Invented by Stephens; Donpaul C.
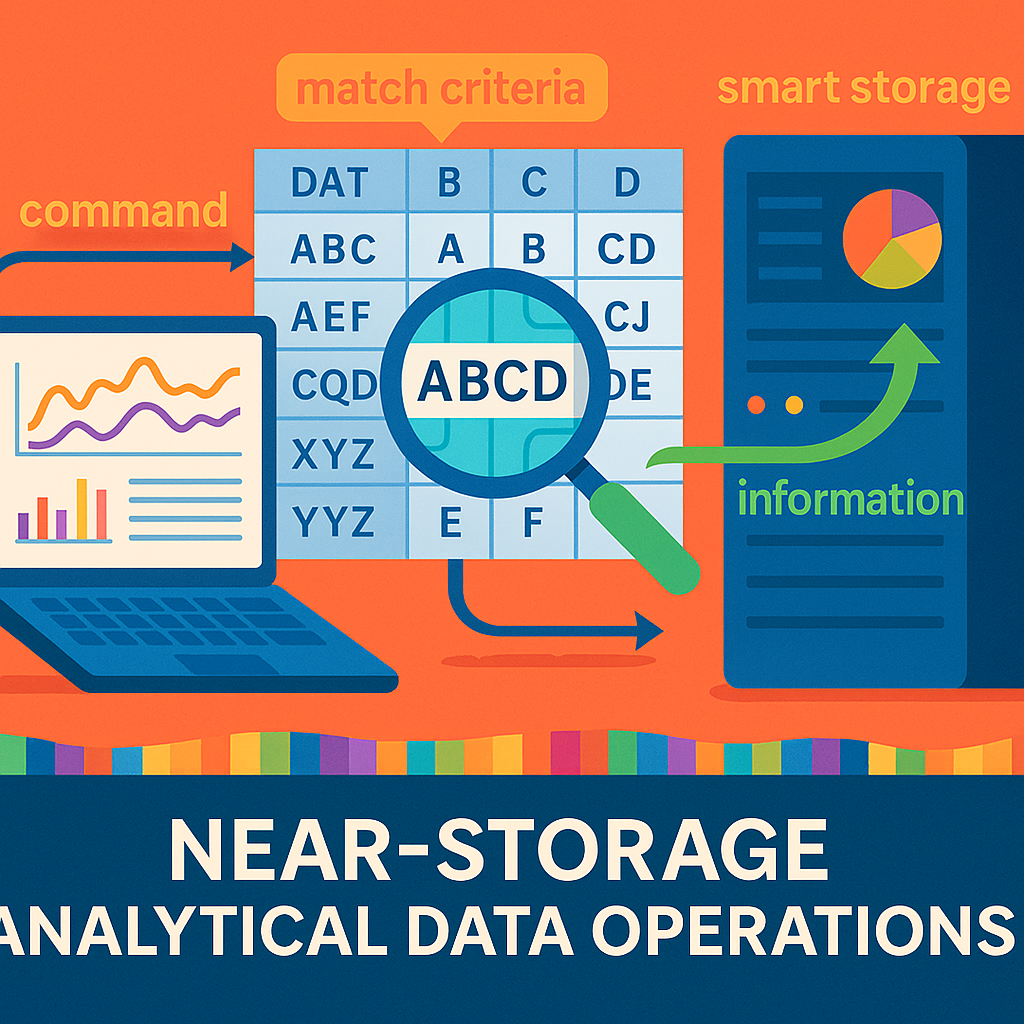
Understanding how to work with large sets of data quickly and efficiently is a challenge for businesses, researchers, and anyone who needs answers fast. The patent application we are exploring today introduces new techniques for running data operations closer to where the data actually lives, inside storage devices themselves. This approach is called “near-storage” or “near-memory” analytics. Let’s break down what this means, why it matters, and what makes this new method special.
Background and Market Context
Every day, companies and organizations gather and store huge amounts of data. Think about banks processing transactions, websites keeping track of users, or scientists collecting climate data. All this information is stored on devices like hard drives or solid-state drives (SSDs). When someone wants to analyze or search this data, a computer has to ask the storage device for the data, then process it, and finally give you the answer. This back-and-forth can take a lot of time, especially as data grows.
The need to make this process faster and smoother has led to the idea of “near-storage” or “near-memory” computing. In this approach, analytical tasks—the work of searching, counting, or filtering data—are performed directly on the storage device, so only the final answer or a small piece of information needs to be sent back to the computer. This saves time, cuts down the amount of data that needs to move across networks, and reduces the load on both the storage and the computer.
Several industries are pushing for better and more flexible ways to analyze data right where it is stored. Financial services want to spot fraud in real time. Cloud service providers need to support many users running complex searches at once. Scientific research groups must sift through large datasets for patterns or anomalies. For all these groups, getting quick answers without moving gigabytes or terabytes of data is a big win.
However, previous attempts to build these kinds of storage systems have run into problems. Adding powerful analytics inside storage devices makes them more complex to design, harder to program, and often more expensive. The tools and commands needed for these systems can also be confusing for the people who need to use them. Sometimes, changes in the way data is stored mean both the storage device and the computer have to be updated together, which is hard to manage. These issues have slowed down the adoption of near-storage analytics, even though the benefits are clear.
The patent application we are reviewing introduces a way to perform these analytical tasks with less complexity and easier programming. It aims to make it much simpler to identify, filter, and process data directly on the storage device, then provide just the key results to the host computer. This can save time, bandwidth, and resources, making it an appealing solution for a wide range of markets.
Scientific Rationale and Prior Art
Let’s look at why this new approach is needed and how it builds on earlier ideas in storage and analytics.
Traditionally, storage devices acted as simple vaults. They would store data and, when asked, hand it over to the computer. All the “thinking” — searching, filtering, or counting — happened on the computer’s main processor (CPU). As the size of stored data exploded, this model started to show its limitations. Moving all that data from storage to CPU just to filter or count it became slow and expensive.
Over the years, engineers have tried to move some of the analytics work closer to where the data lives. This is known as computational storage or near-data processing. Some newer storage devices, like those used in big data centers, include their own processors or even dedicated chips (ASICs or FPGAs) that can run small programs. These programs can search, filter, or even do simple math directly on the storage device, reducing the need to move data back and forth.
But these solutions have their own challenges. They often require special hardware, custom software, or new ways for computers to talk to storage devices. Sometimes, the commands or queries used to control these analytics are hard to understand or use, especially for people who are not storage experts. Also, if the format of the data changes, both the storage device and the computer have to be updated to keep working together. This makes it harder to manage and upgrade systems.
A key part of analytical work is searching for patterns or matches in large tables of data. For example, finding all the records where a customer’s name matches a certain value, or counting how many unique users have visited a website. Existing solutions can do these tasks, but they may require the entire data table to be moved to the host computer, or they might only work with certain data types or storage formats.
Prior art in this space includes:
– Early computational storage devices that could run simple scripts or filters on data.
– Database systems that push some query logic closer to the data, but usually inside the database software, not on the storage hardware itself.
– Analytics frameworks that use in-memory processing to speed up queries, but require all the data to be loaded into RAM, which is not always possible with very large datasets.
None of these earlier approaches strike a good balance between flexibility, ease of use, and low complexity. They often require users to learn new programming languages, deal with complex data formats, or accept strict limits on what types of analyses can be run.
The patent application at hand offers a simpler, more flexible way for computers to ask storage devices to find, count, or filter data. It uses well-defined commands, supports both “flat” and “multi-dimensional” data layouts, and can process common data types like strings or numbers. By using clever techniques, like sliding windows for string matching and register arrays for uniqueness counting (using algorithms like HyperLogLog), it supports powerful analytics without the need for complex software or hardware upgrades.
The approach described also pays attention to practical realities: it works with common file formats (like CSV or JSON), supports both sparse and dense datasets, and allows for easy updates if data formats change. By keeping the interactions between the host computer and the storage device simple and clear, it avoids the “layer violations” that have made previous solutions hard to manage.
Invention Description and Key Innovations
Now, let’s explore what this patent application actually claims, how it works, and what makes it stand out.
At its heart, the invention covers a method for running analytical operations—like searching for a string, counting matches, or estimating unique values—directly inside a storage device. It covers methods, systems, and software products that allow a host computer to send special commands to a storage device, telling it exactly what to search for and where, and then getting back just the information that matters.
The process works like this:
1. The host computer sends a command to the storage device. This command says what to look for (for example, a certain word or number) and where to look (a specific range in a data table).
2. The storage device uses its own processing power to search the data table. It uses a “sliding window” technique to check each part of the table for matches with the target string or value.
3. When matches are found, the storage device marks their locations, often using a “bitmap” (a simple map of which positions matched).
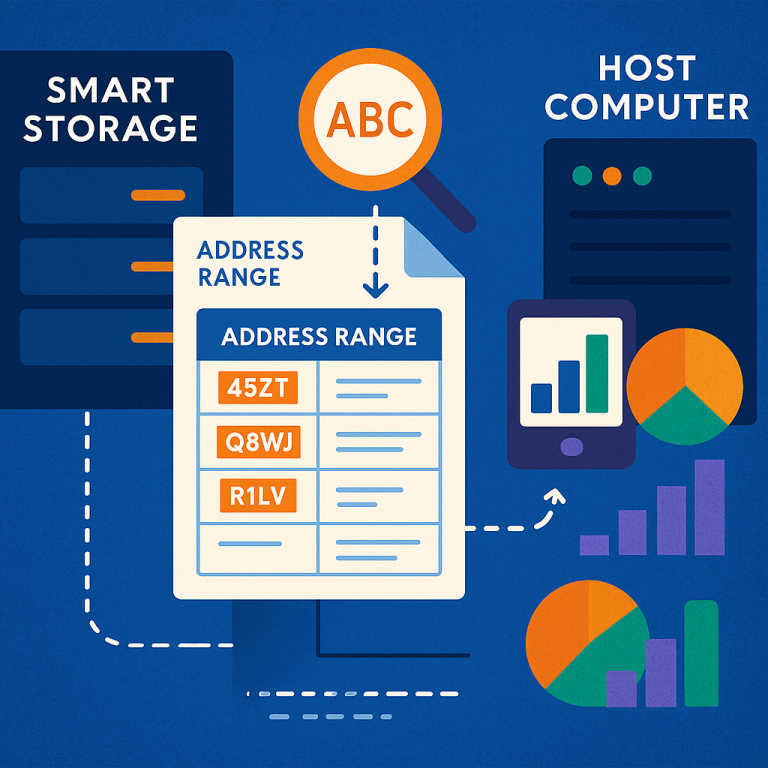
4. The storage device sends back this bitmap, or just a count of matches, to the host computer. This way, the host does not need to see all the data—only the important results.
5. If needed, the host computer can send a second command to fetch the actual matching data, or to get extra details like arrays of register values or estimates of how many unique items are present (using cardinality estimation methods like HyperLogLog).
Let’s break down some of the key innovations and features:
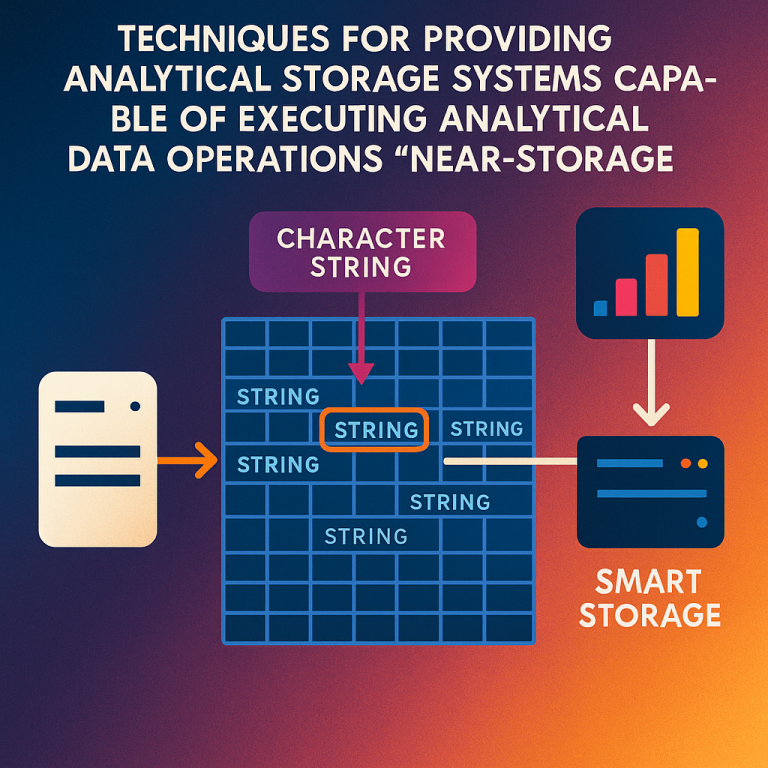
1. Sliding Window String Matching:
The device uses a “sliding window” to check for matches. Imagine you’re looking for the word “apple” in a long text. You slide a small window, letter by letter, along the text and check if each chunk matches “apple.” This is done byte by byte, which works well for plain text or structured files. The process can handle both simple (one-byte) and more complex (multi-byte) data.
2. Bitwise Masking and Marking:
To mark where matches are found, the device uses “bitwise masking.” This means it sets certain bits (the smallest piece of information in a computer) to signal where a match happened. This makes it very fast and efficient, and the result (a bitmap) is much smaller than the original data.
3. Flexible Data Formats:
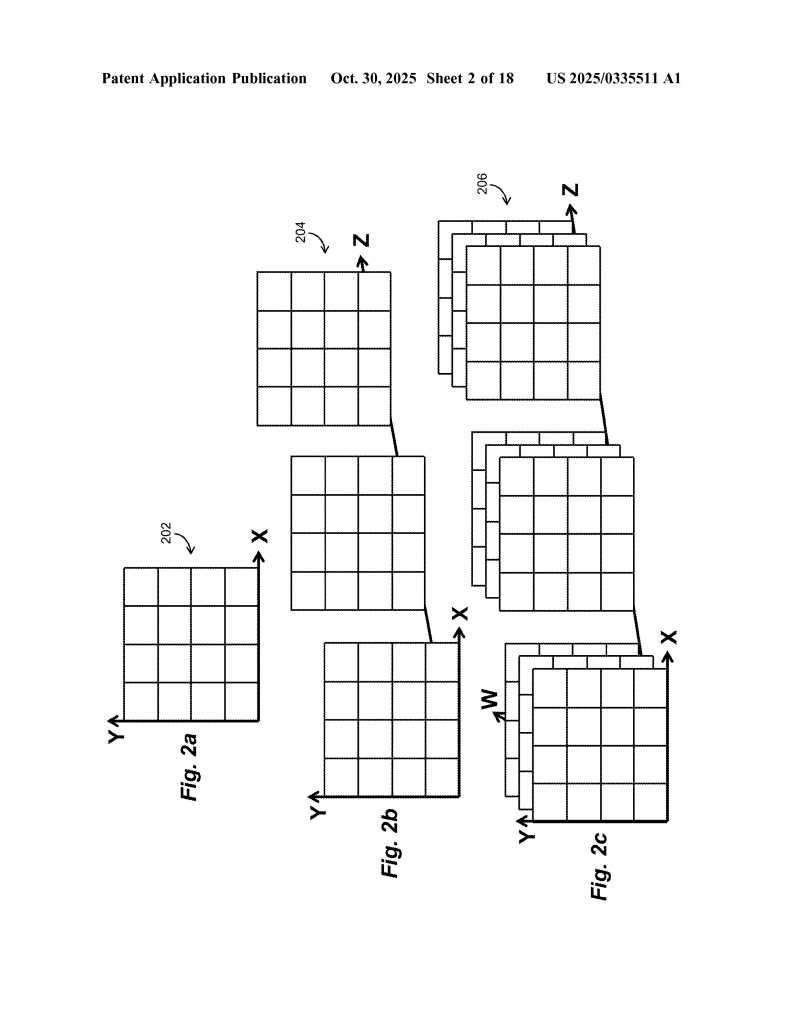
The approach works with common formats like CSV, JSON, and XML, and supports both “flat” (2D tables) and multi-dimensional arrays. It can handle both column-oriented data (like Parquet files, popular in big data) and more traditional row-oriented data.
4. Uniqueness Counting with HyperLogLog:
To estimate how many unique items are in a dataset (for example, how many different users visited a website), the device can use the HyperLogLog algorithm. This is a clever, space-efficient way to guess the number of distinct items without looking at every single one. The device hashes each value, puts it into a “bucket,” and keeps track of the maximum number of leading zeros. Then, it calculates an estimate using the harmonic mean of all the buckets. This is especially useful for very large datasets where counting each unique value would be too slow or require too much memory.
5. Pre-processing and Case Folding:
Before sending results back, the device can do extra processing. For example, it can change all letters to lowercase (so “Apple” and “apple” are treated the same), convert numbers to more compact binary forms, or apply hash functions for security or further analysis.
6. Two-Step (Check and Fetch) Commands:
The system uses a two-step process. First, it “checks” for matches and sends back a bitmap or count. Then, if the host computer wants the actual data, it can “fetch” just those pieces. This cuts down on unnecessary data transfer and speeds up analysis.
7. Sparse Data Handling:
If matches are rare (the data is “sparse”), the device can just send the positions of matches, rather than a full bitmap. This makes the process even more efficient when only a few matches are expected.
8. Compatibility and Simplicity:
Commands are designed to fit well with existing standards, like NVMe (Non-Volatile Memory Express), making it easier to add to current systems. The commands are simple, clear, and easy to use, so programmers and users don’t need to learn complex new tools.
9. Multi-Dimensional and Parallel Processing:
The system supports checking across multiple columns or even multiple tables at once, and can run these checks in parallel. This is a big advantage for modern analytics and machine learning tasks.
10. Extensibility:
The design allows for extra features, like setting upper limits on the number of results, combining multiple checks with Boolean logic, and supporting different data types and encodings.
These innovations add up to a storage system that can answer questions quickly and efficiently, with less complexity and more flexibility than older solutions. By moving analytics closer to where the data lives, it helps businesses and researchers work faster, save money, and get more value from their data.
Example Use Cases
Let’s walk through a few simple examples:
– Searching for a Name: Suppose you have a huge list of customer names and you want to know if “Jane Doe” appears anywhere. The host computer sends a command with “Jane Doe” as the search string. The storage device checks all the names using its sliding window method, marks where it finds matches, and sends back a bitmap or just the locations to the host. The host now knows exactly where “Jane Doe” is found, without reading the whole list.
– Counting Unique Visitors: You have a log of millions of website visits and want to know how many different users visited. The device applies the HyperLogLog algorithm, hashes each user ID, puts them into buckets, tracks leading zeros, and calculates an estimate. The host gets an accurate count without having to download the whole log.
– Filtering by Date Range: In a table of orders, you want to find all orders between two dates. The host sends the filter criteria and address range. The storage device checks each order date, marks the matches, and sends back just the results. The host can then fetch the full details for only the orders that matter.
How This Impacts the Industry
With this invention, businesses and researchers can process much larger datasets, faster and with less cost. Cloud services can support more users with fewer servers. Banks can spot fraud sooner. Scientists can run more experiments and get answers faster. Because the system is designed to be simple, flexible, and compatible with current technology, it can be adopted widely without major overhauls.
Conclusion
The patent application for enhanced check-fetch in analytical storage offers a big step forward in how we process and analyze data. By enabling storage devices to handle common analytical tasks—like searching, counting, and filtering—right where the data lives, this approach saves time, reduces data movement, and makes analytics more accessible to everyone.
Key innovations like sliding window string matching, efficient bitwise marking, flexible support for different data formats, and clever algorithms like HyperLogLog for uniqueness counting, all work together to create a storage analytics system that is both powerful and easy to use. By focusing on simplicity, compatibility, and efficiency, this invention paves the way for faster, smarter data-driven solutions in every industry.
As data grows, so does the need for smarter ways to process it. This patent shows a clear path forward, making near-storage analytics a reality for more organizations and use cases than ever before.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335511.