Invented by Kaloian Petkov, Chen Liu, Shun Miao, Sandra Sudarsky, Daphne Yu, Tommaso Mansi, Siemens Healthcare GmbH
One of the key factors driving the market growth is the increasing adoption of 3D medical imaging techniques, such as computed tomography (CT) scans, magnetic resonance imaging (MRI), and ultrasound. These imaging techniques provide detailed and comprehensive information about the patient’s anatomy, allowing healthcare professionals to make more accurate diagnoses and treatment plans. However, the interpretation of these images can be challenging, as they often contain complex structures and subtle variations in tissue density.
Consistent rendering technology addresses this challenge by providing a standardized and uniform representation of the 3D medical images. It ensures that the images are displayed consistently across different software applications, workstations, and devices, regardless of their specifications or operating systems. This allows healthcare professionals to compare and analyze images from different sources seamlessly, improving their diagnostic accuracy and reducing the risk of misinterpretation.
The market for consistent rendering of 3D medical images is also driven by the increasing need for remote collaboration and telemedicine. With the rise of telehealth services, healthcare professionals are now able to remotely access and review medical images, enabling them to provide timely and accurate diagnoses to patients located in remote areas. Consistent rendering technology plays a crucial role in this process, as it ensures that the images are accurately displayed on different devices, enabling effective communication and collaboration between healthcare professionals.
Moreover, the market is witnessing a surge in demand for consistent rendering solutions from medical device manufacturers. These manufacturers require reliable and standardized rendering tools to integrate into their medical imaging devices, ensuring that the images produced by their equipment can be easily interpreted and analyzed by healthcare professionals. Consistent rendering technology provides a cost-effective and efficient solution for these manufacturers, enabling them to enhance the functionality and usability of their products.
In terms of geographical demand, North America is expected to dominate the market for consistent rendering of 3D medical images, owing to the presence of advanced healthcare infrastructure and high adoption of advanced imaging techniques in the region. However, emerging economies in Asia Pacific, such as China and India, are also witnessing significant growth in the market, driven by the increasing investments in healthcare infrastructure and the rising demand for advanced medical imaging solutions.
In conclusion, the market for consistent rendering of 3D medical images is experiencing rapid growth, driven by the increasing adoption of 3D medical imaging techniques, the need for remote collaboration, and the demand from medical device manufacturers. This technology plays a crucial role in improving diagnostic accuracy, facilitating remote healthcare services, and enhancing the functionality of medical imaging devices. As the healthcare industry continues to evolve, the demand for consistent rendering solutions is expected to further increase, creating lucrative opportunities for market players in the coming years.

The Siemens Healthcare GmbH invention works as follows
For three-dimensional render, a machine learned model is trained to produce representation vectors for rendered pictures formed with different rendering parameters settings. Distances between the representation vectors and the reference image are used to choose the rendered image with the corresponding rendering parameter settings that provide consistency with the reference. In an alternative or additional embodiment, optimized pseudo random sequences are used to render physically based images. The random number generator is chosen to improve convergence speed and provide better quality images. For example, images can be provided more quickly for training than using non-optimized seeds.

Background for Consistent rendering of 3D medical images
The present embodiments are related to the medical imaging of 3D scans. The volume data is rendered to allow visualization. “Due to the different scan settings and variability of patients, renderings may appear different for different patients at different times.
To reduce variability, existing medical renderings provide a set static visualization presets that are tailored to specific workflows and diagnostic contexts. The rendering can still require manual adjustments and not produce consistent results, even with static presets. Inconsistency may be due to patient and scanner variability. Semi-automatic machine-learning approaches have been used for transfer function design (e.g. ray casting or Alpha blending) in traditional volume rendering, but may not reduce variability enough.
Variability can be a problem for physically-based rendering of volume, which is reliant on the simulation of light propagation. Computer-generated graphics can be enhanced with global illumination techniques that simulate the interaction of light and various 3D objects. The result is a more realistic rendering that the brain can easily interpret, compared to traditional renderings. These physical-based visualization techniques respond more quickly to changes in classification or interpretation of the medical data. Due to this, even small changes in rendering parameters can have a greater impact on the perception of 3D structures within the final image than traditional volume rendering techniques. The user can then choose to obtain reproducible images of high quality with diagnostic value. Although existing visualization presets can be helpful, the rendered images may not always have the same quantitative properties (colors, hues, reflectance, and so on). across datasets. It takes longer for a physically-based rendering to produce a rendered image. Therefore, altering the image to reduce variability can be time consuming.
The preferred embodiments are described below as an introduction. They include computer-readable media, methods, systems and instructions for three-dimensional render. A machine-learned model is trained to produce representation vectors for rendered pictures formed with different rendering parameters settings. Distances between the representation vectors and the reference image are used to choose the rendered image with the corresponding rendering parameter settings that provide consistency with the reference. In another embodiment, pseudo-random optimized sequences are used to render images based on physical principles. The random number generator is chosen to improve convergence speed and provide better quality images. For example, images can be provided more quickly for training than using non-optimized seeds.
In a first aspect, it is possible to render three-dimensional images in a rendering software. A medical imaging system obtains a dataset of medical data representing a three dimensional region of a person. A renderer renders a number of images using different rendering settings. Image processors apply different pairs of images from the plurality of images and a reference to a machine-learned model. The machine-learned models is trained to produce representation vectors for the images and reference image. Image processor chooses one image from a plurality based on representation vectors. The image processor displays the selected image from a plurality.
In a second aspect of the invention, a system for rendering three-dimensional images in medical imaging is provided. A medical scanner configured to scan the volume of a human patient. The graphics processing unit renders images in three dimensions from the volume scan. Images are rendered using different rendering parameters. A machine-learned neural network is used to train an image processor to find the image that matches a reference. “A display is configured to show the single image of the patient’s volume.
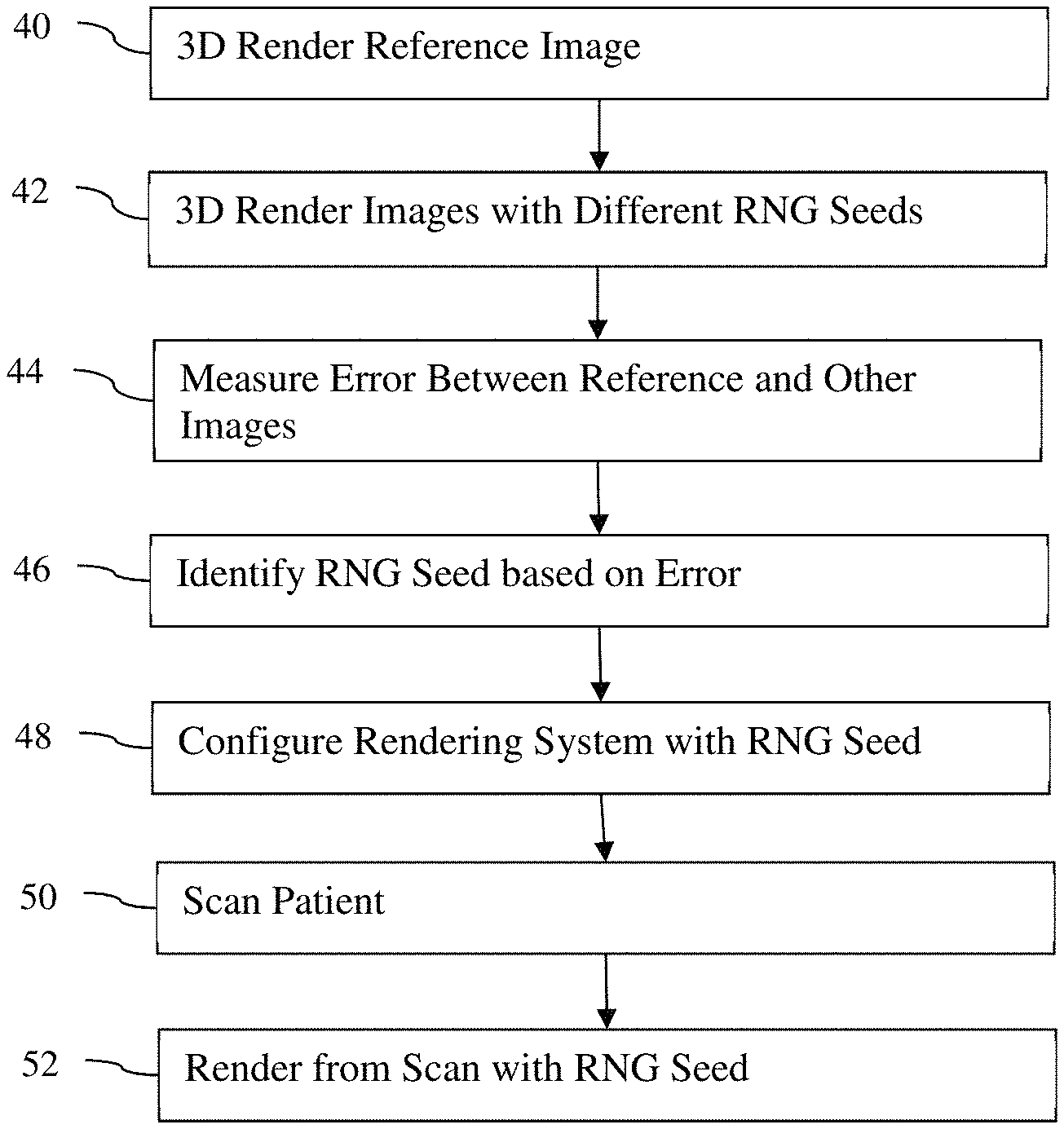
In a third aspect of the invention, a method for rendering three-dimensional images in a rendering device is disclosed. Path tracing is used to render a reference image in three dimensions using a number of pixels and a random number generator seed. Path tracing is used to render other images in three dimensions using a lower number of samples per pixel. The second number must be less than the original by at least a factor of 10. The error between other images and reference image is calculated. The random number generator seed with the least error is selected. The rendering system configures the path tracing using the randomly selected number generator seed.
The following claims define the invention. Nothing in this section should be construed as limiting those claims. Additional aspects and benefits of the invention will be discussed below, in conjunction with the preferred embodiments. They may be claimed later independently or together.
Two general approaches are presented here. In one approach, an image representation network that is machine-learned renders medical images in three dimensions. The machine-learned representation method is described in the following section with reference to FIGS. 1-3. In another approach, the pseudo-random sequencing for physically-based render is optimized. The pseudo-random approach will be described in the following paragraphs with reference to FIG. 4-7. The different approaches can be used individually. These different approaches may be used separately.
For machine-learnt comparing, an unsupervised network of neural networks maps an image x into a vector representation denoted by f(x). The vector representation is characterized by a certain property. The Euclidean Distance between two representations is correlated with the difference in their visual effects. (i.e. representations that have similar visual effects will have a small Euclidean Distance). This representation is used for automatically selecting rendering parameters of a photorealistic renderer (i.e. physically-based), or any other renderer, to produce desired effects.

Consistent interpretation of 3D images could simplify diagnostic workflows and promote clinical use 3D data to support decision-making.” Photorealistic rendered images can be used in new platforms and workflows such as cloud-based rendering and fully automated reporting. A reference selected by an expert or practice can be used to provide consistency. A general approach that is adaptable and uses a machine-learned comparison to a standard reference allows for variances in rendering parameters. “The same approach can be applied to a variety of clinical situations or problems.
FIG. “FIG. 1 is one embodiment of the method for machine-training for comparison. By comparing different rendered images to a reference, representation learning can be used to determine the optimal rendering parameters. Artificial intelligence systems are given multiple images that they can compare with a reference image. The training then learns which of these multiple images are most similar to the reference. The machine is taught to produce a scalar that indicates which of the images are most similar to the reference. This training creates vectors which can be compared in order to determine perceptual similarity. The trained network maps an input image into a vector, with the property that Euclidean Distance between two vectors correlates to the visual effect differences between the two images. Searching for the rendering with the minimum Euclidean difference will give the most similar rendering of the reference. The resultant image is more likely to include diagnostically useful information, or another characteristic that is reflected in the original reference. This can be used for diagnosis.
The method shown in FIG. The machine training system of FIG. In one embodiment, FIG. In one embodiment, the system of FIG. The method of FIG. 1 can be implemented with or without a medical scanner, display and/or other devices. The data can be loaded from a memory and then rendered by the graphics processor unit (GPU), the image processor will perform the training using the data, while the memory will store the artificial intelligence that has been learned. Another example is that the medical scanner or memory inputs data to the server which then performs the training. The outputs are stored in a memory.
The acts are performed either in the order indicated (top to bottom), or in another order. In some learning methods, the results can be used as input to repeat an act.
Additional, different or fewer Acts may be provided.” Act 18 for example is not included, as it is only used when the artificial intelligence has been trained, and is not stored to be used later.
In act 12 training data are input. The training data are gathered by one or more sensors, memory, or scanners. The data gathered may be transmitted and/or stored to a processor, memory, cache or any other device. The machine learning algorithm uses this training data as input.
Many samples of the same data type are input. Tens, hundreds or thousands of samples may be used to learn relationships between statistical data or other types of information that are so complex that humans cannot understand them.
Any data can be used.” A pool of three-dimensional volume is collected for representation learning. These volumes are scans of one or several patients. Volumes are specific to a particular application, like vascular computed Tomography (CT). The volumes can be generic, such as whole-body volumes or different parts.
Since artificial intelligence must be trained to compare or provide relative similarity to a reference image, images rendered in three dimensions are used as training data. Each sample is based on an image generated from scan data that represents a patient. You can use any rendering method, including raycasting, surface renderings, projections, maximum intensity projections, or physically-based renders (i.e. path tracing). Physically-based render simulates the propagation of light through the volume. It is not the same as illumination or shading, which are used for ray casting and surface rendering. Instead, it uses pseudo-random simulations of different paths light may take. “Any path tracing can be used, including unbiased path-tracing or Monte Carlo rendering. Global illumination and other simulations of the propagation of light may also be used.
The samples for training are divided into sets of three. This is because the goal of the representation learning process is to compare images. If representations of additional images are part of the network architecture then samples may be provided in different size groups (e.g. four images).

In one embodiment, three images are rendered with the same camera position,?0 and random rendering parameters,?i. Images are designated as R(V?0?i), 1,2,3. Three camera positions?i=1,2,3 will be generated at random, and then three images R(V?i?i?i?i?i?i?i?i?i?i?i?i?i?i?i?0?i?i?i?i?i?i?i?i?i?i?i?i?i?i? i=1,2,3?i?i?i?i?i?i?i?i?i?i?i?i?i=1,2,2,3?i?i=1,2,2,3) are rendered for each camera position?i=?i?i?i=?i=?i=?i?i?i=?i=?i=?i=?i?i=?i=?i=?i?i=?i?i?i?i?i?i=?i?i=?i=1,2,3???3????3??3??3?3?3?3?3?i?i?i?i?i?i?i?i?i?i?i?i?i?i?,?i?i?i?i?i?i?i?i?i?i?i?i?i?i??i?i?i?i?i?i?i?i?i?i?i?i=1,2,3?i?i=1,2,3?i=1,2,3?i=1,2,3?i=1,2,3?i=1,2,3?i=1,2,?i=1,2,3?i=1,2,3?i=1,2,3?i=?i?i=1,2,3?i=?i?i The same rendering parameters are used to render the images for each of the three camera positions. This six-image set is called a “dataset”. This process is repeated for each 3D volume V. You can use other numbers, such as tens of thousands of images or hundreds of camera positions. “The same volume can be used to generate more than one set of images or dataset.

Click here to view the patent on Google Patents.