Invented by SONG; Ju Hwan, PARK; Seungin, YOO; Byung In, JUNG; Sangil, Samsung Electronics Co., Ltd.
Let’s talk about a new way to train object detectors. We’ll look at why this is important, how the old ways work, and what is new with this invention. This guide will help you see how everything fits together, even if you are not a tech expert.
Background and Market Context
Today, we use computers to see and understand the world around us. This is called computer vision. One big part of this is object detection. Object detection means teaching a computer to find things, like cars, people, or animals, in pictures or videos. You might see this in self-driving cars, security cameras, or even your phone’s camera.
As our world gets more digital, more companies want better object detection. This means they want computers to find things more quickly, more clearly, and in more places. For example, a car needs to spot people on the road to keep everyone safe. A shop might use cameras to count how many people visit. Even robots in factories need to know where things are to pick them up.
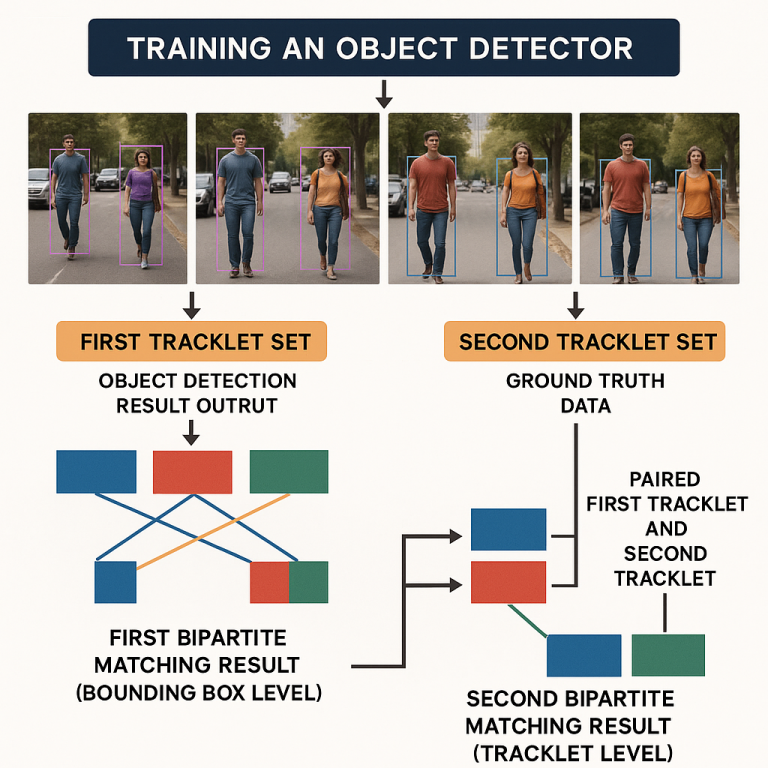
To make object detection work well, we need to train computers with lots of examples. This is called training an object detector. We show the computer many pictures and tell it what is in each picture. This is called “ground truth” data. The computer tries to learn from this and do better each time. But making this ground truth data takes a lot of time and effort. People have to look at every picture and draw a box around each thing they want the computer to find. This is slow and expensive.
There are also different ways to do object detection. Some methods look at the whole picture at once. Others first pick out parts of the picture that might have something interesting and then look more closely. These are called 1-stage and 2-stage detectors. Each has its own strengths. But no matter which one you use, making good training data is always hard.
Because of this, many companies and researchers want better ways to train object detectors. They want to make it faster, easier, and more accurate. If we can do this, we can use smart cameras in more places, make cars safer, and help computers understand the world much better.
Scientific Rationale and Prior Art
Before this new invention, people used some common methods to train object detectors. Let’s break down how these older ways work and where they fall short.
The most common way is to use bounding boxes. Imagine you draw a box around a dog in a picture. You tell the computer, “This box is a dog.” You do this for lots of pictures. This helps the computer learn what a dog looks like. Later, when it sees a new picture, it tries to draw a box around the dog by itself.
To test if the computer is doing well, you compare the boxes it draws to the boxes you made. If they overlap a lot, the computer is doing a good job. If not, it needs more practice. This comparing is usually done one picture at a time.
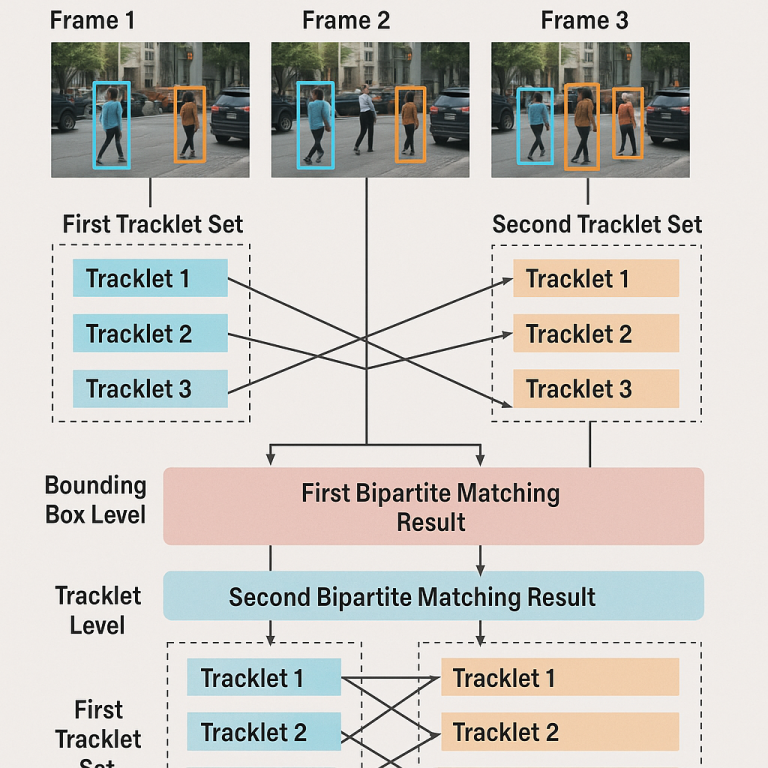
But real life is not just one picture. Often, we use videos or many pictures taken one after another. For example, in a video of a street, a car moves from one frame to the next. It is not enough to find the car in just one frame. We want the computer to follow it across many frames. This line of boxes, one in each frame, is called a “tracklet.” It shows where the car goes over time.
The old methods often look at boxes in just one frame. If the car is found in frame 1 and frame 2, but the boxes are not matched up, the computer can get confused. It might think there are two cars instead of one. Or it might lose track of the car if it looks a little different in each frame.
Some tools do try to match objects across frames. They use trackers that try to link boxes in one frame to boxes in the next. But these trackers can make mistakes. For example, if two people cross paths, the tracker might mix them up. Also, when comparing the computer’s guesses to the ground truth, the matching is usually simple. It just looks for boxes that overlap the most. This can miss some subtle mistakes.
To make matching better, people have used something called bipartite matching. This is a way to pair up boxes from two sets so that each box is matched to only one other box, in a way that makes the total “cost” as small as possible. The cost is usually how different the boxes are. For example, if the boxes are far apart, the cost is high. If they are close, the cost is low.
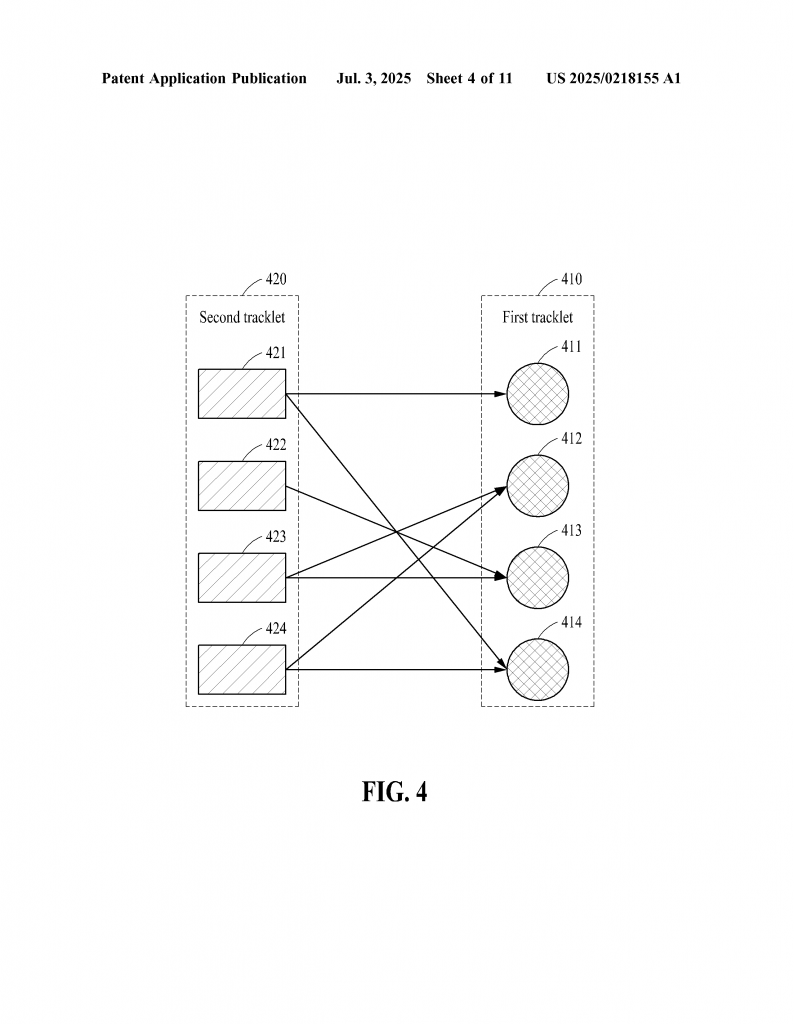
The problem is, most old methods only use this matching at one level. They pair up boxes in each frame or pair up tracklets as a whole, but not both. If you only match boxes, you can make mistakes when linking tracklets. If you only match tracklets, you might miss mistakes in single frames.
Also, when making ground truth data, people still need to check and fix lots of things by hand. If the computer makes a mistake, it can be hard to spot without looking at all the frames. This makes training slow and less accurate.
In short, the old ways either focus on single frames or on tracklets, but not both. They use simple pairing methods that can miss mistakes. They also need a lot of human checking, which takes time and money. There is a need for a better way to match boxes and tracklets at the same time, to make training faster and more accurate, and to help computers learn with less hand-holding.
Invention Description and Key Innovations
Now, let’s talk about what this new invention does and why it matters.
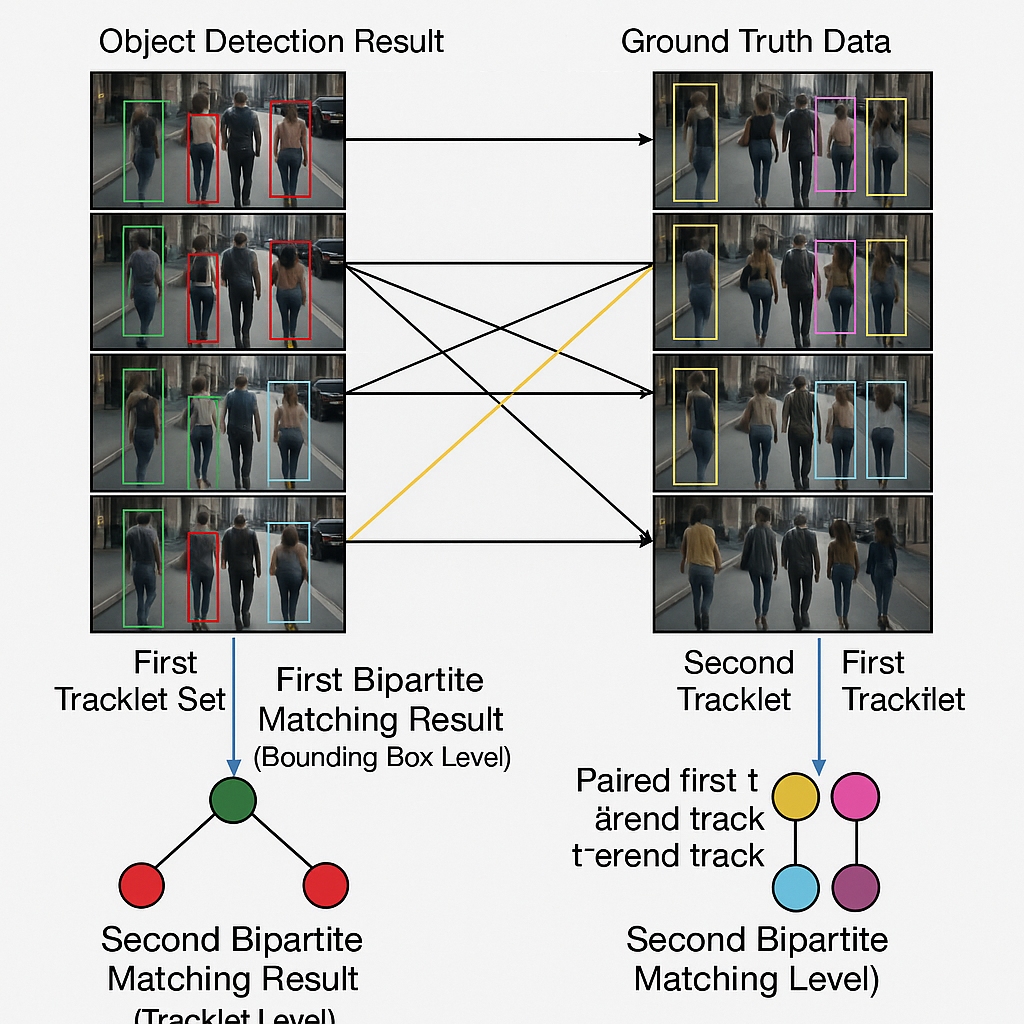
This invention introduces a new way to train object detectors using something called “double bipartite matching.” It is like giving the computer two chances to get things right, first by matching boxes in each frame, and then by matching groups of boxes (tracklets) across many frames. Let’s break it down into simple steps.
First, we have two sets of tracklets. One set comes from the computer’s guesses. The other set comes from the ground truth, which is what humans say is correct. Each tracklet is a line of boxes showing where an object is over time.
The first step is to do bipartite matching at the bounding box level. This means, for each tracklet from the computer, we match its boxes to the boxes in the ground truth tracklet, one frame at a time. We look for the best way to pair up the boxes so that they are as close as possible. For each pair, we check how similar they are. The similarity depends on things like:
- How much the classes match (is a box labeled as a car matched to a car?)
- How close the boxes are in space (do they mostly overlap?)
- Are the sizes and shapes similar?
- Is the rotation or angle about the same?
If the boxes are very similar, the cost is low. If they are different, the cost is high. The computer tries to pair up boxes so that the total cost across all pairs is as small as possible.
Next, after matching boxes, we do bipartite matching at the tracklet level. Here, we look at whole tracklets, not just single boxes. We use the results from the box matching to help decide which tracklets should be paired. For each pair of tracklets, we look at the average cost from the boxes that were matched. This tells us how well the computer’s tracklet matches the ground truth tracklet.
Again, the computer pairs up tracklets so that the total cost across all tracklet pairs is as small as possible. If a tracklet from the computer matches a tracklet from the ground truth well, they are paired. If not, they are left unmatched.
Once the best pairs are found, the matched ground truth tracklet is assigned to the computer’s tracklet. This helps the computer know which of its guesses are correct and which are not. The unmatched tracklets can be flagged for human checking or ignored.
This double matching process helps in many ways. It lets the computer spot mistakes that only show up when you look across many frames, not just one. For example, if the computer loses track of a car halfway through a video, this will show up in the tracklet matching. If two objects are mixed up in one frame, the box matching will catch it.
There are also other smart features. For example, you can set a threshold for how good a match has to be. If the match is not good enough, the pair is not used. This helps avoid training the computer with bad data.
This method can also be used to combine the results of different object detectors or data from different sensors. For example, you can use data from two cameras watching the same scene, or two different types of detectors. The double matching helps align the results and make them more accurate.
All of this can be done by a computer program, running on a regular computer or a special chip. The program stores the data, does the matching, and updates the object detector. It can also be built into a device, like a smart camera or a robot.
This new way of training object detectors offers big improvements:
- It makes training faster, since less human checking is needed.
- It makes training more accurate, since mistakes can be found and fixed at both the box and tracklet level.
- It allows for better use of video and sensor data, not just single pictures.
- It can combine results from different detectors or sensors to get the best answer.
With these changes, companies can build smarter cameras, safer cars, and better robots—while saving time and money on training. This opens the door to new uses for object detection, from smart cities to home security, and everything in between.
Conclusion
Object detection is a key part of making machines understand the world. But training object detectors has always been hard and slow, needing lots of human work and often missing mistakes that show up over time. This new invention changes that by using double bipartite matching—first matching boxes, then matching tracklets. This helps computers learn better from video data, find and fix mistakes, and need less help from people.
With this new method, we can make smarter systems that watch over our cities, keep cars safe, and help robots work better. Training becomes faster and more accurate, and computers can learn from many types of data. If you build or use smart cameras, robots, or self-driving cars, this invention could help you get better results with less effort. The future of object detection just got a little bit closer.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218155.