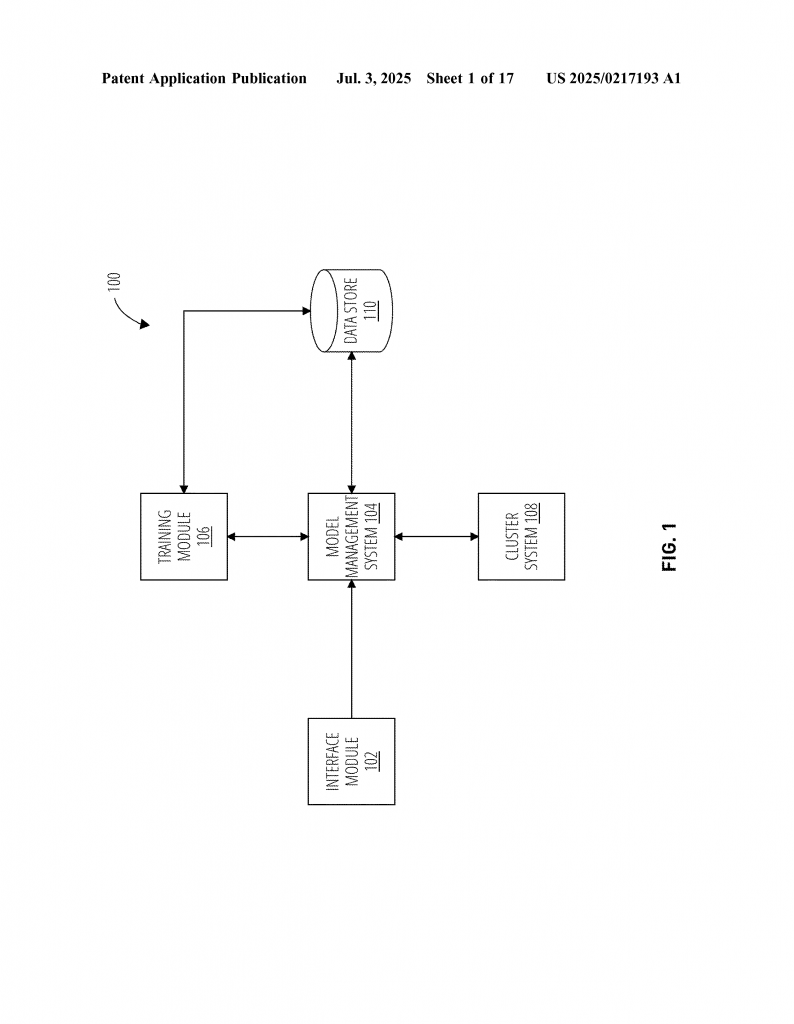
Invented by Wang; Yuanyou, Vangala; Naveen, Anand; Mayank, Jain; Kunal Kumar, Mathew; Jose, Jose; Eapen, Goyal; Divyanshu, Chihnara; Asmita, Abdullah; Arif, Dantu; Anand, Adobe Inc.
A new patent application introduces a clever way to make machine learning models faster and cheaper to use, especially when you need many different versions for different jobs. Let’s break it down into simple ideas that anyone can follow, starting with the market reasons for this invention, the science and older ways of doing things, and then a clear look at what this new idea actually does.
Background and Market Context
Let’s start simple. Machine learning (ML) is everywhere now. It helps phones recognize faces, lets cars see the road, and even helps doctors find diseases faster. But, there’s a problem: good ML models are big, slow, and need lots of computer power. They eat up memory, take time to start, and can be very expensive to run, especially in places like hospitals, cars, or small gadgets where there isn’t much computer power to spare.
Companies and researchers love to use “base models” — big, smart, general-purpose models trained on huge piles of data. But most real-world jobs need something more focused. For example, a general model knows about all animals, but a zoo app might just want to recognize birds. To do this, people fine-tune the base model with smaller, special datasets, making “fine-tuned models” that are good at just one job.
Here’s where things get tricky. If you have lots of apps — each needing its own fine-tuned model — you end up with tons of almost-the-same models running on your servers. That’s wasteful because most of each model is exactly the same! This means more storage, slower start times, and higher costs.
Imagine a library where every book is the same except for the last chapter. Instead of copying the whole book over and over, wouldn’t it be smarter to keep the main part once and just swap out the ending as needed? That’s the big idea here.
In today’s world, apps need to serve customers instantly. If it takes minutes just to load the right model because servers have to fetch and set up a whole new copy, users get annoyed, and companies lose money. As more apps want their own “special” version of a model, the old way just won’t work.
So, the market needs a way to:
- Save computer resources by not repeating the same work
- Respond faster to user requests
- Lower costs for storage and data transfers
- Make it easier to manage lots of slightly different models
This is especially important for cloud computing, edge devices, and any place where resources are limited or response time is crucial.
Scientific Rationale and Prior Art
Let’s peek under the hood. Machine learning models, especially the big ones, are built with layers — kind of like a cake. The base layers learn general things (like what an “animal” is), and the top layers learn specifics (like what makes a bird a bird). When you fine-tune a model, you usually keep the bottom layers the same and just adjust the top ones.
In the past, if you wanted ten different fine-tuned models for ten jobs, you’d have to store and run all ten complete models, even though 90% of each model was the same. This led to:
- Wasted memory (because lots of the same data is repeated)
- Bigger network bills (sending big files around)
- Slower startup (waiting for the full model to load)
Some researchers tried a trick called Parameter Efficient Fine-Tuning (PEFT). Instead of tweaking the whole model, they only trained small parts called “adapters” or “layers” — like just swapping out the icing on a cake, leaving the rest untouched. One popular way is called LoRA (Low-Rank Adaptation). This works well but was still clunky to manage at scale.
Older systems didn’t have a smart way to swap these parts in and out on the fly. If you needed a different “icing,” you’d still have to bake a whole new cake each time. That’s slow and expensive.
Container technology (like Docker and Kubernetes) helped a bit, making it easier to run and manage software in neat boxes. But if each box still had a full copy of a big model, it didn’t really solve the main problem: too many copies, too much waiting, too much money spent.
The missing piece was a system that could:
- Keep the main part of the model ready to go
- Quickly fetch just the special parts when needed
- Plug those parts into the main model on demand
- Do all this automatically, so users don’t wait
No prior art was able to do this in a simple, flexible, and efficient way for lots of different models and layers, with caching and orchestration built-in.
Invention Description and Key Innovations
Now, let’s get to the heart of the patent and see what’s really new and helpful.
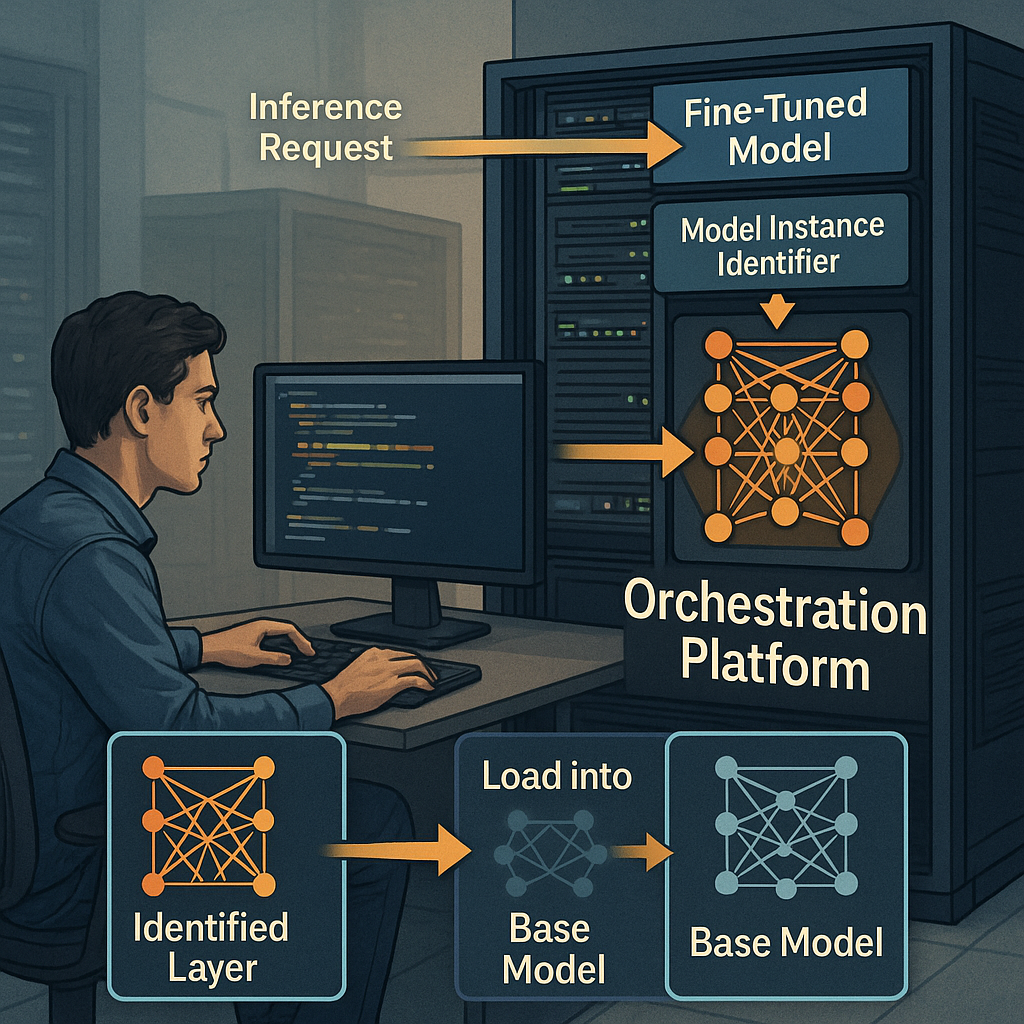
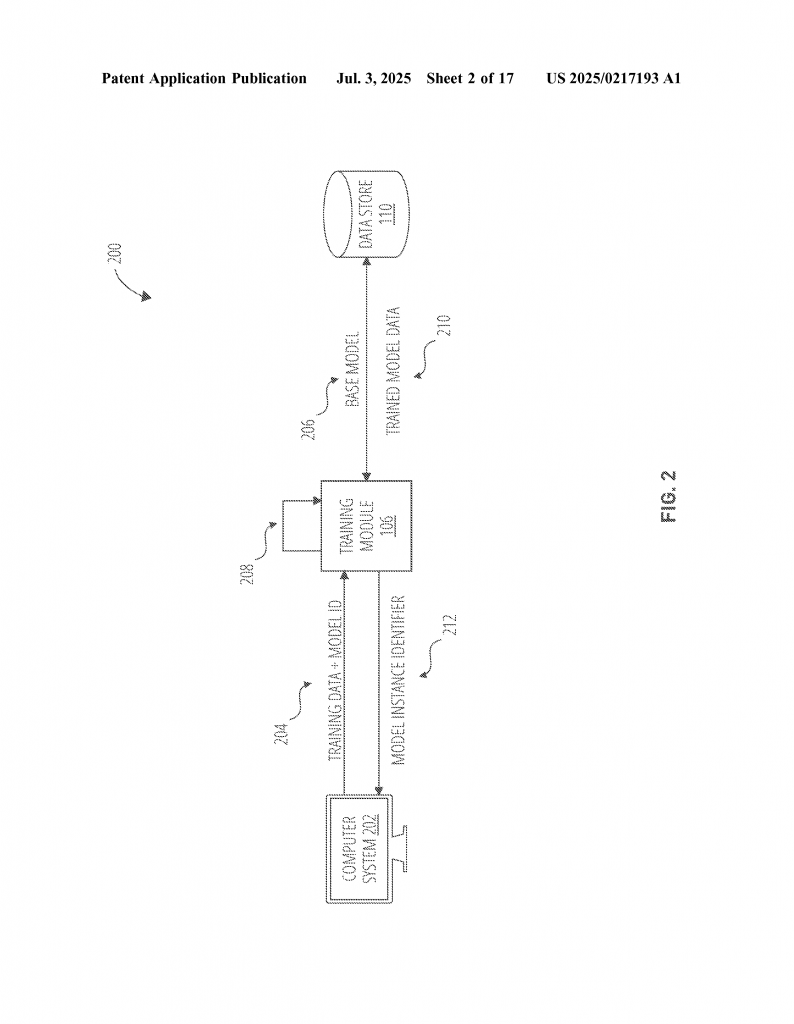
The invention is a smart orchestration platform that acts like a model librarian. Here’s how it works, step by step, in very simple language:
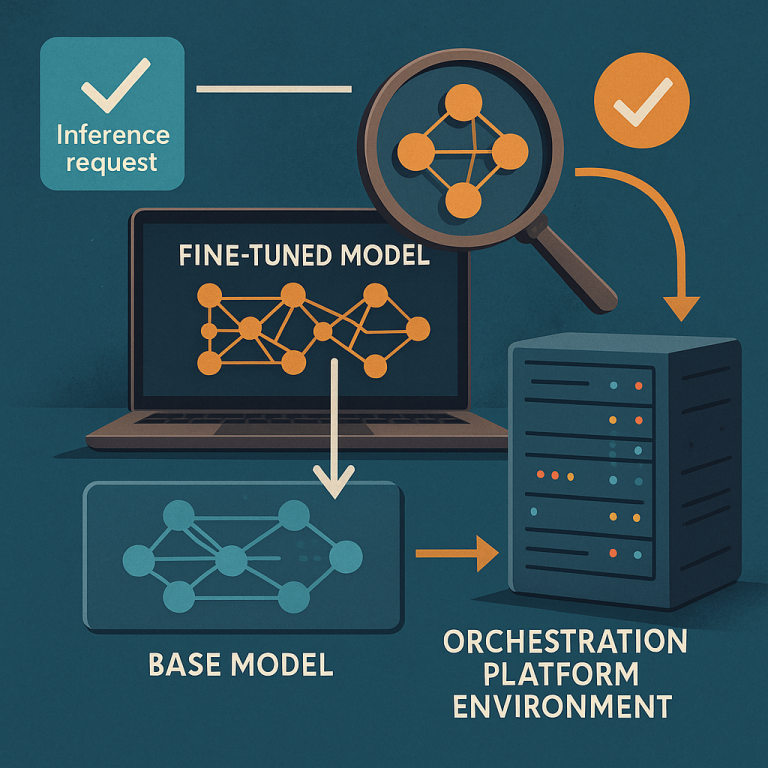
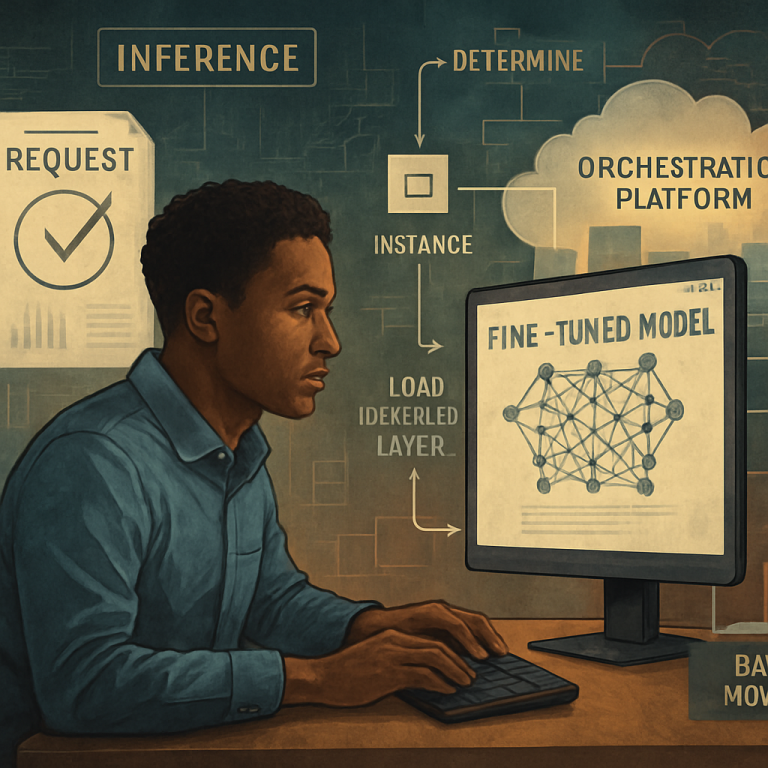
- Get a Request: When a user or an app wants to use a fine-tuned model for a job (like analyzing a photo or translating a sentence), it sends a request. This request says which “base model” to use and which “special layer” (fine-tuned for the job) is needed.
- Check What’s Running: The platform checks if a copy of the base model with the right special layer is already running somewhere. If it is, great! It sends the job there right away.
- If Not, Get the Layer: If the right version isn’t running yet, the platform quickly grabs the special layer (like LoRA) from a storage area (think of it as a digital library shelf).
- Plug In the Layer: The platform then loads this special layer into the base model, sort of like snapping a Lego piece onto a big structure.
- Set Up the Environment: To make sure everything works smoothly, the platform uses containers (like neat little boxes) to run the models. These containers have all the tools and settings needed, so the model can start working right away.
- Do the Job: Now, the platform sends the user’s data through the fine-tuned model and gets the answer or prediction needed.
- Send Back Results: The result goes back to the user or app, all done very quickly.
But there’s more! The platform is smart about memory and speed. It keeps the most-used layers in fast memory (cache), so if they’re needed again, it can grab them instantly. Less-used layers are kept in slower storage but can be fetched as needed.
This system is also very organized. Every base model and every special layer gets its own unique ID — like a library call number. This makes it easy to keep track of what’s where and what’s running.
The platform can handle lots of different fine-tuned layers for lots of different jobs, all without having to make a full copy of the big base model each time. It’s a “build once, re-use everywhere” approach.
Here’s why this matters:
- Speed: Swapping layers is fast. There’s no need to load a whole new model from scratch for every job.
- Resource Savings: Only the small, unique parts are loaded as needed. Most of the model stays in memory, ready for new jobs.
- Lower Costs: Less data is transferred, less storage is used, and less computer time is wasted.
- Easy to Manage: The system keeps track of all versions and can update them without stopping everything.
- Real-Time Ready: It’s fast enough for things like live translation, instant medical checks, or any use where waiting is not okay.
Technically, the patent covers:
- The method of receiving a task request, checking if the needed model (with the right layer) is running, and if not, fetching and plugging in the right layer.
- Storing and organizing both base models and layers with unique IDs.
- Using containers and caches (at both the host and cluster level) to speed up loading and sharing of layers.
- Managing all this through an orchestration platform that tracks what’s running and what’s needed next.
The claims also cover using this system not just for ML models, but for any software where you have a big “base” and lots of small, specialized “add-ons.”
What sets this apart is the focus on swapping just the small, unique pieces in and out of a ready-to-go base, all with smooth tracking and caching, and without ever needing to reload or duplicate the whole model. It’s like keeping one big toy, and just changing its hats instead of buying a new toy for every hat.
Conclusion
This patent is about making machine learning models much easier, faster, and cheaper to use, especially when many different versions are needed. By focusing on sharing the big, common parts and only swapping in the tiny, unique layers as needed, the system saves time, money, and computer resources.
This approach will help companies build smarter apps that respond instantly, run on small devices, and don’t cost a fortune to manage. It also makes life easier for engineers who need to juggle lots of models for different jobs. In short, it’s a smarter, cleaner, and more scalable way to serve the ever-growing world of specialized AI.
If you work with machine learning, cloud platforms, or edge devices, this is a powerful idea worth exploring. It’s a great example of how a simple change — sharing the big stuff, swapping the small stuff — can make a huge difference in real-world AI.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217193.