
Invented by Todd; Stephen J., Pande; Pankaj

Every day, huge amounts of data are created by devices, sensors, and people. But can we trust this data? Is it safe to use data from unknown sources? A new patent application offers a smart way to answer these questions. It shows how to use something called a “data confidence fabric” to make data more trustworthy, while also keeping it private. In this article, we will explore why this technology matters, what makes it new, and how it works in simple terms.
Background and Market Context
Let’s start by thinking about why data trust and privacy are so important today. In our world, almost every device can collect and share information. Smartphones, smart watches, home assistants, and even cars are constantly generating data. Businesses and governments want to use this data to make better decisions, improve products, and deliver services faster. But there’s a big problem: not all data is good, and some of it can reveal private details that people want to keep secret.
If a company uses data that is wrong, old, or even fake, the results can be bad. Imagine a traffic app using bad data to send drivers into a traffic jam. Or a hospital using wrong sensor readings to make the wrong choice for a patient. That’s why businesses want to know if they can trust the data they are using.
At the same time, people are afraid of losing their privacy. They don’t want their personal information to be shared without their permission. Laws in many countries now require companies to keep data private, especially if it can identify a person. This is not just about hiding names and addresses. Even hidden data can sometimes be connected back to a person if someone tries hard enough. So, companies use special privacy methods like anonymizing (removing personal details) or adding “noise” (making data a bit fuzzy) before sharing or using the data.

But there’s a catch. Making data more private can also make it less useful. For example, if you hide where data comes from, how do you know if it is accurate? If you mix up data to hide personal details, you might lose important clues about whether the data is real. As companies and governments rely more on data for things like artificial intelligence, smart cities, health care, and market research, they need a way to balance privacy with trust.
This is where the idea of a data confidence fabric comes in. It’s like a smart layer that sits between the devices that create data and the applications that use it. Its job is to score data based on how much it can be trusted, while also making sure private details are protected. If done right, this technology could help everyone – making data safer for users and more useful for businesses.
Scientific Rationale and Prior Art
To see why this invention matters, let’s look at how things are usually done. In many systems today, data comes in from different sources – maybe sensors, user devices, or even other companies. Before this data is used, it goes through privacy checks. These checks might remove names, addresses, or other personal details. Sometimes, the data is mixed with random noise so it’s harder to connect it back to a person. Methods like “differential privacy” are used in big tech companies to protect user data when they share statistics or train machine learning models.
Another common step is data aggregation. This is when lots of small pieces of data are combined into bigger summaries. For example, instead of showing where every person went in a city, a traffic app might only show how busy each street is. Aggregation helps protect privacy, since it’s harder to pick out one person’s data from a big group.
But there’s a big gap in these old methods. Once data is made private, it’s hard to know if it came from a trustworthy source. A sensor might be broken. A person might enter wrong information. Or someone might even try to trick the system with fake data. If the source is hidden, there’s no way to check if the data is real. Some systems try to solve this by only using data from trusted devices or by checking the history of the data. But most of the time, once the data is anonymized, all the clues about where it came from are lost.
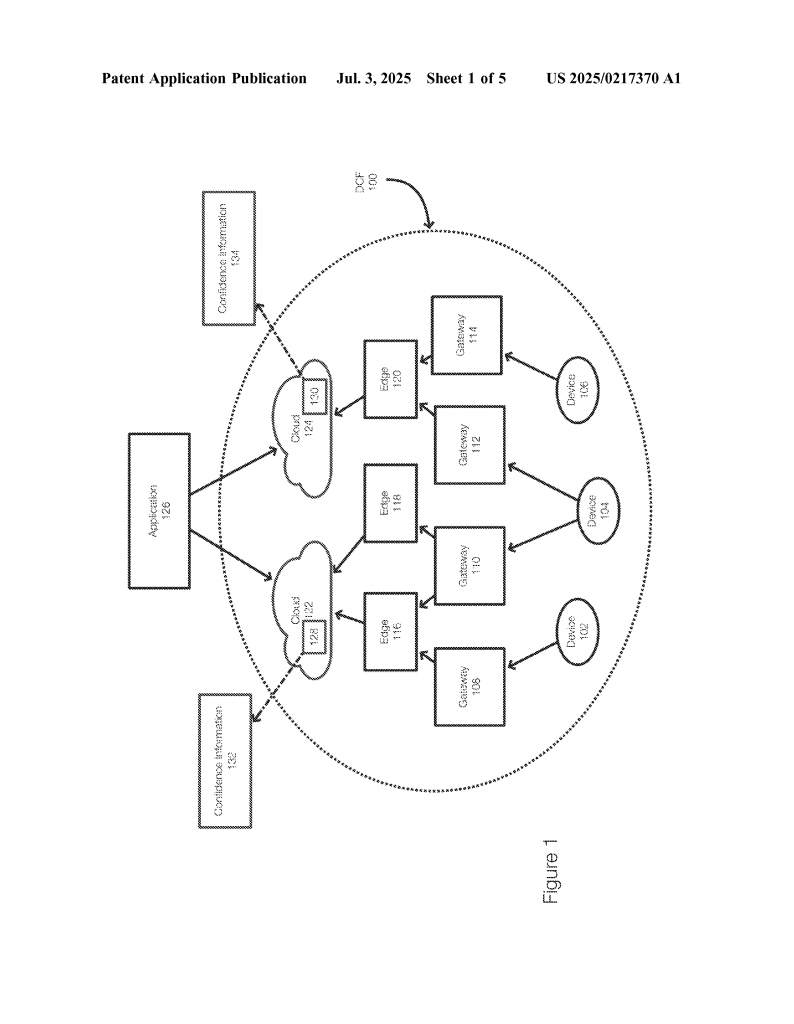
This creates a trade-off between privacy and trust. The more you hide about where data comes from, the harder it is to trust it. If you want data to be private, you might have to accept that some of it is wrong or fake. On the other hand, if you want to only use trusted data, you might have to give up some privacy. This problem is especially hard in areas like health care, smart cities, and artificial intelligence, where both privacy and trust are very important.
Some research has tried to solve this problem by using special ledgers to track data history, or by adding cryptographic proofs that show data hasn’t been changed. But these methods can be slow, expensive, and hard to use at a large scale. Until now, there hasn’t been a simple, flexible way to score data for trust while also keeping it private during aggregation.
This is why the new patent application is important. It introduces the concept of a data confidence fabric that scores each piece of data for trust, even as privacy steps are applied. This score can be used during aggregation, so that more trustworthy data has a bigger impact on the final result. It also lets applications and users see how confident they can be in the aggregated data, even if the original sources are hidden.
Invention Description and Key Innovations
So how does this new invention work in practice? The heart of the system is the “data confidence fabric” – a smart layer made up of hardware, software, and special services. Here’s how it works, step by step, using plain words:
First, data comes into the system from different sources, like sensors, user devices, or online services. As soon as the data enters, the data confidence fabric starts to work. It applies a set of “trust insertion technologies.” These are checks and processes that measure how trustworthy the data is. For example, the system might check if the device sending the data is secure, if the data has been changed along the way, or if it comes from a source with a good history.
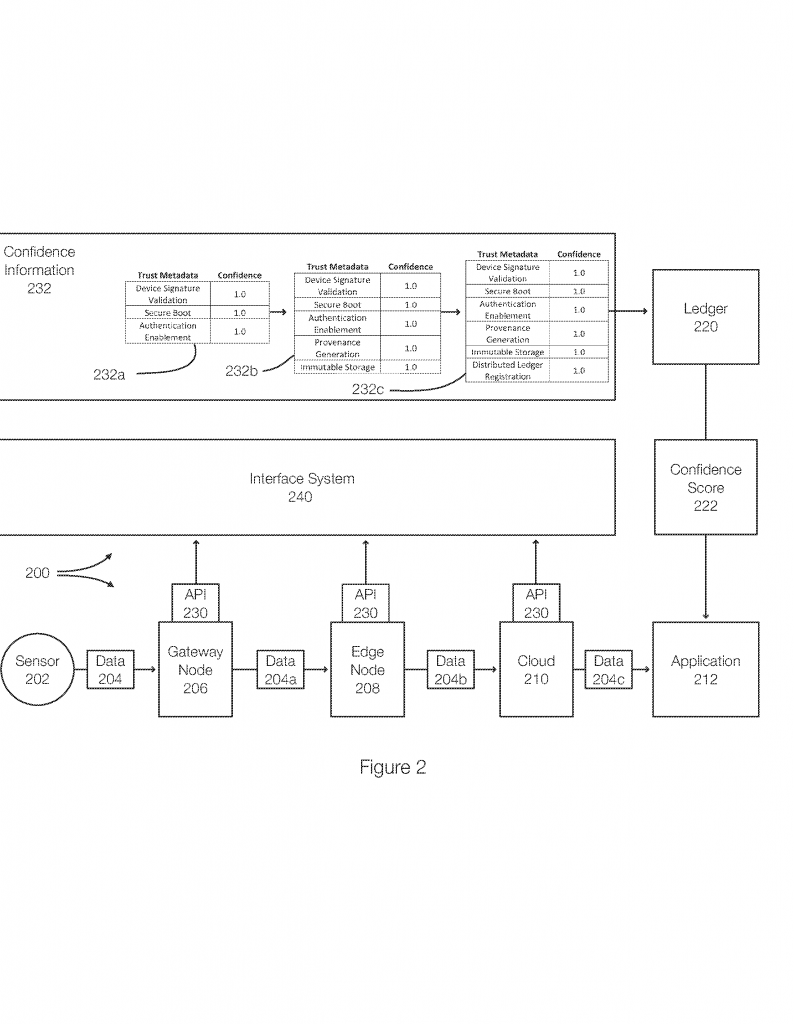
Every time the data passes through one of these checks, it gets a confidence score. This score gets higher if the data passes more checks or comes from a trusted source. It might go lower if the data comes from a new or unknown device. Each step is recorded, and the score is added to the data as a tag. Think of it like a report card for each piece of data, showing how much it can be trusted.
As the data moves through the system, more checks can be added. For example, when the data is stored in a secure way, the score might go up. If it passes through more secure devices, the score can increase. All these scores and steps are recorded in a ledger, which is a secure log that can’t easily be changed. This ledger helps make the whole process auditable, so applications can look back and see how the scores were made.
Now comes the clever part: aggregation. When it’s time to combine lots of data points into bigger summaries, the system doesn’t just mix everything together. Instead, it uses the confidence scores to decide how much each piece of data should count. If a data point has a high score, it will have a bigger impact on the final result. If the score is low, it might be given less weight or even left out. This way, the final aggregated data is shaped more by data that can be trusted.
But what about privacy? The system also uses smart privacy techniques like anonymizing data, applying differential privacy, or using methods that keep personal details hidden. Even as these privacy steps are applied, the confidence score stays with the data. This means the aggregated data is both private and trustworthy.
The final result is a set of aggregated data, along with an overall confidence score. This score tells users and applications how much they can trust the results. For example, a city traffic system could use this to only show results when the overall confidence is high. A health care app could use it to make sure only good data is used to train machine learning models. The system can also store all these scores and steps in a secure ledger, so that anyone can check later how the scores were made.
This invention brings several key innovations:
– It creates a way to score each piece of data for trust, even as privacy steps are taken.
– It uses these scores during aggregation, so that trustworthy data has more impact.
– It keeps the scores and the audit trail, making the process transparent and auditable.
– It works in many environments, from edge devices close to the data, to the cloud, to on-premises systems.
– It’s flexible, so it can use different kinds of privacy and trust checks depending on the need.
By combining privacy and trust in one system, the data confidence fabric solves the old trade-off. Now, companies and users can have both: privacy for the individual, and trustworthy results for the business.
Conclusion
The world is demanding better data for smarter decisions, but privacy and trust are often at odds. The technology described in this patent application changes the game. By using a data confidence fabric, we can score data for trust while still protecting privacy. This lets businesses, governments, and users get the best of both worlds: private data that is also reliable. As more devices and applications rely on data, this kind of system will become even more important. The future of data is not just about collecting more, but about making sure we can trust and protect what we use. This invention is a big step in that direction, and it opens new doors for safe, smart data aggregation everywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217370.