Invented by Meemeng; Patavee, Hacobian; Gagik, Buckhorn; Hunter

Sometimes the best ideas are also the simplest, and sometimes, they save hours of boring, repetitive work. Today, we’re going to talk about a patent application that does exactly this for the world of construction projects. If you’ve ever had to manage hundreds or even thousands of digital blueprints, you know how hard it is to keep track of all those files, their titles, and how messy things can get when people have to do everything by hand. This patent, from Procore Technologies, introduces a way to solve that problem using machine learning, and it’s worth a deep dive. Here’s what you need to know, how it works, and why it matters.
Background and Market Context
Let’s start by looking at the big picture. Construction projects are not small tasks. They involve lots of people—architects, engineers, contractors, project managers—and a mountain of paperwork. Every project needs drawings. Not just one or two, but sometimes hundreds. For example, one building with ten floors might need at least ten different floorplan drawings, and even more when you count things like plumbing, electrical, air conditioning, and so on.
Each of these drawings might be changed, updated, or corrected many times before the building is finished. Every new version is usually a new drawing file. Before long, a construction office can end up with thousands of digital drawings for just one project. If you add more buildings or bigger projects, the number just goes up and up.
Now, imagine trying to find the right drawing when you need it. Maybe you want the latest version of the electrical plan for the third floor, or you quickly need the HVAC layout for a contractor who’s on-site. Searching through all those files is tough unless each file is clearly labeled with the right title, date, and other details. That’s why most construction companies use special software to manage all these files. Companies like Procore have built tools that let you upload, organize, and search for drawings easily. The trick is that these tools work best when every drawing has the right information attached—like its title, number, version, and what part of the project it covers.
But here’s the problem: someone has to put that information in. Usually, it means a person sitting at a computer, looking at each drawing, and typing in the title, number, and other details. For a small project, that’s no big deal. For a huge project, it’s a nightmare. It’s boring, slow, and mistakes happen. People might type the wrong title, misspell something, or put the wrong date. Even worse, different drawings might use different layouts. Sometimes the title is at the bottom, sometimes on the right, sometimes in a special box, sometimes just floating in the drawing. Rules-based software tries to help, but it’s not smart enough to handle all the different ways people make drawings.
To fix this, some tools started using OCR (Optical Character Recognition), which is just a fancy way of saying the computer looks at the drawing and tries to read the words. But OCR on its own still needs rules to know where to look for the title. These rules might say “look in the box at the bottom right,” or “search for big, bold letters.” But what if the drawing doesn’t use that layout? Or what if the box is missing? The computer gets confused, and the person still has to double-check everything.
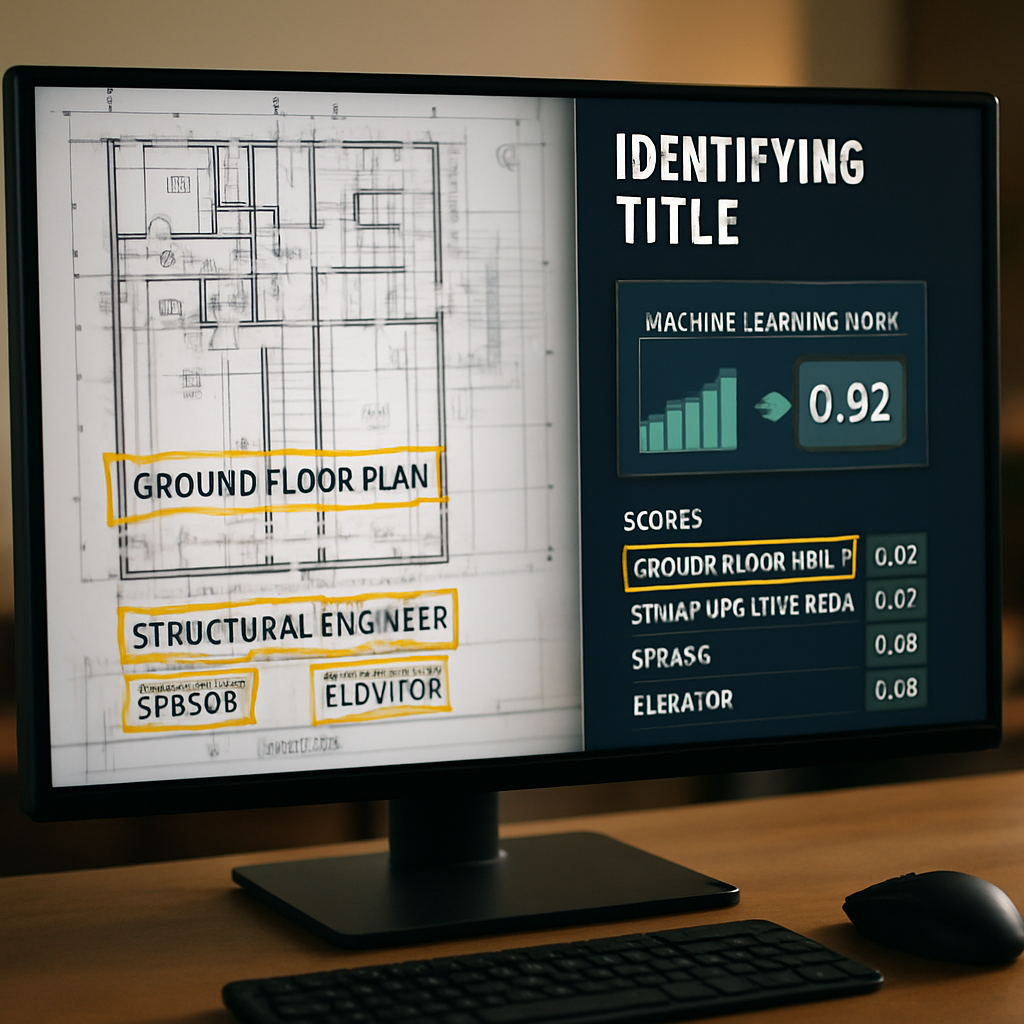
That’s where this patent comes in. It describes a way to use machine learning—a kind of computer intelligence that learns from examples—to look at any drawing and decide, with a high level of confidence, what the title is, no matter where it is or how it’s written. This means less manual work, fewer mistakes, and faster project management. It’s a clear answer to a real market need: making the lives of construction professionals easier and making sure information is always accurate and up to date.
Scientific Rationale and Prior Art
Understanding why this patent is special means looking at what came before and why those older methods just aren’t good enough. At the heart of the problem is the variety and messiness of real-world construction drawings. There is no single, standard way to make a drawing. Different companies, even different teams within the same company, might use their own styles and templates. Titles can sit in a box, run along the bottom, hide on the right edge, or even float in the middle. Sometimes they’re big and bold, sometimes small and plain. Some titles are in all caps, others are mixed case. Even the words used in titles can be different—“First Floor Plan,” “Plan View – Level 1,” “Building Layout,” and so on.
The first attempt at solving this problem was simple rules. These rules say things like, “the title is always in the biggest font,” or, “look for the box at the bottom right.” But as soon as you run into a drawing that doesn’t follow those rules, the system fails. The software might pick the wrong text, or skip the title altogether. If there are two boxes with text, or if the words “Title” or “Name” appear near the real title, things get mixed up. Sometimes, even the order of operations—like whether you search boxes first or edges first—can miss the title or pick up duplicates.
OCR came next, and it improved things a little. Now, computers could at least read any text on the drawing, not just what was typed in a digital file. But OCR by itself doesn’t know which text is the real title. It just gives you a list of words and their locations. You still need rules to decide which one is the title. This is where the limitations really show up: OCR plus rules can’t handle the huge variety of layouts, fonts, and odd cases found in real construction documents.
Some systems tried to get smarter by using lists of “blacklisted” words (words that should not be in a title, like “Drawing,” “Schematic,” or “Name”) and “whitelisted” words (words that are likely to be part of a title, like “Plan,” “Section,” or “Elevation”). But even this is not perfect. Sometimes, the title might include a blacklisted word, or a whitelisted word might appear in other text nearby. The result? More errors, more manual checking, and more wasted time.
Enter machine learning. The idea here is simple but powerful. Instead of trying to write rules for every possible case, you show the computer lots of examples of real drawings, tell it where the titles are, and let it learn the patterns. The computer looks at all sorts of clues: where the text sits on the page, how big it is, if it’s in a box, what words it uses, if it’s all caps, if there are numbers, and what other text is nearby. Over time, the computer builds a model—a kind of map in its “memory”—of what usually makes a text the title in a drawing.
This approach is much more flexible. Machine learning models can look at lots of clues all at once. They can spot patterns that humans or simple rules would miss. And because they learn from many examples, they get better the more they’re used. If a new kind of drawing comes along, you can show the model some new examples, and it will update itself.
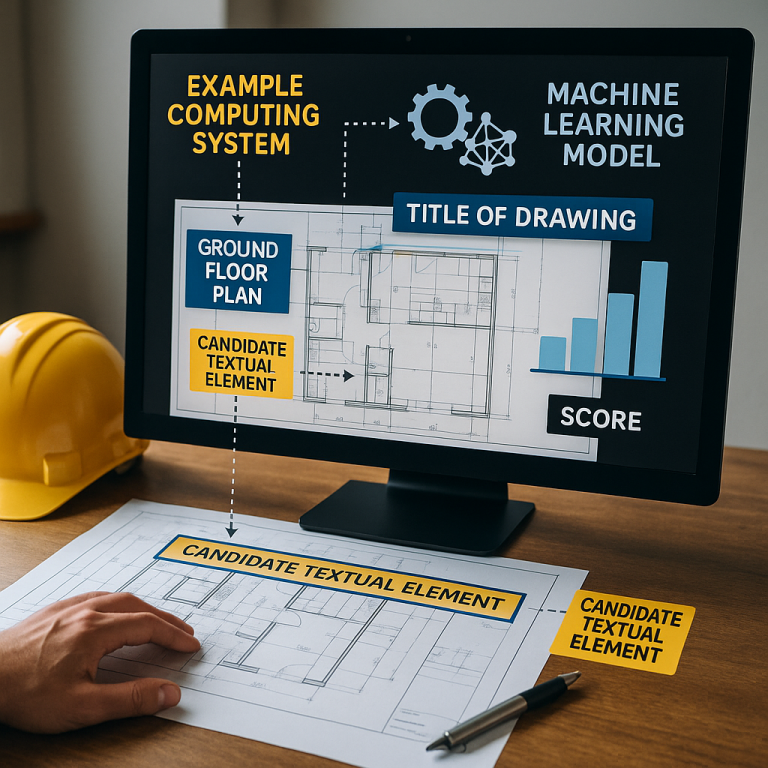
Before this patent, systems did not combine all these clues—spatial details (where the text is), linguistic clues (what the words are), and surrounding context (what’s nearby)—and run them through a trained machine learning model to pick out the title with a confidence score. That’s the core difference. This patent steps beyond rules and static OCR, and brings in a smart, teachable system that can keep learning and adapting. It’s a leap forward in making drawing management truly automatic, accurate, and scalable.
Invention Description and Key Innovations
Now it’s time to really dig into what this patent claims, how it works, and what makes it special. The invention is all about a computing system—a software tool that can run on any modern computer or cloud platform. Let’s break it down in simple terms.
First, the system gets a digital drawing. It could be a PDF, an image file, or any other kind of electronic drawing. The drawing is part of a construction project, but the same ideas could be used for other fields too.
The system looks at the drawing and tries to find the regions where the title is likely to be. There are three main types of regions it checks:
- Boxes: Areas on the drawing that are surrounded by a box (often called the title block). These are very common in technical drawings.
- Bottom Edge: A strip along the bottom of the drawing, up to a certain height (often 30% of the drawing’s height).
- Right Edge: A strip along the right side of the drawing, up to a certain width (again, often 30% of the drawing’s width).
The system can use computer vision tools to find the boxes. It looks for rectangles, using shape detection algorithms. Then, it uses OCR to read all the text inside those boxes. Next, it looks at the bottom and right edge regions, again using OCR to read any text there. If the box regions and edge regions overlap, the system can mask (hide) the boxes while reading the edge regions, so it doesn’t pick up the same text twice.
After all this, the system has a list of “candidate textual elements”—bits of text that might be the title. But which one is it? Here’s where the machine learning comes in.
For each candidate, the system gathers a bunch of information:
- Spatial details: Where is the text? How far is it from the edge? Is it in a box? How big is it? What direction is it written (horizontal or vertical)?
- Linguistic details: What words are in the text? Are any of them from a list of good or bad words for titles? Is it capitalized? Are there numbers?
- Context: What other text is near this text? Are any nearby words whitelisted or blacklisted? Is the text alone or in a group?
All these clues are packed into a data “vector”—just a list of numbers and codes that describe each candidate. The system then feeds each vector into a machine learning model. This model has already been trained by looking at lots of real drawings and learning what makes a text likely to be the title.
The model looks at the clues for each candidate and gives it a score—a number that says how likely it is to be the real title. The system then picks the candidate with the highest score and saves this as the drawing’s title. If the model isn’t very sure (for example, if the top score is low), the system can ask a human to double-check.
The best part? This system isn’t locked into one way of doing things. If your company uses a new drawing template, or if you have special rules, you can just give the model more examples, and it will learn the new patterns. The more it’s used, the smarter it gets.
What’s also clever is how the system is careful with computational resources. By only running OCR on the most likely regions (the boxes and edges), it saves time and computer power. It doesn’t waste effort scanning the whole drawing, which is especially important for big projects with thousands of files.
This approach also means fewer mistakes. By combining many types of clues—where the text is, what it says, and what’s around it—the system can handle the messiness and variety of real-world drawings. It’s not fooled by odd layouts, strange fonts, or unexpected titles. And because it gives a confidence score, users know when to trust the result and when to double-check.
Other smart features include:
- Flexible region selection: The system can change the size of the edge regions depending on what’s most common in your drawings.
- Human feedback: If the system isn’t sure, it can ask for help and use that answer to get smarter in the future.
- Easy integration: The invention works with cloud platforms, client computers, and all the usual tools found in modern construction offices.
In essence, this patent is about making drawing management truly hands-off and reliable. It takes a real-world problem—finding and labeling the titles of construction drawings—and solves it not by adding more rules, but by making the computer smart enough to learn from real examples. It’s a practical, scalable, and future-proof answer for any company that deals with lots of digital drawings.
Conclusion
This patent application shows a clear path forward for the construction industry and any field that deals with lots of technical drawings. By using a mix of computer vision, OCR, and machine learning, the system makes the difficult task of finding and labeling drawing titles automatic, fast, and accurate. It learns from real examples, adapts to new layouts, and reduces human errors and boring manual work.
In a world where every hour saved counts, and where accurate information can mean the difference between a smooth project and a costly mistake, this invention is a big step forward. If you manage construction projects, work in architecture or engineering, or just want to see how smart software can make life easier, this patent shows what’s possible when technology is used in the right way.
As machine learning becomes more common in day-to-day business, inventions like this one will set the standard. They show that with the right approach, computers can take over the dull, repetitive jobs and let people focus on what really matters: building, creating, and managing with confidence.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218208.