
Invented by BHUSHAN; Devin, HAN; Seunghee, JACKSON-KING; Caelin Thomas, KUPPEL; Jamie, YAZHENSKIKH; Stanislav, ZHU; Jim Jiaming
The way we interact with the real world and digital data is changing quickly. Extended Reality (XR), which includes augmented reality (AR) and virtual reality (VR), lets us see digital information over real objects. But there’s a big problem: how do you connect digital data to real-world objects, especially if you can’t stick a QR code or barcode on everything? A new patent application for “Codeless Anchor Generation for Three-Dimensional Object Models” offers a powerful answer. Here, we’ll break down what this means, why it matters, and how it works—so you can see why this could change how we track and understand the world around us.
Background and Market Context
Imagine walking into a server room or a warehouse. You want to know more about a machine, a box, or a piece of equipment. In the past, you’d have to find a label or scan a barcode. But sometimes those labels get lost, worn out, or are hidden behind something else. You could spend a lot of time searching for the right tag, and even then, it might not work. This is a real problem in places like factories, hospitals, or even retail stores.
Now, companies use XR devices—like AR glasses, tablets, or phones—to make work faster and more accurate. When you point an XR device at something, it can show you extra information, help you fix problems, or guide you step by step. But this only works if the device knows exactly what you’re looking at. Usually, that means scanning a code stuck to the object. If the code is missing, you’re out of luck.
There is a big push in the market to solve this identification problem. XR technology is being used more every year, not just for gaming or entertainment, but for serious jobs. Maintenance workers, doctors, warehouse staff, and even shoppers all want to get information fast, without hunting for a sticker. The need for “codeless” ways to anchor data to real objects is growing. This is especially true in settings where labels are impractical, like on moving equipment, objects that get dirty, or items that change location often.
This new patent tackles a simple but huge problem: how can we identify real-world assets and show the right data in XR, even if there is no readable label? The answer is to use the shape and look of the object itself—its 3D model and surface appearance—to create a digital “anchor.” This anchor links the real object to its information in the digital world, without the need for a code or tag. In other words, your XR device learns what objects look like, and then can recognize them just by “seeing” them.
With this codeless anchor system, workers can save time, reduce mistakes, and get the right information right when they need it. This is a big leap for industries that depend on fast, reliable identification of physical assets, and opens the door to new XR experiences everywhere from the factory floor to the hospital ward.

Scientific Rationale and Prior Art
Before this invention, the most common way to connect digital data to a real-world object was to use a physical marker—a QR code, barcode, or special label. XR devices would “see” the code through a camera, decode it, and then pull up the right information. This works well—until the code gets dirty, falls off, or is hidden. If a label is missing or unreadable, the system fails. This is a big problem for any place with lots of equipment, fast turnover, or tough working conditions.
Some older solutions tried to use object recognition based on 2D images (pictures) alone. That means taking a photo of the object and trying to match it to a database. But this has limits. Lighting changes, object rotation, background clutter, and similar-looking objects can all confuse simple image matching. Plus, a 2D picture does not capture the full shape of a real object.
Other systems tried to use radio tags (like RFID), but that requires every object to have a special chip or sticker, which adds cost and can still get lost.
Some more advanced systems used 3D scanning, but only for creating models, not for object recognition in the field. And even when 3D models were used, there was no easy way to “anchor” live data to the shape and appearance of the object itself. Most XR systems still needed a code or some manual linking.
The scientific leap here is to combine 3D scanning (using a camera and depth sensor, like LiDAR) with texture mapping (the color and surface details), and to use this combined data to create a unique digital anchor for each object. This anchor is stored and can later be matched by comparing live camera and sensor data to the stored anchor. The matching process uses the object’s shape (from the mesh) and its surface details (from the texture) to make identification much more reliable and robust, even if lighting, angle, or other conditions change.
Another important step is to make this whole process “codeless”—no physical marker or code is required. The system can generate anchors automatically (“codeless anchor generation”) as part of regular scanning, and can do this without special programming or coding skills. This is a big improvement over older systems, which often needed manual setup, code generation, or hand-tuned matching.
Compared to previous approaches, this invention is both more reliable (because it uses both shape and appearance), more flexible (because it needs no codes or stickers), and easier to use (because anchors can be created and recognized automatically, even in tough environments). It also adds strong privacy features, like encrypting reference images when sending them over the network, and supports secure, cloud-based storage and retrieval.
Invention Description and Key Innovations
Let’s go step by step through how this invention works, in the simplest possible terms.
First, the system uses an XR device—a tablet, phone, AR glasses, or headset equipped with a camera and a depth sensor (like LiDAR). When you scan an environment, the device captures both a flat image (what you see) and a map of how far away each part of the scene is (the depth map).
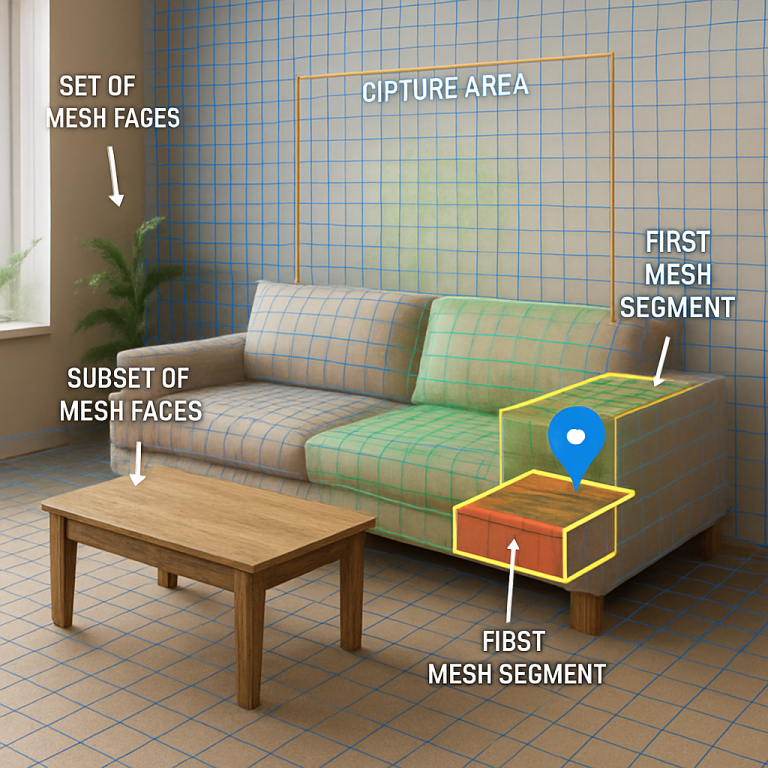
Using this data, the device builds a “mesh”—a digital version of the surfaces in front of you, made up of lots of little flat pieces called mesh faces. Each mesh face covers a small part of the surface of a real object. The system identifies these mesh faces and figures out where they are in space.
Next, the user (or the system) picks a “capture area” in the scene. This is usually a box or region around the object of interest. The system then looks at all the mesh faces that fall inside this capture area.
For each mesh face in the capture area, the system checks its angle and position. It looks for mesh faces that are pointed toward the camera (not too slanted) and close to the surface of a real object. It groups together mesh faces that are next to each other and have similar angles, forming a larger “mesh segment” that represents a part of the real object’s surface.
The system then draws a boundary around this mesh segment and finds the biggest rectangle that fits inside it. It extracts the texture (the color and surface detail) from the image within that rectangle. This gives a unique “fingerprint” for that part of the object, combining both its shape and its appearance.
This combination of the mesh segment and texture image becomes the object’s digital anchor. The anchor can be stored locally or sent to a server. If the anchor is too large to send directly (say, over a slow network), the system can encrypt it, upload it to a cloud server, and just send a link and an encryption key to the main database. This keeps data safe and efficient.
The anchor is then linked to “asset content”—the digital information you want to show when this object is recognized. This could be a dashboard, a manual, maintenance logs, live sensor data, or anything else. The link is stored in a database so that, when the object is recognized later, the right information pops up in the XR display.
When you come back later, or when another user points their XR device at the object, the system repeats the scanning process. It captures a new image and depth map, builds mesh faces, extracts mesh segments, and compares the new data to the stored anchors. If there’s a match, the system knows what object you’re looking at, and shows the linked asset content right on the XR display, at the right place and orientation.
Importantly, this process works even if the object has no code, no label, and even if its surroundings have changed. The system relies on the object’s own shape and look, not on any added marker.
Some key innovations in this system include:
– Automatic anchor generation: The system can create anchors from regular scanning, without special markers or codes, and without needing a software developer to write custom code.
– Robust matching: By using both 3D shape and 2D texture, the system can reliably recognize objects from different angles, under different lighting, and even if the background changes.
– Secure, scalable storage: Anchors can be encrypted and stored in the cloud, making it easy to share anchors across devices, users, and locations, while keeping sensitive information protected.
– Flexible linking: Anchors can be linked to any kind of asset content, so the system can support many different use cases—from maintenance and repair, to inventory tracking, to education and training.
– Geolocation support: The system can use GPS, Wi-Fi, beacons, or geofences to narrow down which anchors to look for, making matching faster and more accurate, especially in large spaces with many similar objects.
– User-friendly workflow: The system includes clear XR interfaces for scanning, reviewing, and saving anchors, so non-technical users can set up and use the system with minimal training.
Overall, this invention replaces the need for physical markers with a digital process that is more reliable, more flexible, and easier to use—pushing XR technology into new areas of work and daily life.
Conclusion
The move from code-based to codeless anchor generation in XR is a big step forward for how we connect the physical and digital worlds. By using the object’s own shape and appearance, this system lets us identify, track, and interact with real-world assets without needing labels or codes. That means faster work, fewer errors, and new chances for XR everywhere from the warehouse to the hospital to the shop floor.
This patent application shows that the future of XR is about making technology work with the world as it is—not as we have to label it. If you want to unlock the full potential of XR in your business or industry, codeless anchor generation may be the key. The ability to recognize and link data to any object, anywhere, without special codes or stickers, is not just a technical breakthrough—it’s a new way to see, understand, and work with the world around us.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218142.