Invented by Rishabh Jain, Erik M. Schlanger, Oracle International Corp
The On-chip atomic transactions engine is a technology that allows for the execution of atomic operations on a single chip. Atomic operations are a set of instructions that are executed as a single unit, meaning that they cannot be interrupted or modified by other processes. This technology is designed to provide a faster and more efficient way to process transactions by reducing the amount of time it takes to execute each transaction.
The market for On-chip atomic transactions engine is growing rapidly as more and more companies are looking for ways to improve their transaction processing capabilities. This technology is particularly useful for companies that process large volumes of transactions, such as financial institutions, e-commerce companies, and online gaming companies.
One of the key benefits of On-chip atomic transactions engine is that it can significantly reduce the time it takes to process transactions. This is because atomic operations can be executed much faster than traditional transaction processing methods. This means that companies can process more transactions in less time, which can help to improve their overall efficiency and productivity.
Another benefit of On-chip atomic transactions engine is that it can help to reduce the risk of errors and inconsistencies in transaction processing. Because atomic operations are executed as a single unit, there is less chance of errors or inconsistencies occurring during the transaction processing process. This can help to improve the accuracy and reliability of transaction processing, which is particularly important for financial institutions and other companies that deal with sensitive data.
The market for On-chip atomic transactions engine is expected to continue to grow in the coming years as more and more companies adopt this technology. This is because the benefits of On-chip atomic transactions engine are clear, and companies are looking for ways to improve their transaction processing capabilities in order to remain competitive in today’s fast-paced business environment.
In conclusion, the market for On-chip atomic transactions engine is growing rapidly as more and more companies are looking for ways to improve their transaction processing capabilities. This technology offers a number of benefits, including faster transaction processing times, reduced risk of errors and inconsistencies, and improved accuracy and reliability. As such, it is likely that we will see more and more companies adopting this technology in the coming years as they seek to improve their overall efficiency and productivity.

The Oracle International Corp invention works as follows
Hardware-assisted Distributed memory systems may contain software configurable shared memories regions in the local memory for each of multiple processor cores. These shared memory regions can be accessed via a network of one-core atomic transaction engines (ATE) instances. This private interconnect matrix connects them all. Remote Procedure Calls (RPCs) may be issued by ATE instances to remote processor cores to execute operations on memory locations controlled remotely. RPCs may be received from other ATE instances, or generated locally. Each ATE instance can process RPCs (atomically). An ATE instance can execute some operations using dedicated hardware. Other operation types may require that the ATE instance interrupts its local processor core in order to execute the operations.

Background for On-chip atomic transactions engine
Field of the Disclosure.
This disclosure is general in nature and relates more specifically to distributed shared memory system and systems and methods for using dedicated on-chip hardware to perform anatomic transactions on local data.
Description of Related Art
Maintaining data consistency and hardware scaling is crucial as the processors in a system increase. Traditional shared memory systems, such as virtual memory systems, and traditional distributed memory system are not able to meet these requirements. This is especially true for multi-processor systems where multiple processes use shared memory. Distributed Shared Memory (DSM), which attempts to solve both these problems, is typically composed of multiple independent processing nodes with local memory modules that can talk to each other using an interconnect network. DSMs typically use either a migration or replication strategy to distribute shared data. Multiple copies of the same data item can be stored in different caches or local memories through replication. This allows the requestor to have local access to data items once they have been replicated in their local memory.
Migration, however, allows only one copy of data to exist at any time. For exclusive use, all data items must be transferred to the local memory of the requestor under a migration strategy. Both replication and migration strategies require data to be moved closer to the processor who wants to use it. This overhead is necessary to ensure data consistency across all processing nodes. The complexity of the hardware responsible for this overhead is significant. These systems often include hardware mechanisms like coherent fabrics, synchronous or coherent caches, and/or snoop Logic. Accessing shared data in DSMs can be slower than data accesses to local memory. These latency can be caused by the steps involved in moving the target data items into local memory and updating the directory structures to reflect the movement. Or, it could be due the cache flush or invalidate operations required to maintain data consistency within the system.
The systems described herein can include a hardware-assisted Distributed Memory System. This is where different software configurable parts of the distributed shared memories are managed by the respective processor cores. Some embodiments allow for all access to shared memory regions through a network on-chip atomic transactions engine (ATE). One core may have one ATE instance, and all ATE instances can communicate over a dedicated, low-latency interconnect matrix.
In certain embodiments, software running on each processor core of each processor pipeline can be configured to determine if a particular operation of a distributed app should be performed by another processor core using Remote Procedure Calls. If an operation targets a memory location that is controlled by a different process, the information may be passed on to the local ATE instance. An RPC frame may be generated by the ATE instance for an RPC with response or without. A descriptor may be included in the RPC frame that indicates the operation type and the target address for it. It also might include payload information (e.g. If applicable, operation operands. If the target location can be controlled by a remote processor, the local ATE instances may send the RPC frames to the remote processor core. The remote processor core may then place information about the received RPC frames in its local queue. Local processor cores can control the target location. In this case, the local ATE instance might place the RPC information in a local queue for processing.
In at most some embodiments, each ATE instance may retrieve RPCs directly from its local queue and process them (atomically) regardless of whether they came from another ATE instance or were generated locally. An ATE instance can execute certain operations using the RPCs it receives from its local queue. The ATE instance may have dedicated circuitry that can perform simple operations such as read, write and increment, add or compare-and?swap without the need for intervention from the local processor core. The ATE instance might interrupt the local processor core for other operations.
In certain embodiments, if an RPC needs a response (e.g. if it’s an RPCWR), then the processor core for which the operation is being performed may perform one or several other operations after passing it off to its local ATE instance. If the processor core needs the response data, it might issue a ‘wait for event? instruction. The event refers to the return of an RPC reply packet from the ATE instance associated the remote core that performed this operation. In some embodiments, an ATE instance may generate an RPC response packet for a received RPCWR, and then return it to its origin ATE instance. An ATE instance may receive an RPC response frame from a local processor core. It may also write the response data into a location where the local core expects it to retrieve it.
A distributed shared memory system that uses an ATE network (as discussed herein) may be lighter and more complex than a full-cache coherent network in at least some instances. The systems described herein, for example, may have higher overall performance or be more flexible than DSMs by moving operations closer towards the data they operate (rather that moving data near to processors that initiate them).

In traditional distributed memory systems, shared data is distributed by either a replication strategy or a migration strategy. Replication and migration both involve moving data closer towards the processor that is interested in it. Both strategies require significant overhead to ensure data consistency across all nodes. The hardware-assisted distributed memory system described herein may include software-configurable shared memory regions in each core’s local memory and in the main memory. These systems may have access to shared memory regions through a network or ATE instances on each processor core. A private interconnect matrix connects all ATE instances together. Remote Procedure Calls (RPCs), issued by ATE instances to other ATE instances, may be used for operations in which the target memory address of an operation is in another core’s local storage. Each ATE instance can also process RPCs from other ATEs. In some cases, an RPC being processed by an ATE instance could be considered a blocking instruction. This means that the ATE instance will not accept additional transactions (RPC-issued requests) until the current RPC has been executed.
Unlike traditional DSMs, which move shared data to make it more accessible to processors (via replication or migration), the systems described herein leave shared data in place and use the processing power that is already close to it (either the local processor core oder an associated ATE instance) in order to operate on that data. In some embodiments, an ATE instance could control access to a specific portion of a distributed share memory. This is regardless of whether a processor wishes to work on the data in that particular portion of the distributed share memory. Each ATE instance may offer a simple instruction set, and may perform RPC operations on hardware for RPCs using those instructions that target an address within the shared memory that is governed. The ATE can also call upon its local processor core for RPC operations. These operations may target an address within the shared memory governed by the ATE.
In certain embodiments, the method described herein may be used to reduce the need for shared data and still ensure data consistency. Other embodiments may not guarantee data coherency, but the need to enforce hardware-enforced data coherency can be reduced using a combination of the ATE instances’ constructs and simple rules that the software must follow. These constructs can be used to simulate coherency and, if used correctly, may result in coherency. This hybrid approach, which may include those that use distributed shared memory to store variables used for synchronization (e.g. in semaphores or mutexes) and message passing, may result in a significant reduction in hardware costs compared with earlier approaches. There is also a slight increase in software complexity.
As explained in greater detail herein, if a processor wishes to access data in a part of a distributed share memory controlled by another processor’s processor, rather than moving the data closer to that processor, the requesting process (or an ATE instance associated to the requesting CPU) can send an RPC frame via a dedicated ATE net to the processor that controls that portion of the distributed memory or, more specifically to an ATE instances associated with the destination. The RPC frame may be processed by the dedicated ATE network in less time than it takes to perform data migrations or invalidate cache operations.
In certain embodiments, the RPC frame may reach the destination processor. An ATE instance associated with that processor may access the shared space controlled by that processor through its local data memory (DMEM), or through data caches that access main system memory (e.g. DDR memory). The ATE instance might have functionality that allows it handle RPCs independently (e.g. without interrupting the processor). The processor might be doing something else, such as executing its instructions or performing its tasks, while the ATE instance accesses and executes the RPC frame. The ATE may, in other words, be configured to assess whether the RPC operation described within the RPC request frames is possible in hardware. If it is able, it may access the target address via its own interface to the distributed shared memory (sometimes referred to as the DMEM or local data cache), process the data (as described in the RPC request frames), and then send a reply back to the original requestor (or to its ATE instance) if necessary.
In some systems described herein, ATE instances might be able to perform simple operations on shared data on-the fly. These systems do not require that the latest copy of shared data be moved to remote cores before any logical, arithmetic, or other operations can be performed. Instead, the processing power near the data can be used to perform the operation. This may reduce overhead associated with maintaining caches coherent.
In at most some embodiments, the ATE implementation might define a framework for RPC operations. Some of these may be implemented in hardware within the ATE instances while others may be performed by software or may require the action of the local processor core. This framework could allow shared data to be accessed before it is sent. This means that instead of sending the operands to a request core for an operation, a description may be sent by the requesting center to the core that controls target data. Different RPCs may require data to be returned. For further processing, some RPCs and embodiments may store the RPC response frame data as a value of a local variable (e.g. in a special purpose register, or in the core’s local memory).
While some RPC requests that the ATE hardware automatically handles may seem simple, some operations may require more complex operations. In some cases, the ATE instance may be able handle more complicated operations. The ATE instances might be able to recognize that RPCs with an RPC identifier (an RPCID), are RPCs it can process independently (e.g. without interrupting the processor core). The ATE instances might need to interrupt the local processor core in order for RPCs with an RPCID value outside of this range to be processed. The local processor core might take an interrupt in these cases and properly process the RPC frame. In certain embodiments, software running on a local processor can issue RPCs directly or may have control over whether an RPC is issued.
As mentioned above, some embodiments may allow all access to shared address space to be made via the ATE private interconnect. This could reduce latency for accessing shared data and keep hardware costs down (as compared to cache coherency-based DSMs). The network of ATE instances could be used as a single access point to the shared address space in the DMEM or at least the part of it. A core might have access to a specific region of shared memory. This portion should then be stored in its own DMEM. All of the processor cores might be able to access the same region of shared memory. It may not be desirable to have a local ATE instance accessing a particular location of the shared storage memory for another core, while the local core directly accesses the DMEM and modifies that data. This would violate atomicity guarantees, which are critical in distributed shared memory systems. In some embodiments, accesses to a particular region of shared memory may be required by the ATE instance to request an RPC frame. This is even if the local processor core already has direct access through its DMEM interface or data cache interface. The ATE instance could, in effect send an RPC frame to its self, indicating it wants to perform the operation. The shared memory region can be located in either the main memory or the local DMEM. In this case, it could be accessed through the data cache of the processor core by the ATE. In some cases, the DMEM may be referred to in the descriptions.
As explained in greater detail herein, if the ATE instances sends an RPC to themselves, the ATE instances may recognize the RPC frames as something it needs to process, and may queue them up in a local RPC receiver queue. In some cases, operations are not mixed in the receive queue. This is because ATE instances work within RPC boundaries. When an ATE instance begins processing an operation for a specific processor core (e.g. a local processor core or a distant processor core), it can not stop working and begin to work on another core until it has completed what it was doing for that particular processor core. The ATE instance may view each RPC frame, as if it were an atomic transaction. It may also not take up any other operation from the RPC queue until the previous operation is completed. The system can guarantee that if a local core attempts to access a portion of shared memory it controls, it will not overwrite or corrupt data that another core is accessing simultaneously.

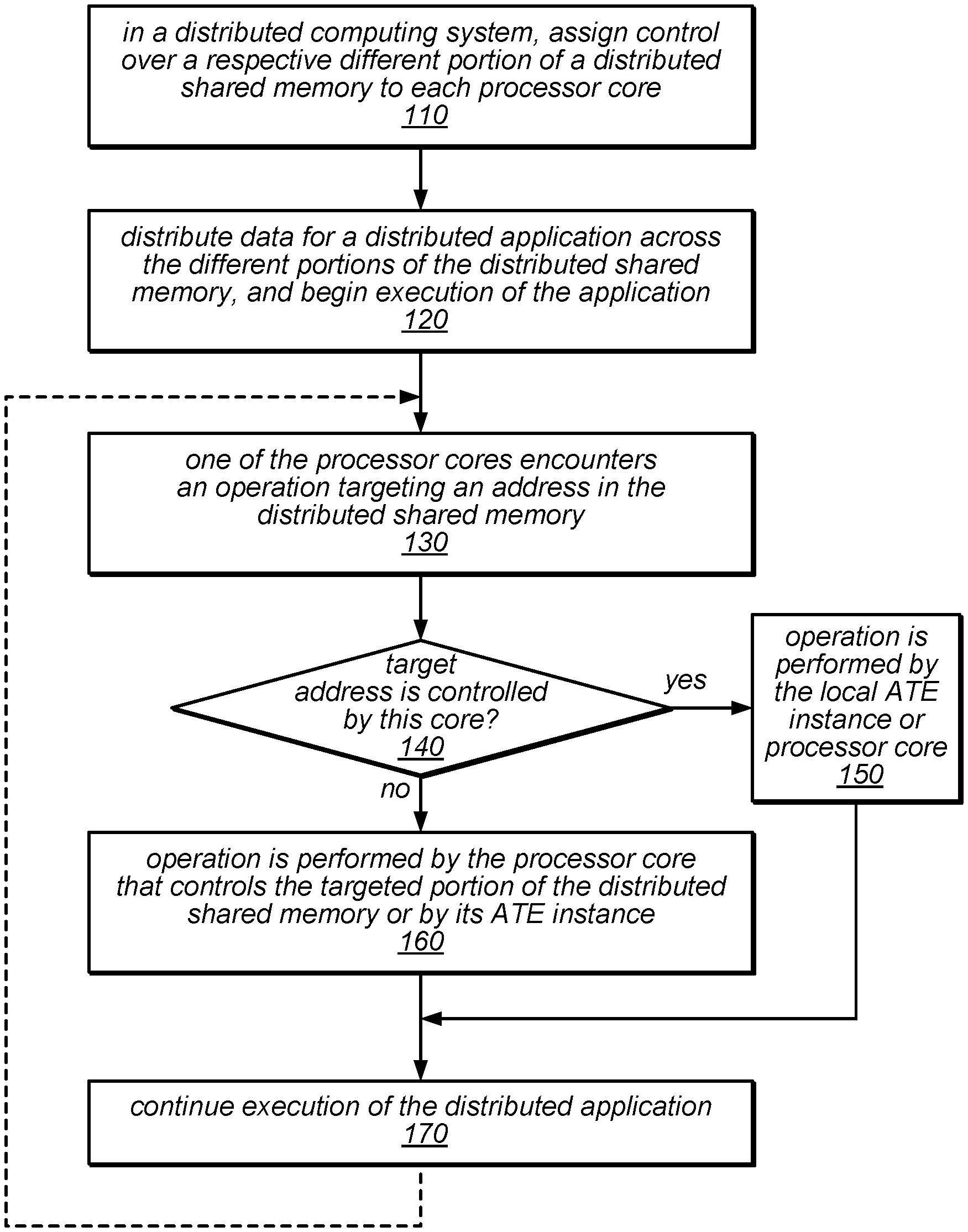
The flow diagram in FIG. illustrates one embodiment of a method to use an atomic transaction engines in a distributed computing environment. 1. The method could also include distributing control over a different part of a distributed memory to each core in the distributed computing platform, as illustrated at 110. This method could also include the distribution of data for a distributed app across different parts of the distributed shared memories and the beginning of execution, as in 120.

Click here to view the patent on Google Patents.