Invented by Austraat; Bjorn, Truist Bank
Today, most of us have talked to a robot on the phone. Sometimes, it helps, but many times, it feels cold or just plain wrong. Wouldn’t it be better if the computer sounded more like a real person, understood how you felt, and even adjusted itself to help you better? That is the promise of the new patent application for adaptive, individualized, and contextualized text-to-speech (TTS) systems. This article will help you understand why this invention matters, how it fits into the world today, what makes it different from older systems, and how it actually works.
Background and Market Context
Let’s start with why this invention is so important. In our world, we use machines to talk to us everywhere. Banks, stores, health care, customer service, smart speakers, and even our cars use computers that talk. When you call your bank, you might hear a robotic voice asking for your account number. When you ask your smart speaker to turn on music, it answers back. These voices are powered by text-to-speech (TTS) technology, which turns computer text into spoken words.
But there is a big problem. The voices often sound fake. They don’t understand if you are angry, happy, or confused. If you talk to them in a way they don’t expect (like using slang, jokes, or sarcasm), they might not get what you mean. Sometimes, they can’t even tell if you are upset or joking. This can make people feel annoyed or misunderstood. Many companies know that when customers are happy, they stay loyal, but when they feel ignored or frustrated by a robot, they might leave.
Today, businesses spend a lot of money trying to make their customer service better. Many use TTS and chatbots to save costs and let people get help 24/7. But if these systems make people angry, the company loses trust. With the rise of smart devices—phones, watches, speakers, and even fridges—there are more chances for people to “talk” to technology. The demand for TTS that feels human is higher than ever.
This is why adaptive, individualized, and contextualized TTS is so important. Imagine if the voice you heard could change based on how you were feeling, what you were asking, and even how you usually talk. If you are upset, it could sound caring. If you are joking, it could laugh with you. If you have an accent, it could match it. This isn’t just about sounding nice; it makes people feel understood. That builds trust and keeps customers coming back.
Companies that can make their TTS systems more human will win more customers and save on the cost of hiring extra staff. They will also collect better feedback, learn from every call, and keep improving. In a world where everyone wants quick, easy, and personal service, this kind of smart TTS is not just a nice-to-have—it is the next step.
Scientific Rationale and Prior Art
To understand what makes this invention special, let’s look at what came before. Early TTS systems were simple. They turned written words into speech using pre-recorded chunks or by stringing together simple sounds. These voices were flat and robotic. Later, TTS got better with digital signal processing and more natural recordings, but still, it was mostly reading words aloud.
Then came natural language processing (NLP), which helped machines understand what people were saying. With NLP, TTS systems could do a bit more, like stressing the right word in a sentence or using the right tone for a question. Some could even guess if you were angry or happy, but they were not very accurate and didn’t keep learning over time.
Most older systems followed rules set by programmers. If a sentence ended with a question mark, the voice would go up at the end. If it saw the word “sorry,” it might sound a little softer. But these rules were basic. They didn’t truly understand context, like if you were making a joke, being sarcastic, or had a unique way of speaking. They also treated every user the same, never learning from past conversations or adjusting to your mood.
Some newer systems use machine learning. They are trained on lots of data to get better at understanding language and emotions. However, most of these systems still lack real-time feedback. They don’t measure how you react to their speech and adjust on the fly. If they make a mistake, they don’t learn from it right away. They also don’t always use information stored in a user profile—like your past conversations and what worked best for you before.
Current TTS systems are also limited in how they control “prosody”—the rhythm, pitch, and tone of speech. They might sound more natural than before, but they don’t truly adapt the voice to match a person’s needs, context, or emotions. For example, if you call when you are upset, the voice might still sound cheerful or flat, making things worse.
The scientific leap with this new invention is combining deep learning (using neural networks), real-time feedback, and user profiles to create a TTS system that constantly adapts. It doesn’t just read the words—it understands the intent, the context, your mood, and your history. It learns from every interaction and tries to make the next one better.
This moves beyond simple rules or even basic machine learning. The system can measure how you respond, rate itself, and use that quality score to change how it speaks to you the next time. It uses advanced NLP to break down your speech into parts like intent, emotion, context, and even circumstantial factors like background noise or urgency. It then chooses not only the words, but also the voice style—like timbre, pitch, and speed—that it predicts will help you most.
No older system fully combines all these elements: deep neural networks, real-time adaptation, individualized profiles, emotion/context detection, and self-improvement based on feedback. That is the breakthrough.
Invention Description and Key Innovations
Now let’s explore how this invention actually works and what makes it stand out.
At its core, the invention is a smart computer system that uses memory, processors, and special program instructions. It is built to handle real-time conversations with users, such as through a phone call or smart device. Here’s what it does, step by step:
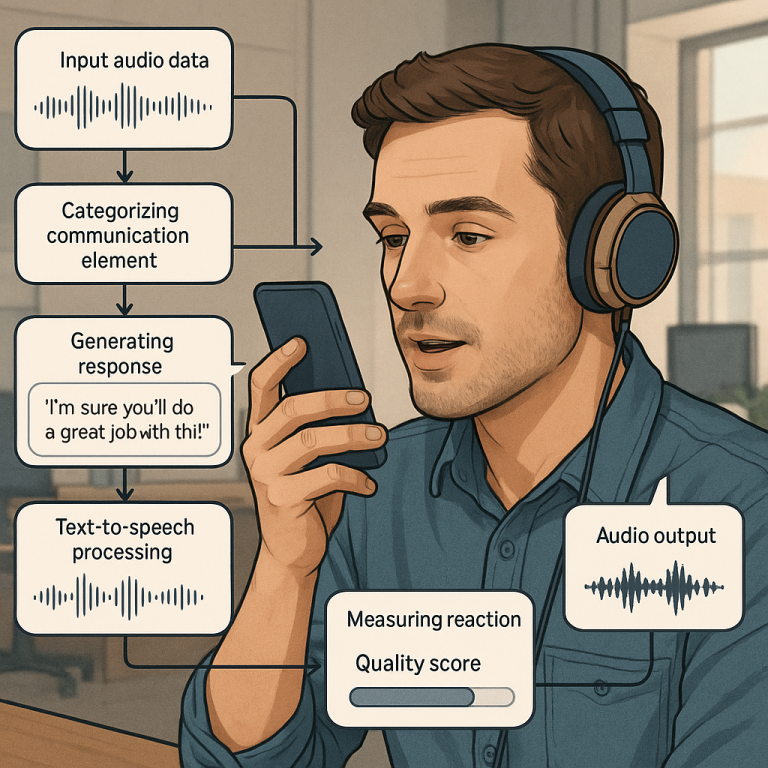
First, the system uses “neural networks”—special computer models inspired by the human brain. These networks are trained on lots of real-world data, including recordings of people talking, customer service calls, and user feedback. During training, the system learns to spot important parts of speech, such as intent (what you want), emotion (how you feel), and context (what’s going on).
Training is not a one-time process. The system keeps running through loops of training and testing, adjusting its settings (called “weights”) to get better at predicting what’s really happening in each conversation. Every time it makes a guess, it checks itself and updates its knowledge if it was wrong. This makes the system smarter over time.
Once trained, the system listens to your input—like your voice during a call. It breaks down what you say into different “communication elements,” including your intent, emotional state, and even things like if you pause or speak quickly. It puts these elements into “contextual categories,” such as “making a complaint,” “asking a question,” or “joking.”
Using what it knows about you (from past calls or a user profile), it generates a response. But it does more than just pick the right words. It chooses how to say them. It selects a speech pattern that it predicts will make you feel better or lead to the best outcome—maybe softer and caring if you’re upset, energetic if you sound excited, or matching your regional accent if it knows where you’re from.
This is where “prosody” comes in. Prosody is all about the music of speech: pitch, speed, loudness, and especially timbre (the unique color or quality of a voice). The system can change these aspects on the fly, using what it learned from you and from others like you. For example, if you have always responded well to a warm, gentle voice in past calls, it will use that style again.
The system also measures your reaction. Did you calm down? Did you sound happier? It uses these reactions to create a “quality score.” If the score is high, it knows it did a good job. If not, it learns and changes its approach for next time. This feedback loop is unique because it means the system keeps getting better every time it interacts with you or anyone else.
Here are a few more details that show the system’s power:
– It can handle multiple speech “utterances” in a single conversation, adapting after each one.
– It detects pauses, so it knows when you are done talking or just thinking.
– It stores all interactions in your profile, including feedback from you or from human agents, to improve future conversations.
– It can adjust not just for emotion, but also for things like regional dialect, urgency, or even if there is background noise.
– It supports many prosody elements, like tone, cadence, pitch, volume, pronunciation, speed, and more.
– It uses speech synthesis markup language (SSML) tags to fine-tune speech patterns for the best effect.
If you use a device that is not part of the main system (like your phone or a smart speaker), the system can still send the audio output to you. It even works across phone lines, the internet, or radio waves.
During every conversation, the system keeps learning. If you provide feedback—like saying you were happy with the help, or a human agent adds notes—the system saves that and uses it to make your future experiences better.
The true magic is in how all these parts work together. The system is always listening, learning, measuring, and adapting. It does not treat everyone the same. It does not use a fixed set of rules. It is always trying to sound more human, be more helpful, and leave you feeling understood.
For businesses, this means happier customers, better feedback, and fewer mistakes. For users, it means you get help that feels personal, even from a machine. For the future of TTS, it means moving closer to conversations that feel real, natural, and satisfying.
Conclusion
The adaptive, individualized, and contextualized text-to-speech system described in this patent is a big leap forward for voice technology. By using neural networks, real-time feedback, user profiles, and deep understanding of language and emotion, it creates a TTS experience that is truly personal and always improving. It solves the biggest problems with old systems—robotic voices, lack of empathy, and one-size-fits-all answers. Instead, it brings us closer to a world where talking to a machine feels as natural as talking to a person. For companies, it means happier customers and smarter service. For all of us, it means a future where technology listens, learns, and truly understands.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218422.