Invented by Gaur; Jayesh, Bandishte; Sumeet, Shwartsman; Stanislav
Welcome! In today’s article, we’ll explore an exciting patent application about Software Defined Super Cores (SDC) and their inventive way of making two (or more) processor cores work together as if they are a single, more powerful core. We’ll look at why this matters, what came before, the science behind it, and how this invention stands out in the world of computer processors. Let’s break down these complex ideas into simple, clear explanations so anyone can understand how SDCs change the game for CPU performance.
Background and Market Context
Modern computers need to be faster and use less power. For years, chip makers tried to make single CPU cores run at higher and higher speeds, but this uses more electricity and makes computers hot and less efficient. Making each core bigger and faster gets harder as technology limits are reached, and it can be very expensive. There is also a trade-off: if you make one core much bigger, you might not have room or power for more cores on the chip.
To balance speed and efficiency, companies started using “big” and “little” cores together. The “big” ones handle tough jobs quickly but use more energy. The “little” ones are more power-friendly but slower. This design, called “heterogeneous architecture,” helps with different types of workloads but is still not perfect. The ratio of big to little cores is fixed when the chip is made, so it can’t easily adapt to new needs. Also, designing and testing multiple types of cores is time-consuming and costly.
When a program is written to use just one core (a single-threaded program), it does not take advantage of all the possible hardware. If you want to make things go faster, you could try to split the program across more than one core. But, up to now, splitting a single-threaded program into parts that run on two cores has required a lot of extra work. Many instructions must be copied for both cores, memory management gets complicated, and much of the possible speed-up is lost to this overhead.
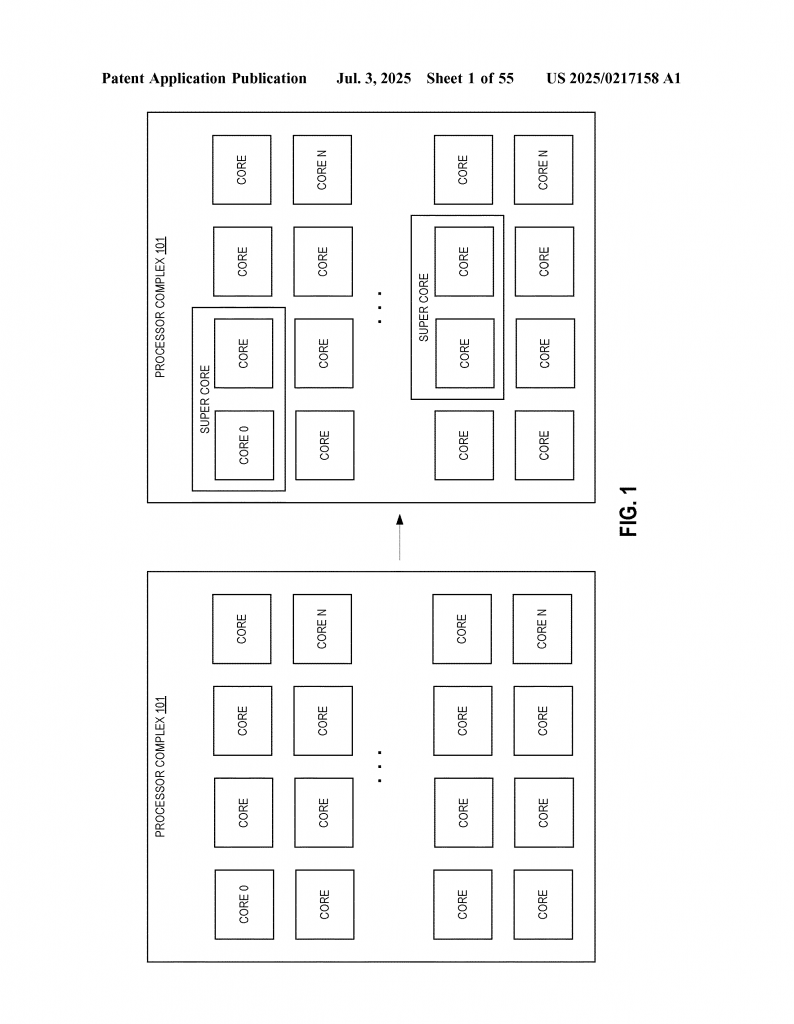
Software Defined Super Cores (SDC) address these problems. They allow two or more similar cores to work together and look like one big, strong core to the operating system and software. This “virtual core” can handle a single thread’s work by splitting it into pieces and having each core work on a different part, then putting the results back in order. SDCs promise high performance and better efficiency, all without the need for more complex core designs or fixed big/little core ratios. SDCs make it easier for hardware and software to adapt and get the best performance for the task at hand.
Scientific Rationale and Prior Art

Before SDCs, the main way to get better performance was to run different parts of a program on different cores. This is called “multi-threading.” If a program could be split into independent pieces, each could be handled by its own core at the same time. But many programs, especially older or simpler ones, are designed as a single thread. Splitting a single thread into parts that can run across more than one core is hard.
Some earlier approaches tried to automatically split the “hot” (often-used) parts of single-threaded programs into two threads to run on two cores. This required copying lots of instructions (including memory instructions) to both “strands” so each core looked independent. This method could add up to 40% more instructions than the original program, hurting performance and making everything more complicated.
Another challenge is making sure memory is always in the right order. Say Core A writes to memory and Core B reads from it; you need to make sure Core B doesn’t read the old value by mistake. Earlier solutions needed big changes to how the CPU’s memory system works, like special logic to keep everything in order. This can slow things down and burn more power.
There were also ideas like “core fusion” or “virtual cores,” but these often worked only for certain types of code or needed special hardware. Most could not handle the full range of programs or would require rewriting software.
The SDC approach builds on these ideas but brings together smarter software and hardware. The software splits the single thread into chunks that can be run on different cores, and the hardware adds just a bit of extra logic to make sure memory and registers are kept in sync. This way, SDCs keep the extra work (overhead) very low—less than 5% more instructions compared to the original, instead of the 25-40% overhead in older methods.
SDCs also offer flexibility. The split can be managed by software (with a special program or compiler), or even by hardware at runtime. This means SDCs can work for regular programs, even those that weren’t rewritten or recompiled. The hardware changes are small, so chip designers can add SDC support without a big redesign. And because SDCs treat a group of cores as one “super core,” they can give the operating system and software the illusion of a single, very powerful core, making everything simpler for programmers.
Invention Description and Key Innovations
The heart of this invention is a way to split a single-threaded program into segments, assign those segments to multiple processor cores, and make those cores work together as if they are one. The operating system and the program don’t need to know anything has changed—the system just looks like it has a very fast core.
Let’s look at the main pieces and how they work:
1. Splitting the Program into Segments
The SDC software (or sometimes hardware) splits the single-threaded program into blocks, called segments. Each segment is a chunk of instructions (maybe 100, 200, or another number) that fits nicely for the hardware. These segments are then assigned to different cores. For example, Core 0 gets the first segment, Core 1 gets the next, then back to Core 0 for the third, and so on. The program is split in such a way that each segment can run mostly independently, but sometimes they need to share information.
2. Special Instructions for Syncing and Sharing Data
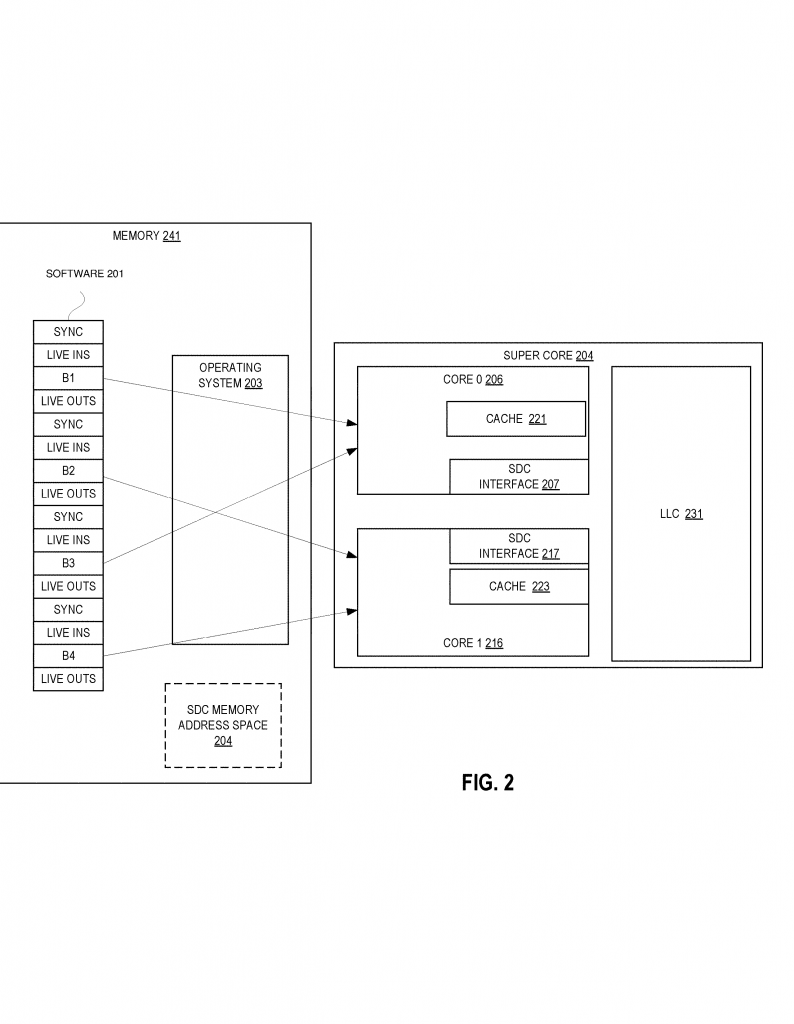
To make sure everything stays in the right order, special “sync” instructions are added at the beginning and end of each segment. Before a core starts a segment, it uses a “sync load” to make sure all earlier instructions on the other core are finished. At the end of a segment, it uses a “sync store” to send any needed results to the other core.
When a core finishes a segment, it writes out any “live” register values (data that the next segment might need) to a special memory area called the “wormhole.” This area is not visible to the user program, but is managed by hardware and the operating system. The next core, before starting its segment, reads these values in with a “livein load.”
3. The SDC Interface and Wormhole Address Space
Each core gets a small hardware addition called the SDC interface. This interface manages the wormhole memory area, handles the sync instructions, and helps forward register and memory data between the cores. The SDC interface also tracks which registers are live and need to be shared.
4. Memory Dependency Handling with Shadow Store Buffers
Sometimes, a load (read) in one core needs data from a store (write) in the other core. To manage this, each core keeps a shadow store buffer—a small buffer that holds the addresses of stores from the other core. When a core wants to read from memory, it first checks its own store buffer, and the shadow store buffer from the partner core. If there is a conflict, it can request the needed data directly from the other core, or stall until the data is ready. This way, only the loads and stores that need to be shared are actually communicated, saving time and power.
5. Disambiguation Prediction
To avoid unnecessary waiting and extra communication, each core includes a “disambiguation predictor.” This small hardware predictor guesses whether a load might need to get data from the other core’s stores. If it predicts no conflict, the load can go ahead. If it predicts a possible conflict, the load is sent to the other core for checking. If a mistake is made, a correction step (“nuke”) is triggered to fix the ordering.
6. Register Renaming and Out-of-Order Speculation
Cores often execute instructions out of order for speed. To keep track of which registers are produced in which segment, a “liveout” data structure is used. Each core keeps a list of which registers it has written (liveouts), and shares that with the other core. The other core can speculate on which registers it will need, and insert pull requests for them. If the speculation is wrong, a clear and re-fetch is done, but this happens rarely.
7. Parallel Fetching and Branch Prediction
To increase speed, each core predicts where the next segment starts. When a core finishes a segment, it tells the next core where to start. If the prediction is wrong, the pipeline is flushed and restarted at the right spot. This way, both cores can fetch new instructions at the same time, using branch predictors and a special trace table to guide them.
8. Dynamic and Flexible Operation
The SDC mode is not always on. The system can decide, using built-in telemetry (performance and power monitoring), when to enable or disable SDC. If, for example, the program is not getting enough benefit (maybe because it’s very sequential, or there are too many branch mispredictions), the operating system can switch back to conventional single-core mode. When this happens, the cores save their state and resume as a normal core. The decision to enter or exit SDC mode is made by the operating system, sometimes with advice from the hardware’s telemetry.
9. Seamless to Software and Operating System
All these changes are mostly invisible to normal software. The operating system schedules programs as usual; if SDC mode is enabled, it sees a “virtual core” that is faster. The SDC hardware handles all the tricky parts of keeping memory and registers in sync, and the software only needs minimal changes—sometimes none at all, especially if the splitting is handled at runtime or by the JIT compiler.
10. Power and Performance Throttling
To avoid wasting power, the SDC keeps an eye on branch mispredictions, memory stalls, and other performance counters. If stalls or mispredictions are too high, the system can “throttle down”—either by switching off SDC mode, or by lowering the voltage/frequency. This helps keep the performance per watt high.
What Makes This Invention Special?
- It enables a group of simple, similar processor cores to act as one big, powerful core without needing huge hardware changes.
- The overhead for splitting up the program and syncing data is kept tiny—less than 5%, compared to up to 40% in older attempts.
- It handles memory ordering and register sharing smartly, so only the needed data is communicated between cores.
- It works for regular, single-threaded programs—even legacy software—by adding a thin layer of software or runtime.
- It is very flexible: SDC mode can be turned on or off as needed, and the system can adapt based on workload and power needs.
- It includes hardware predictors and buffers that keep everything in order but don’t slow the system down.
- The SDC approach can be used in many types of computer systems, from laptops to servers to embedded devices, and fits with both in-order and out-of-order cores.
Conclusion
Software Defined Super Cores are a clever blend of software and hardware that let two or more regular CPU cores act together as one fast, efficient, virtual core. By splitting a single-threaded program into segments and managing register and memory sharing with smart predictors and buffers, SDCs deliver higher performance for single-threaded workloads without the big costs and complexity of traditional approaches. They are flexible, adaptive, and mostly invisible to the operating system and software, making them a practical solution for today’s and tomorrow’s computing needs. This invention stands out by keeping overhead low, handling tricky memory and register dependencies smoothly, and offering a platform for high efficiency and speed—all with minimal changes to existing designs.
As computer workloads and hardware continue to evolve, software defined super cores offer a path to faster, more efficient, and more adaptable systems, ready to meet the demands of the future.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217158.