Invented by Kyle Michael Roche, David Chiapperino, Christine Morten, Kathleen Alison Curry, Leo Chan, Amazon Technologies Inc
Traditionally, avatar animation has relied on pre-recorded motion capture data or manually created animations. However, these methods often lack the spontaneity and naturalness that is present in real-life interactions. To address this limitation, researchers and developers have turned to the use of dialog and contextual information from the virtual environment to generate metadata for avatar animation.
By analyzing the dialog and contextual information, such as the user’s speech, facial expressions, and body language, sophisticated algorithms can generate metadata that can be used to animate the avatar in real-time. This approach allows for more dynamic and responsive avatars that can interact with users in a more lifelike manner.
The market for this technology is driven by various industries and applications. In the gaming industry, realistic avatar animation enhances the immersion and engagement of players, creating more compelling gaming experiences. Additionally, in the field of virtual training and simulations, avatars with natural animations can provide more effective and realistic training scenarios for professionals in fields such as healthcare, military, and aviation.
Furthermore, the entertainment industry can benefit from this technology by creating virtual characters that can interact with users in live performances or virtual concerts. This opens up new possibilities for virtual events and experiences, especially in the current era of social distancing.
The market for the use of dialog and contextual information for avatar animation is also fueled by advancements in AI and machine learning. As these technologies continue to evolve, the algorithms used to generate metadata for avatar animation will become more sophisticated and accurate, further enhancing the realism and naturalness of avatars.
However, there are also challenges and considerations associated with this technology. Privacy concerns regarding the collection and analysis of user dialog and contextual information need to be addressed. Additionally, ensuring diverse and inclusive representations in avatar animations is crucial to avoid biases and stereotypes.
In conclusion, the market for the use of dialog and contextual information from a virtual environment to generate metadata for avatar animation is expanding rapidly. With the increasing demand for realistic and immersive virtual experiences, this technology has the potential to revolutionize various industries, including gaming, virtual training, and entertainment. As AI and machine learning continue to advance, the animations generated by avatars will become even more lifelike, providing users with truly immersive virtual experiences.

The Amazon Technologies Inc invention works as follows
One or multiple services can generate audio data and animated avatars based on the input text. Speech input ingestion services (SIIs) can identify tags on objects in virtual environments and link them to words in input text. This metadata may then be stored in speech markup. This association can be used by an animation service to create gestures towards objects when animating an avatar or to create animations and effects for the object. The SII service can analyze text input to identify dialogue including multiple speakers. The SII service can create metadata that associates certain words with the respective speakers of those words. This can be processed by an animation service in order to animate the multiple avatars.

Background for The use of dialog and contextual information from a virtual environment to generate metadata for avatar animation
Some software applications can create virtual or physical objects within a Virtual Reality (VR), or Augmented Reality (AR), environment that allows for user interaction. Some VR applications allow users to interact with virtual objects, play games or watch animated avatars in three-dimensional graphic environments. These applications can also offer an Augmented Reality environment where users are able to interact with virtual objects and/or animated avatars located in their actual environment as well as physical objects.
Developing a VR/AR app can be time-consuming and challenging. Developers must create code to receive and process data from various input devices as well as code to animate avatars and create objects in the virtual environment. It can be time-consuming and difficult for developers to create realistic and customized animations of avatars in a virtual world. The developer must, for example, specify the different models that will be included in the virtual environment, determine the layout, and create custom animations to make avatars look engaging.
The following detailed description is aimed at technologies for a Framework that provides Virtual Reality Applications (VR) and/or Augmented Reality Applications (hereafter collectively called a “VR/AR Application?”). Access to multiple services. Developers of VR/AR applications do not have to write programming code in order to implement the features of one or more services. Instead, they can use functionality that is already available through a network of service providers. A VR/AR application, for example, can be configured to use one or more of the following services: graphical recognition, automatic speech recognition, text-tospeech, search, context, and so on. The VR/AR application may also use other services such as speech input ingestion, virtual platform services and animation services.
A speech input service can create, modify or otherwise add metadata to speech markup data, which is then used by animation services for further processing. Text can be entered into the system to create SMD. This SMD is then used to create animated avatars that interact within a virtual world. Text can be used to generate audio data that is synchronized with animations during playback to produce avatars who speak the text in a natural manner and move naturally, possibly engaging and gesturing towards objects or other avatars within the virtual environment. For example, input text could include: “I’m going to eat this apple.” The virtual platform may create and define a virtual environment that includes the avatar, object_apple and other objects. The object_apple can be tagged using metadata to indicate that the object is an apple. Other tags, such as ‘fruit’,’red?, or a food tag, may also be used. The word “apple” is used during the creation of the SMD. The tag ‘apple’ may be linked to the word. The speech input service can create metadata to associate the word “apple” with. The text may contain the object “object_apple”, which is an object identifier. An example SMD could be: “I’m going to eat this apple?”
In some embodiments, input text can include text that will be spoken by several avatars. The text could include, for example, text from a text that includes multiple speakers. The speech input service can analyze the text and identify speakers (avatars), which will be associated with specific words. The text could include words that are associated with the first speaker (first avatar), and words that are associated with the second speaker (second avatar). The input text can include any number of speakers, and is not limited to just two (or two avatars). Speech input ingestion services may create metadata or label words to be used in creating different audio and/or animated avatars. The avatars can be chosen based on the avatars available in a virtual world, user input, historical data, or randomly selected. First words can be parsed by a service that converts text to speech to create audio for the first avatar, while second words are parsed by the same service and converted to audio for the second avatar. The first animations can be created for the avatar. These animations could include the avatar talking words but also include animations such as the avatar listening to (and responding to) another avatar or interacting with an object.
The text can be used to indicate the effects of objects that are in the virtual world and/or those in the real-world environment, e.g. Internet of Things, and/or other devices that can exchange data via wireless signals with the services and/or devices described in this document. Animations of virtual objects may be included, including movement and/or operation (e.g. output of sound, light, etc.). Input text can include, ‘I am turning on lights.’ The services described in this document may create animations that show an avatar interacts with a virtual switch and then shows a light changing state from?off? The services described herein may create animations to show an avatar interact with a virtual light switch in the virtual environment and then depict a light changing from a state of “off” By creating visual effects that show the same. The input text can be configured to control a real-world light or other devices like haptic devices, sound producers, air movement devices (e.g. fans, mist machines, etc.). Vibration devices to provide haptic feedback and/or real-world devices can be controlled via wireless signals. The speech input service can analyze the text input to identify virtual objects or real-world objects that could be suitable for animations and other effects. The speech input service can create metadata or include information in the SMD in order to start object animations and/or other effects. For example, the speech input service could use speech and animation in conjunction with words that indicate object animations and/or other effects. The SMD in the above example can be modified to look like the following: “I am turning on?”
?lights?
The input text can include explicit words that enable the association of tags, speakers and/or real-world objects (e.g. IoT devices etc.). In some cases, however, contextual information can be used to create associations. When turning on a lamp, for example, context could suggest a tag “light switch”. The phrase “turning on a lamp” is related to the tag “light switch”. As discussed in this document, other contextual information can be aggregated using machine learning algorithms or historical data.
An Animation Service can be configured to provide animated avatars. Animations can be used to entertain users, provide a virtual host, or to introduce an object to them. The animation service can allow a user create an avatar who speaks the words they choose and then performs captivating animations and gestures. These avatars can be linked to another site, downloaded, executed in different environments and/or shared. The term “avatar” is used in this article. The term “avatar” refers to a character generated from predefined inputs, such as text, code, or other inputs that drive creation and animation of an avatar. This may or may include animated characters animated using real-time input by the user via user devices (e.g. input via a game controller, etc.). The avatars can be animated and generated using predefined inputs, which do not specify the movements of animation.
In some cases, an avatar may speak the text that is input by the animation service. Text can be converted to audio using a text to speech service. This may be done locally, remotely, or even a combination. Audio data can be played back to simulate a voice reading the text. Speech markup data can include information that enables audio data and animation of an avatar based on text. SMD can include speech synthesis Markup Language (SSML) and other text formats that are used to create audio data and animations.
The SMD can be created using input text. This text could be any type of text that is fed into the system. The SMD can include sentences, words, and/or phonics symbols from the text. Each of these may contain time codes that specify the time at which a specific element of audio data will be played back (e.g. playback of an individual sound at a given time). SMDs may also include information such as emotion values or other information that influences or describes sounds and attributes in the audio data. The term “phonic symbols” is used here to describe the audio data. The term ‘phonic symbols’ may refer to phenomes or other symbols that represent distinct sounds and are associated with imagery, animation movements and/or respective imagery. Some phonics symbols can be used to represent the same viseme. The sounds of?ch? The sounds for?ch? “The same visemes and phonic symbols may be used to represent different letters.
![]()
The animation service can receive the SMD which is then processed to create animated avatars. The animation service, for example, may create first animation sequences based on the phonics symbols and different time codes that are associated with each symbol. The animation service can generate second animation sequences for skeletal components based on at least part of the words, and the time codes that are associated with the words or combinations of them. The skeletal elements may include a head, torso and legs. They may also include arms, hands and fingers. The animation service can determine animations by using selected words that are associated with gestures or animation sequences. The animation service can generate combined animations of the avatar, which include both the first and second animations.
The animation service can be designed to interact either with one or multiple users, and/or with the virtual world presented by the VR/AR app. The animation service can generate animations which cause the avatar to interact within a virtual world, or appear to interact in the real-world (e.g. look at someone or something identified in a certain location in the world using images captured by one or more cameras). The animation service can generate animations that cause the avatar to interact with objects within a virtual environment, appear to interact with objects in the real world (e.g., look at a person or object identified at a specific location in the real world via image capture from one or more cameras), both. In some cases, the animation service can receive input signals that identify objects and their locations (e.g. coordinates) in the real-world. Recognition services may be used to create tags for the objects and/or determine locations/coordinates that locate the objects/people relative to the display or some other reference point. “The animation service can generate an animated sequence that shows the avatar looking at a real-world object or person based on input signals.
The different services used by a VR/AR app can be identified at runtime or preconfigured to be used with the VR/AR app. The VR/AR application, for example, can be configured so that it identifies applications and/or service relevant to the context of a user’s interaction with the virtual environment. The term “relevant” is used in this document. The term’relevant’ can refer to an app or service which provides data and/or functionalities that are applicable to the context. The term “context” is used. The term ‘context’ can refer to the environment, background, setting, or situation surrounding a specific event or situation. Context data can include speech data and gesture data. It could also be location data or movement data. Sensors on a computing device could be used to determine some context data. Sensors on a computing system associated with a particular user could be used to measure the speed, location, and other parameters of the device. Context data may also include information about a user’s current activity. A current activity could be a user’s action in the virtual environment.
Software developers can create VR/AR apps using an Integrated Development Environment. “Software developers may develop VR/AR applications using an Integrated Development Environment (?IDE?) One or more APIs may be included that define functionality to connect the VR/AR app to other services or tools that a software developer might use to create a VR/AR app. APIs can be used, for example, to define custom events, to send a message from one application to another, to request context data to a computing device and so on. SDKs and/or APIs can also be used to alter the behavior of an operating system or another application. “For example, one part may use the API to communicate to another part in response to certain data.
In certain examples, one of more services may use one or more machine-learning algorithms to create or refine data for the VR/AR applications. As a service collects more data over time, it may alter the data it provides. In response to additional data, the machine learning algorithms may be improved. The following figures will provide additional details about the components and processes that were described above to select and use applications based on context.
It is to be understood that the subject matter described herein can be implemented as a process on a computer, as an apparatus controlled by a processor, as a computing system or as an article, such as a storage medium readable by a processor. The subject matter is described in this document in a general context as program modules that run on one or multiple computing devices. However, those in the know will understand that other implementations can be combined with other types program modules. Program modules are generally routines, components, datastructures and other types that perform specific tasks or implement abstract data types.
The skilled person will understand that the subject matter described in this document can be used on other computer systems configurations than those described in the present disclosure, such as multiprocessors, consumer electronics with microprocessors or programmable components, minicomputers or mainframe computers and handheld computers. Other devices include e-readers or personal digital assistants, mobile phones, tablet computers, special purpose hardware devices or network appliances. The examples of the present invention can be used in distributed computing environments. Tasks may be performed remotely by computing devices linked via a communication network. In a distributed computing system, program modules can be stored in local or remote memory devices.
In the detailed description that follows, there are references to the accompanying illustrations that are a part of this document and which show specific examples. The drawings are not to scale. The figures are numbered similarly to represent similar elements. Or?FIGS .?).
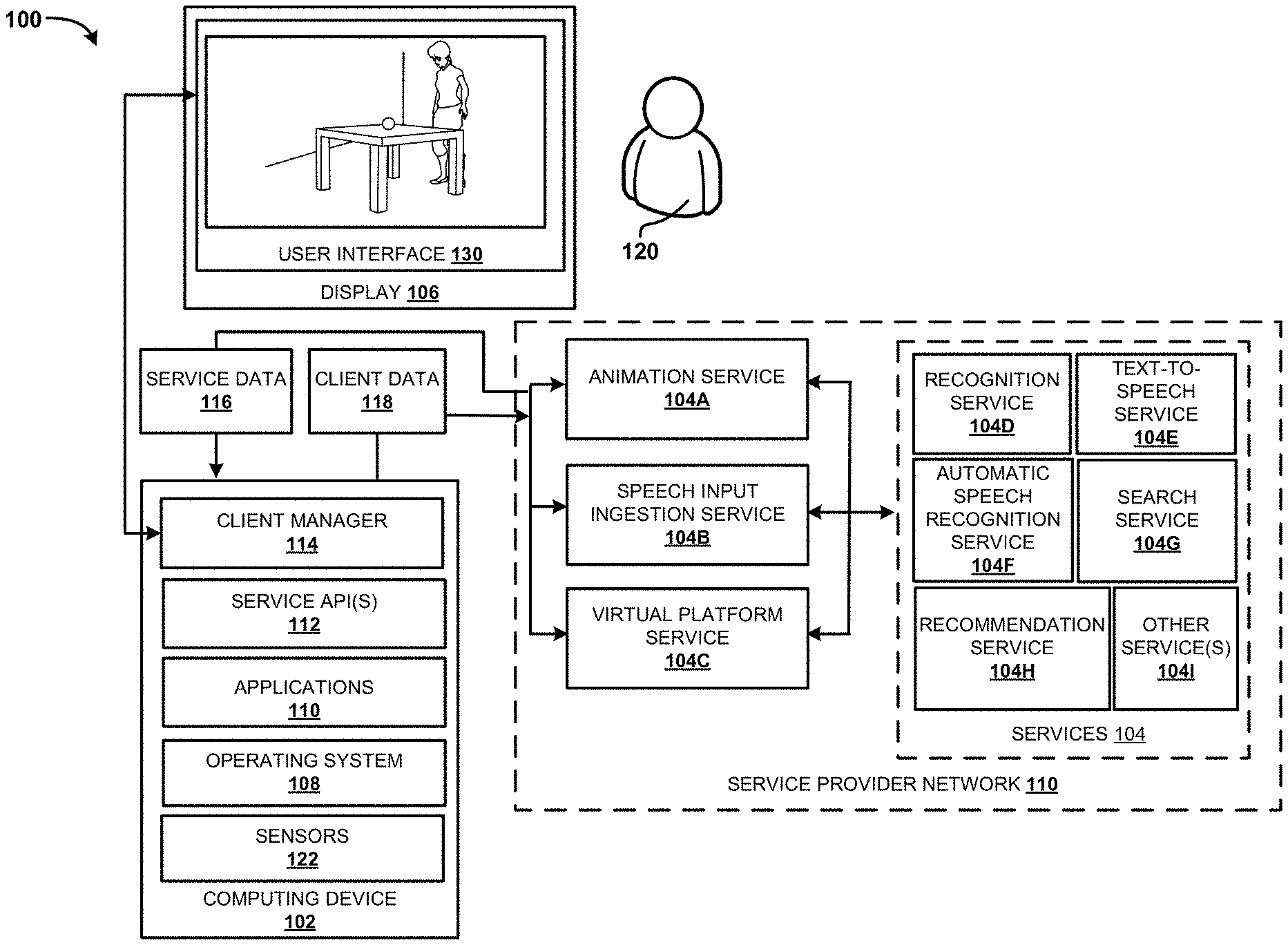
Referring to FIG. According to the examples given here, FIG. 1 illustrates an operating environment in which a VR/AR app utilizes various services from a service provider’s network 110. The operating environment shown in FIG. Computing device 102, display 106, and services 104 are included in FIG. In some configurations, computing device 102 can be configured as tablet computer, smart phone, personal computer (?PC?) Other examples include a gaming system, set-top box or smart TV, or a video game console. In other examples, a part of the functionality provided by a computing device 102 can be provided either by one or more services, or a network of service providers 110. (See the network of service providers 110 shown in FIG. 12). The services 104 are illustrated as an animation service (104A), a speech input ingestion (TTS) (service) 104B, virtual platform (service) 104C, recognition service (104D), text-to speech (TTS), automatic speech recognition (ASR), recommendation service (104H), and other services (1041). In other configurations, the service provider 110 or another network can provide fewer or more of these services.
The services 104, or the network of service providers 110, may include one or several application servers, web servers, data storage devices, network appliances or dedicated hardware devices. Other server computers or computing device can also be used to provide the functionality for the different services. In these examples the computing device can be equipped with minimal hardware to connect via a computer network to a platform for network-based computing. The computing device may use the network to communicate with other devices or resources. The computing device 102, for example, can access the Animation Service 104A or other services. Below are more details about the operation of services 104.

Click here to view the patent on Google Patents.