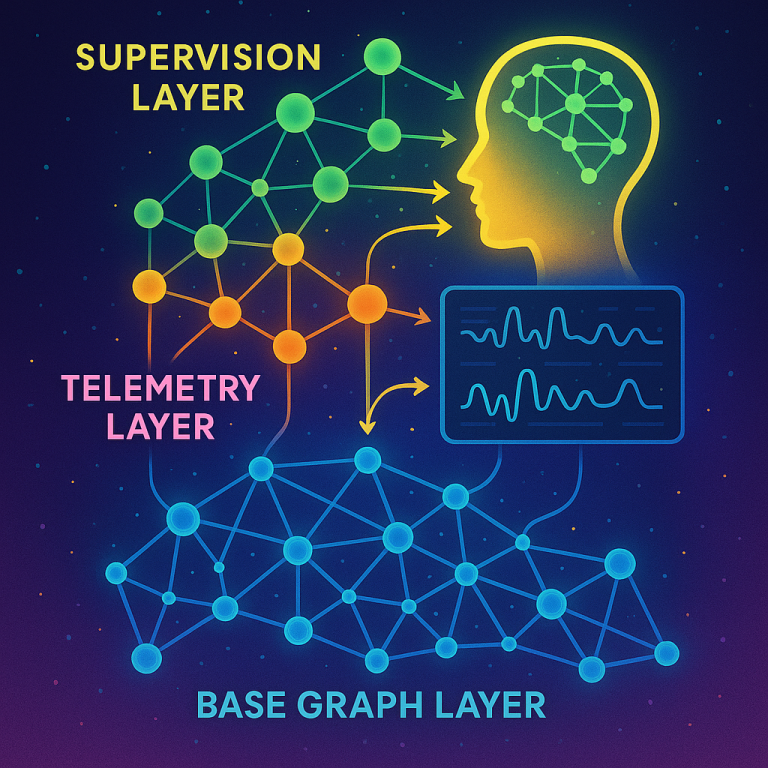
What’s been missing is an integrated system that brings together real-time monitoring, smart caching, and adaptive network supervision in a way that’s both efficient and flexible. This patent proposes a layered network that does just that: a base graph layer for processing, a telemetry layer for monitoring, and one or more supervision layers for adapting and optimizing network operations—all working together to manage thoughts at different levels of detail and importance.
By combining dynamic thought encoding, continuous performance analysis, hierarchical supervision, and advanced caching, the invention offers a step forward over existing solutions. It enables real-time adaptation, better resource use, and the ability to keep track of context as long as needed, all while optimizing performance for a variety of tasks and data types.
Invention Description and Key Innovations
At the heart of this patent is a computer system built to organize and optimize the processing of “thoughts”—discrete units of reasoning or data—across several smart layers.
1. Layered Network Architecture
The system is organized into three main layers:
– Base Graph Layer: This is where the main action happens. Interconnected network nodes process and manage thoughts. These nodes can handle different kinds of data (text, images, audio) and are designed to store, retrieve, and transform thoughts as needed. Each node keeps track of its own operational state and can communicate with others.
– Telemetry Layer: This layer acts as the network’s eyes and ears. Specialized monitoring nodes constantly collect information about how well the system is processing thoughts—measuring things like speed, resource use, and efficiency. They use smart techniques (like adaptive kernel functions and topology-aware metrics) to spot when things are going well or need improvement.
– Supervision Layers: These are the brains of the operation. Supervisory nodes in these layers watch over the network, use the telemetry data to spot problems or opportunities, and take action. They can optimize how thoughts are encoded, decide when to create new nodes, or prune (remove) underperforming ones. There can be multiple supervision layers, each handling different scales—from local tweaks to global system changes.
2. Dynamic Thought Encoding
Instead of fixed, dense representations, this system uses “dynamic encodings.” Each node can change how it represents thoughts based on real-time feedback. This means the network adapts to the kind of data it’s seeing, the resources available, and the current performance needs.
3. Smart Caching with Local and Global Storage
The base graph layer includes a thought cache. There are two main types:
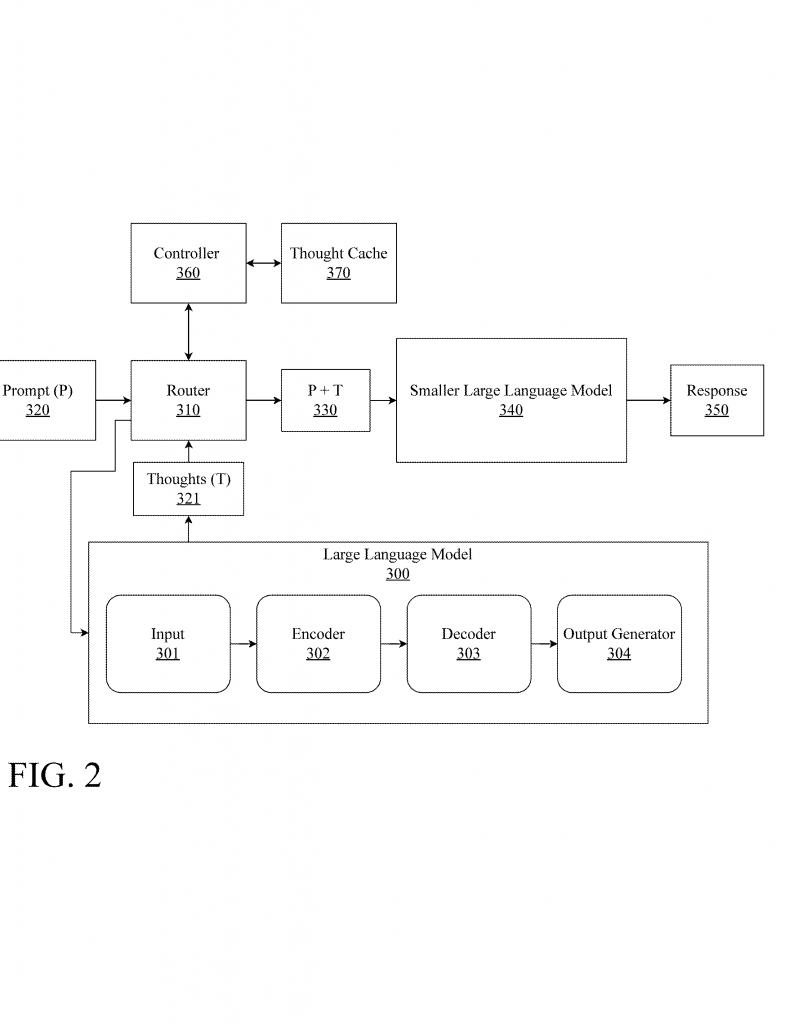
– Local Cache: Stores thoughts that have been used recently or are likely needed again soon. This speeds up repeated processes and makes the system more responsive.
– Global Cache: Holds persistent thought patterns—long-term knowledge or common reasoning steps. This enables sharing across different parts of the system and even between different users or tasks.
Thoughts can move between local and global caches as their importance or usage changes. The system also compresses and organizes thoughts in the cache to save space and improve retrieval.
4. Continuous, Real-Time Monitoring
The telemetry layer uses advanced analysis (like kernel functions) to monitor performance at every level. It tracks how long it takes to process thoughts, how much memory is being used, and whether there are any bottlenecks or inefficiencies. This data is then used by the supervision layers to drive optimization.
5. Adaptive Node Generation and Pruning
A standout feature of the invention is the ability to change the network’s structure automatically. If a group of nodes is overloaded or underperforming, the supervision layer can create new nodes to help out. If some nodes are redundant or not adding value, they can be pruned away. This keeps the network lean, fast, and well-tuned to current needs—without manual intervention.
6. Thought Synthesis and Combination
Supervisory nodes can combine multiple thoughts into new, more useful ones—a process called thought synthesis. This helps the system create more abstract, generalizable knowledge and avoid repeating the same reasoning steps again and again.
7. Hierarchical Supervision and Cross-Layer Coordination
The system doesn’t just optimize locally. Supervisory nodes at different levels can coordinate their actions so that local tweaks don’t cause global problems. For example, if a change that helps one part of the network causes issues elsewhere, the global supervision layer can step in and rebalance things.
8. Performance-Driven Objectives
The system is always working toward clear performance goals. These can include lowering the cost of encoding thoughts, reducing how long it takes to process information, minimizing memory use, and ensuring the best possible results. All decisions—about encoding, caching, node management, and synthesis—are made with these objectives in mind.
9. Flexible, Modular Design
The architecture is designed to be flexible and modular. It can be deployed in small, resource-limited environments (like mobile devices) or scaled up to run across big data centers or clouds. Parts of the system can be turned on or off, combined, or extended as needed for different applications.
10. Security and Privacy Controls
The patent also covers mechanisms for keeping sensitive thoughts private and safe. Caches can be encrypted, access can be restricted by user or task, and sharing of thoughts is controlled and audited. This is especially important for enterprise or multi-user deployments.
What’s New and Why It Matters
The key innovation here is the combination of all these mechanisms in a single, integrated system. By layering real-time monitoring, adaptive supervision, and smart caching, the invention creates a network that is not only efficient and powerful but also self-improving. It can adapt to new tasks, learn from experience, and optimize itself automatically—all while keeping resource use in check.
This approach opens the door to AI models that have effectively unlimited context (they can remember and use information from much earlier in a conversation or data stream), don’t waste resources on repeated work, and can quickly adjust to new kinds of data or changing requirements. It also enables better collaboration between different AI agents or models, as shared thought caches can store and reuse valuable reasoning patterns.
For businesses, developers, and researchers, this means faster, smarter, and more cost-effective AI systems that can keep up with the growing demands of real-world applications.
Conclusion
The hierarchical thought supervision network described in this patent represents a big leap forward in how computers can manage their own “thinking.” By introducing layers that process, monitor, and adapt thoughts in real time, the system promises to make AI more efficient, flexible, and powerful than ever before. Its clever use of dynamic encoding, smart caching, and adaptive supervision addresses many of the key challenges facing large AI models today—making it a valuable step toward the next generation of intelligent systems.
Whether you’re building chatbots, analyzing data, or powering autonomous vehicles, this technology could help your systems think faster, remember more, and adapt on the fly—all while making the most of your available resources.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363364.