
Invented by Shaw; Peter Thomas, Joshi; Mandar, Toutanova; Kristina Nikolova, Cohan; James Fischl, Berant; Jonathan Haim, Lee; Kenton Chiu Tsun, Pasupat; Panupong, Hu; Hexiang, Khandelwal; Urvashi

Welcome! Today we are diving deep into a new patent application that covers a way for computers to control graphical user interfaces (GUIs) using only pictures of the screen and plain language instructions. If you’re curious about the future of automation, digital assistants, or just how machines can “see” and “act” like people, this article is for you. We’ll break down the background and context, review the science and earlier ideas it builds on, and then explain what’s new and special about this invention. Let’s get started!
Background and Market Context
To understand why this invention matters, think about how we use computers every day. Most of us interact with apps, websites, and tools using our eyes and hands — we look at buttons, menus, and icons, and then click, tap, or type to get things done. But what if a computer could do the same, just by looking at pictures of the screen and reading simple requests like, “Add this item to my cart,” or “Turn off the living room lights”?
For years, companies have tried to build digital helpers and robots that can use apps the way people do. These helpers, called digital assistants, are found in smartphones, smart speakers, and even cars. They let you say things like, “Set an alarm for 7 AM,” or “Play my favorite song.” But there’s a problem. Most of these helpers can only control apps that have special “doors” (APIs) designed just for them. If an app doesn’t have one of these doors, the helper can’t do much.
This means that when a new app comes out, or an old one changes its look, digital assistants often can’t keep up. For businesses, this leads to lots of wasted time and money making special connections for every single app. For users, it means assistants are less helpful than they could be.
Now, think about robots that need to control computers, or special software for people with disabilities who can’t use a mouse or keyboard. They all face the same challenge: they need to “see” what’s on the screen and “act” like a person would, even if they don’t have special access to the app’s code.
This is where the market is heading: toward automation that works everywhere, even when it doesn’t have a special invitation. Businesses want to automate boring or repetitive tasks across apps. People want digital helpers that just work, no matter the app. And as more and more things move online, the need for this kind of universal automation is only getting bigger.
The patent we’re discussing today tackles exactly this problem. It aims to give computers the power to look at a screen, understand what’s happening, and carry out tasks by just “seeing” and “reading” — no special doors or inside access needed. This could make digital helpers smarter, help people with special needs, and automate work in ways that were not possible before.
In short, the context for this invention is a world where computers need to act like people in any app, at any time, without waiting for special access. The market is huge, covering business automation, digital assistants, testing of apps, robotics, and accessibility tools. The old way — building custom connections for every app — just doesn’t scale. The new way, as this patent shows, is to let computers learn to “see” and “act” on their own.
Scientific Rationale and Prior Art
Let’s look at how computers have tried to solve this problem before and what science this invention builds on. Traditional automation tools, like web bots, usually need to “peek behind the curtain” of an app. They look at the app’s code, its blueprints (like HTML or the DOM for web pages), or special instructions from the app’s makers. This works well if you have access, but many apps don’t share this information, or it changes often, breaking the automation.

Some digital assistants can control a few apps directly because those apps have special connections (APIs) made just for them. But this is the exception, not the rule, and making these connections for every app takes a lot of effort. Plus, when an app is updated, the connection can break, and someone needs to fix it.
Researchers have tried to teach computers to use just pictures of the screen (like screenshots), but this is hard. A picture of a screen doesn’t tell you what each button does, what’s important, or where to click to finish a task. The computer needs to “see” and “understand” at the same time, just like a person.
One early idea was to train computers to read the screen, recognize shapes, and spot buttons or text, similar to how people use their eyes. This led to the use of machine learning — teaching computers with lots of examples, so they can spot patterns. For example, researchers built models that could look at a screenshot and guess what parts were clickable or what text was shown.
Some of the best results came from mixing two kinds of information: the picture (pixels) and the app’s inside structure (like the DOM). When both were available, computers could get close to human-level performance. But if you took away the inside information and left only the picture, performance dropped a lot — sometimes by 75% or more. That’s because the computer couldn’t “see” all the details it needed.
To help with this, scientists used deep learning models called transformers, which are very good at handling sequences, like words in a sentence or patches in an image. Some models, like Pix2Struct, were trained to take screenshots and output a description of what’s on the screen. Others tried to go a step further and figure out what to do next: what button to click, what text to type, or how to scroll.
But even with these advances, there were big challenges:
- Learning just from images is hard, because the computer has to figure out what each thing on the screen does.
- Mapping a plain language instruction (“Book a flight”) to a series of screen actions is a big leap.
- Most models were too big and slow for real-world use, or they needed lots of special tweaking for each app.
Researchers also used ideas from reinforcement learning, where the computer tries different actions, gets rewards for good results, and learns over time what works best. This is a bit like training a dog: try something, get a treat if you’re right, and remember it for next time.
Some systems tried to break down the problem into steps: first, recognize what’s on the screen; second, figure out what the instruction means; third, decide on an action; and finally, do it. Others tried to do everything at once, but this was often overwhelming for the computer.
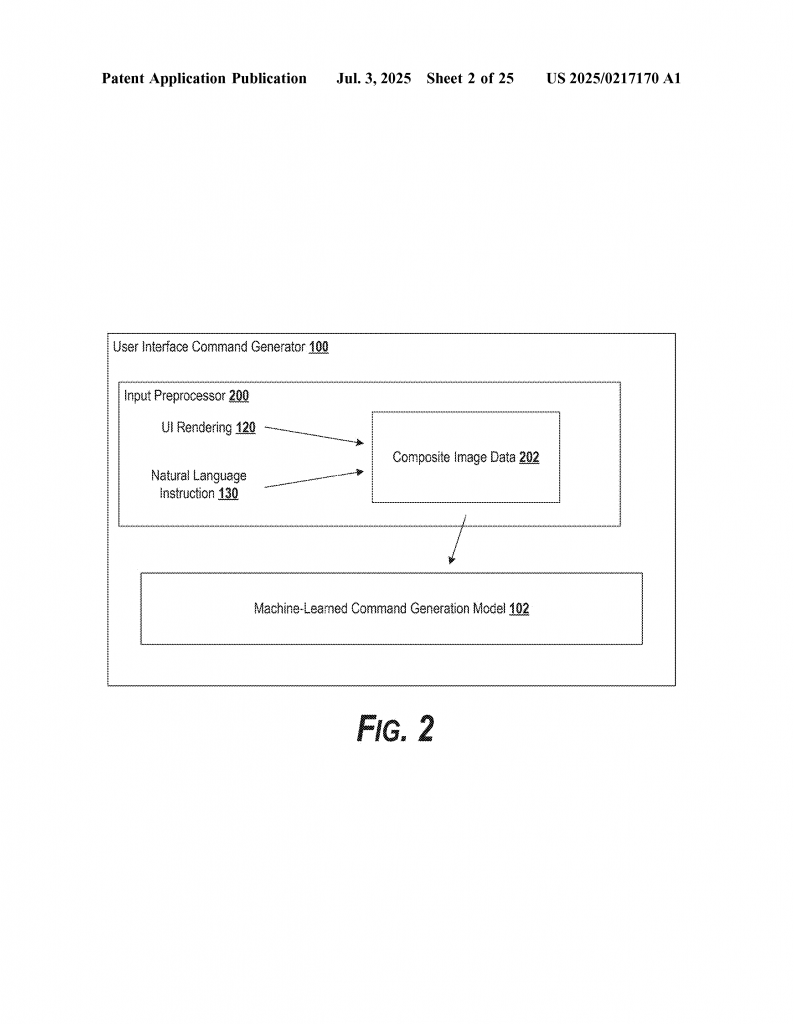
So, in short, the main scientific ideas are:
- Using deep learning models (like transformers) to process both images and text.
- Pre-training models on lots of screenshots and tasks so they “understand” general app layouts.
- Fine-tuning on specific tasks so the model learns how to act in real-world situations.
- Using reinforcement learning and reward signals to improve over time.
The key limits of earlier work were that they either needed special inside access to each app, didn’t work well with just pictures, or required lots of manual setup. The invention in this patent builds on these ideas, but aims to solve these limits by teaching the computer to control any app using just screen images and plain language — the same way a person would.
Invention Description and Key Innovations
Let’s break down what this invention actually does, and why it’s different from what came before.
At its core, the invention is a system that takes two things:
- A natural language instruction (like “Add the red sweater to my cart”)
- A picture that shows what’s on the screen right now (a screenshot or similar image)
Then, it uses a special machine-learned model to figure out what action to take — for example, where to click, what to type, or how to scroll. The model has been trained in several steps, so it’s good at both “seeing” the screen and “understanding” what the instruction means.
Here’s how it works in simple terms:
When you give the system an instruction and a screenshot, it puts both into the model. Sometimes, the instruction is turned into an image and combined with the screenshot, so everything is handled as a picture. Other times, the instruction and the image go in separately and are processed by two different “eyes” (encoders) inside the model. The model then combines what it “sees” and what it “hears” to figure out what to do next.
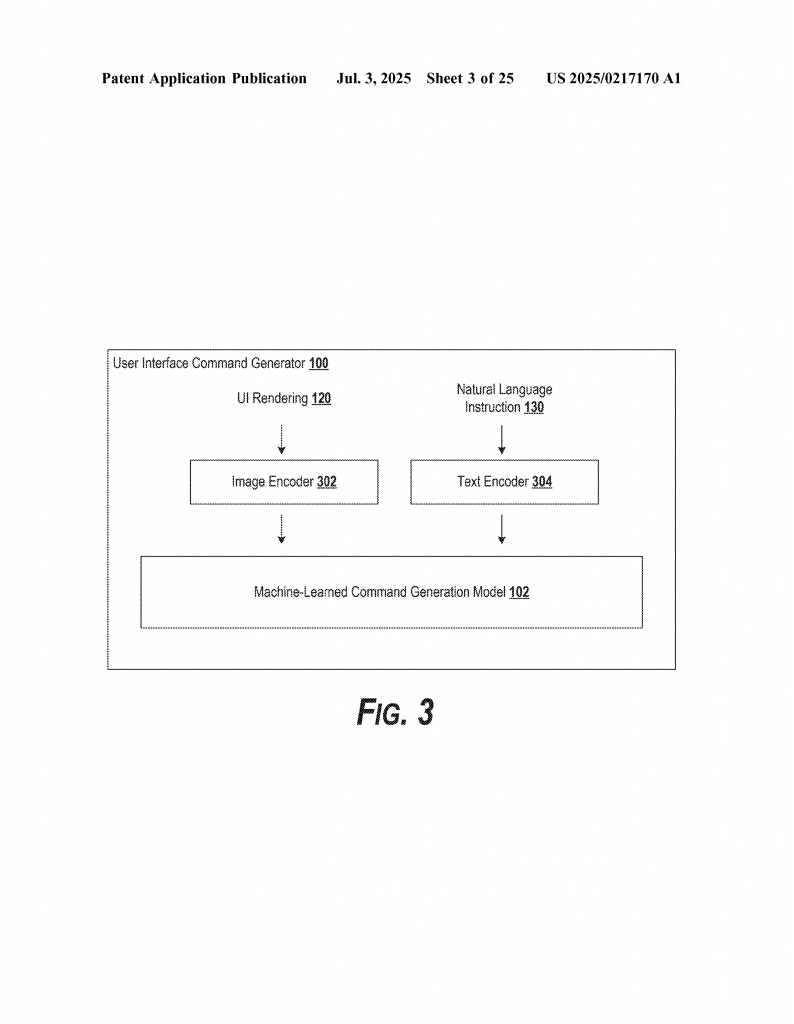
The model itself is trained in a smart way:
- First, it learns to recognize what’s on the screen by matching screenshots to known interface structures (like HTML layouts). This is called the interface recognition objective.
- Next, it learns to follow instructions by matching screenshots and instructions to the right actions, using lots of examples (the interface navigation objective).
- It can also learn to read text from images (the text recognition objective), making it better at understanding labels, buttons, and other words on the screen.
After this training, the model can take any instruction and any screenshot and tell the computer what to do: click here, type this, scroll down, etc. It outputs commands in a simple, clear way, like “click 35 120” (meaning click at those screen coordinates).
To actually carry out the action, the system uses an interpreter. This part takes the model’s command and turns it into real input for the computer — moving the mouse, clicking, typing, or calling an app’s API if one is available. The interpreter can be rule-based (using a set of if-then rules) or use its own machine learning model to figure out what to do.
One clever part of the invention is how it trains the model to make better decisions over time:
- It uses a process called tree search (like Monte Carlo Tree Search), where it tries out different possible sequences of actions, tracks which ones lead to the best outcome, and then updates the model to prefer those actions in the future.
- It splits the model into a policy network (which picks actions) and a value network (which judges how good a situation is). This lets the system balance trying new things with picking actions it knows work well.
All of this is designed to work fast and to use less computer power than older models. The system can be made small enough to run on a regular phone or computer, not just in a giant data center.
What makes this invention stand out?
- It doesn’t need inside access to the app. It works with just the screen image, like a person.
- It can adapt if the app changes its look — no need for updates or fixes.
- It works across many apps, websites, and devices, even if they were never designed for automation.
- It helps automate boring tasks, can make digital helpers smarter, and improves accessibility for users who can’t use a mouse or keyboard.
Let’s see a few real-life examples:
- Voice assistant: You say, “Book a flight to New York on the 15th,” and the assistant uses the model to look at the travel site, click the right buttons, and fill in the details — even if the site has no special API.
- Accessibility: Someone who can’t use their hands gives a voice command, and the computer clicks, types, or scrolls for them on any app.
- Testing: Software testers can automate checking lots of apps by letting the model “drive” them, just by describing tasks in plain language.
- Robotics: A robot with a camera can control a tablet or phone by “seeing” the screen and acting through touch, even if it’s a new app.
The patent also covers ways to make the system available as a service, so other programs or devices can send images and instructions and get back actions to perform.
In terms of technical details, the invention uses a mix of machine learning methods (supervised learning, reinforcement learning, and deep learning models like transformers), but the main focus is on:
- Learning from just pixels and plain language, no inside access needed.
- Producing simple, actionable commands that any system can use.
- Training in steps (pre-training, fine-tuning, reward-based learning) to make the model both general and effective.
- Reducing the size and energy use of the models, so they are practical for daily use.
In summary, this invention is like giving computers the power to “see” what’s on the screen and “do” what you ask, in any app, at any time — just like a person. It’s a big step forward for automation, digital assistants, accessibility, and robotics.
Conclusion
This patent shows a new way for computers to control apps using only what you or I see on the screen and simple instructions. By training smart models to “look” and “listen,” then decide what to do, the system breaks free from the limits of old automation tools. Now, digital assistants, robots, and accessibility tools can all use any app, no matter how it’s built or how often it changes. The invention is practical, flexible, and ready for real-world use. As more of our work and play moves to digital devices, inventions like this will make sure that anyone — or any helper, human or machine — can get things done quickly, easily, and everywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217170.