Invented by LIN; Nien-Hsien, HOH; Cheng-Kuan, SHIH; Yen-An, CHEN; Wei-Shuo, TSAI; Cheng-Han, CHEN; Cheng-Che


Managing computer performance is hard, especially when you want your device to run fast but not waste too much power. A new patent application brings a smart way to solve this problem. It uses reinforcement learning—a type of machine learning—to help computers adjust their own performance as needed, without people having to set lots of rules or tweak settings by hand. Let’s walk through the key ideas, the science behind them, and what makes this invention stand out.
Background and Market Context
Computers are everywhere. They live in our phones, tablets, laptops, servers, and game consoles. Each of these devices has to do many things at once, often with limited power and space. People want their computers to be fast, whether they are playing games, editing videos, or running big data programs. But at the same time, they want their batteries to last longer and their devices not to get too hot.
Companies that build computers try to balance these needs by making their devices smarter about how they use their parts. Processors, memory chips, and graphics units all play a role. Each of these parts can be tuned to run faster or slower, depending on what is needed. For example, when you are playing a game, your graphics chip needs to work hard to draw each frame quickly. But when you are just typing a document, it can slow down to save power.
Until now, most computers have used simple rules to decide how much power and speed to give each part. These rules might say, “If the temperature goes above a certain point, slow down,” or “If the frame rate drops, speed up.” Sometimes, software engineers write complex scripts to try and guess what the user needs. But every app is different, and even inside a game, the needs can change suddenly—from a simple menu to a crowded action scene. This makes it very hard to get the balance right all the time.
Making these settings work well usually takes a lot of manual effort. Someone has to test the device with different programs, see what works, and then write new rules. This takes time and is never perfect. Even the best rules can’t predict every situation. As more apps use 3D graphics, machine learning, or real-time analytics, the old ways of managing performance start to show their limits.

The market is hungry for a solution that can keep up with changing needs, without human intervention. People want their devices to feel smooth and snappy, but also to last longer and not overheat. Game studios, video editors, and even regular users would benefit from smarter computers that “just work.” That is where the new reinforcement learning system comes in—it promises to adapt on its own, learning from real usage and making better decisions every moment.
Scientific Rationale and Prior Art
Let’s talk about how computers have tried to manage their own performance before, and why that is not enough today. Traditionally, computer systems use a mix of hardware sensors, rule-based scripts, and manual tuning. For example, a laptop might check its internal temperature, and if it gets too high, it lowers the speed of the CPU. Or a game might set a target frame rate and try to keep up by raising or lowering the graphics quality.
These methods rely on “if-then” rules: if something happens, do this. Sometimes, these rules are complex, taking into account many variables, like battery level, user settings, or app type. But no matter how many rules you add, you can’t plan for every possible situation. Some apps use lots of memory; some need fast graphics; some switch between needs very quickly. Manual rules become hard to manage, and they don’t adapt well when something new happens.
Other approaches try to use more advanced algorithms. Some systems use feedback loops, like PID (proportional-integral-derivative) controllers, which adjust settings based on errors—how far the actual result is from the desired one. These can help, but they still need tuning, and they don’t learn from experience. If the system changes—a new app, a new user—they have to be tuned again.
Machine learning has started to enter this space, but mostly in the form of “predictive” models. For example, some systems may try to guess how much CPU an app will need and prepare in advance. But these systems usually require a lot of training data and still rely on fixed models. They can’t change their behavior on the fly, especially in the face of new or unusual usage patterns.
This is where reinforcement learning (RL) stands out. RL is not just about predicting; it is about learning by doing. In RL, an “agent” makes decisions, sees what happens, and gets a reward or penalty. Over time, it learns which actions bring better results. RL is used in game AI, robotics, and even self-driving cars. The main idea is simple: try something, see how well it works, and adjust.


Some research has explored using RL for computer performance control, but these are mostly in academic papers or limited test systems. They tend to be complex, hard to integrate, or not flexible enough for real-world devices. What was missing was a way to use RL in a simple, modular system that can work with any app, collect feedback in real time, and make smart adjustments that keep the user happy.
The new patent application builds on these ideas but brings several new twists. It sets up a closed loop, where the RL agent interacts with the “environment” — meaning the real app and device. It collects real measurements, such as frame rate and performance, and uses a reward function that is easy to understand. It not only learns what to do, but also adapts its own learning rate over time, becoming more or less aggressive as needed. This makes it suitable for everything from gaming consoles to workstations, and even mobile devices with tight power budgets.
Invention Description and Key Innovations
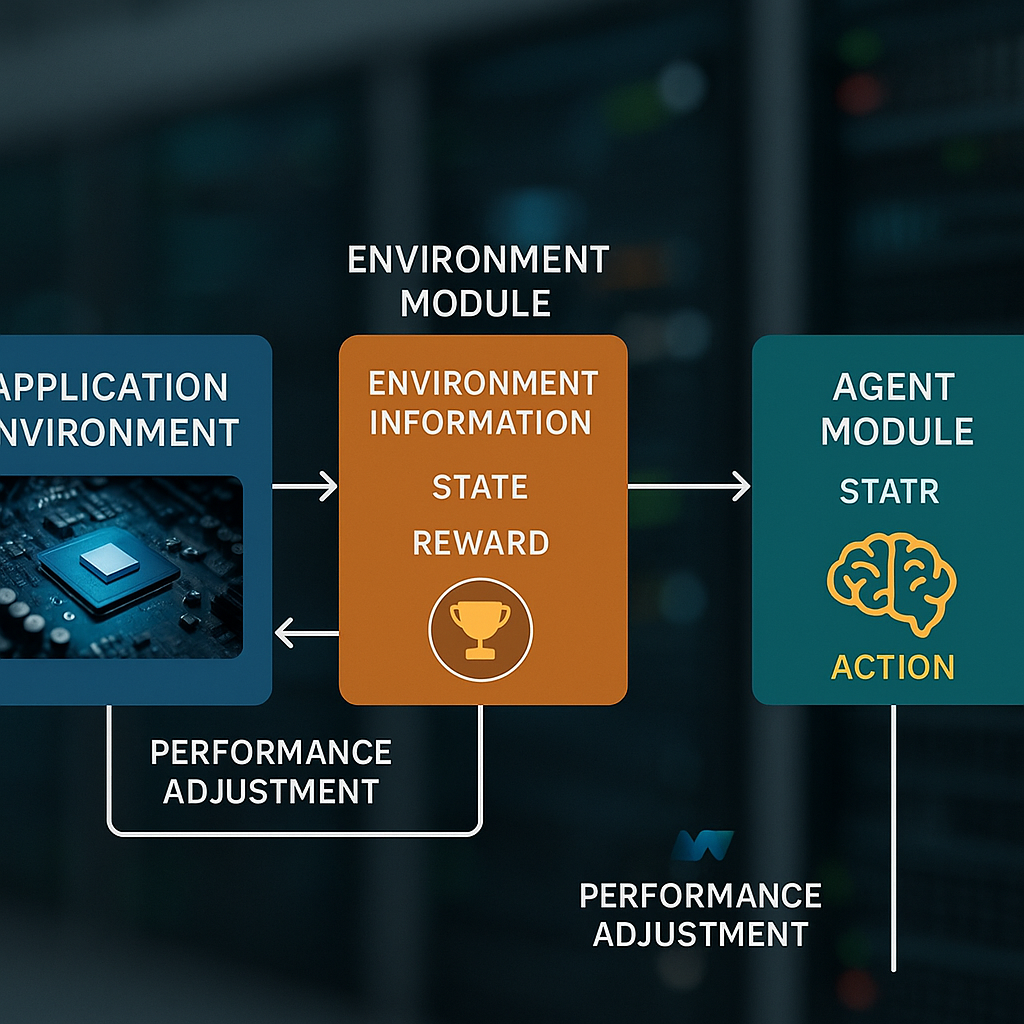
The core of this invention is a system with two main parts: an environment module and an agent module. The environment module is like the system’s eyes and ears. It gathers information from the real application environment. This means it checks what the current frame speed is (how fast images are being shown), what the target speed should be (the goal), and how hard the computer is working at that moment (actual performance).
The agent module is the brain. It gets the information from the environment module and decides what to do next. Its job is to figure out whether the system needs to speed up, slow down, or stay the same so that the user gets a smooth, responsive experience without wasting energy or overheating the device.
Here’s how it works in practice:
First, the environment module collects three key things: target frame speed (what the app wants), actual frame speed (what is really happening), and actual performance (how fast the computer is running). It might get this information directly from the operating system using APIs, or by running simple scripts that check the state of the device.

Next, the environment module calculates a reward value. This is a number that says how close the system is to its goal. If the frame speed is just right, the reward is high. If it is too slow or too fast, the reward goes down. This reward is not just a random number—it is calculated using a simple formula that measures the difference between the target and the actual frame speed. The smaller the difference, the better.
The environment module then sends this reward, along with the latest measurements, to the agent module. The agent looks at the reward and the state, and decides how big of a change to make. It does this by figuring out a “step size”—how much to adjust the settings. If things are far from the target, the step size gets bigger so the system can react quickly. If things are close to perfect, it makes smaller tweaks for finer control.
The step size is not fixed. It depends on both the reward value and a learning rate, which the agent can adjust on its own. The learning rate tells the system how fast it should change its behavior. If the environment is stable, the agent can lower the learning rate and make smaller adjustments, which keeps things smooth. If the environment is changing quickly, the agent can raise the learning rate and react faster. The learning rate itself can be optimized with popular RL methods like Q-learning or Proximal Policy Optimization, but the patent keeps the details flexible so it can work with different algorithms.
The agent then decides what action to take. Sometimes, it adjusts the target frame speed directly. For instance, if the game is lagging, it might try to lower the frame time (so frames come out faster) or raise the frame rate. Other times, it might adjust a broader “performance level,” such as increasing the CPU or GPU clock speed. The agent can use simple math to figure out the new targets, or it can use a mapping table that links performance settings to frame rates. If the new target does not match exactly, it can interpolate between nearby values for a smooth transition.
Once the agent makes a decision, it sends the command to the application environment. The environment then tries to apply the change—maybe by telling the graphics card to run faster, or by lowering graphical detail to help the frame rate. After the change is made, the environment module checks the new state, calculates a new reward, and the cycle begins again. This loop runs continuously, always learning and adjusting as the app runs.
This system brings several important innovations:
First, it is highly adaptable. Because it learns from real feedback, it can handle sudden changes, like a new game scene or a spike in CPU demand. It does not need pre-written rules for every possible case.
Second, it is automatic. There is no need for manual tuning or tweaking. Once set up, the system keeps improving itself, finding the best balance between speed and power for each situation.
Third, it is modular. The environment and agent modules can be implemented as software on any processor, or even as dedicated hardware. This makes it easy to add to different types of devices, from phones to cloud servers.
Fourth, the reward function and step size calculations are simple and interpretable. This means system designers can understand how the system is making decisions, and can tweak the formulas if needed for special cases.
Fifth, it is flexible about what performance metrics it tracks. Whether the goal is frame rate, frame time, or even other measures like instructions per cycle, the system can handle it. It can also collect data in different ways—using OS APIs, scripts, or direct hardware monitoring.
Finally, the method allows for continuous learning. The more the system runs, the better it gets at making decisions. The agent can even change its own learning rate over time, becoming more cautious as it gets closer to the ideal performance.
All these features together make this invention a strong candidate for the next generation of smart, self-adjusting computers. It can help games run smoother, videos render faster, and devices last longer on a single charge—all without the user having to lift a finger.
Conclusion
The world of computing is moving fast, and the demands on our devices are growing every day. The old ways of managing performance—manual tuning, fixed rules, and guesswork—just can’t keep up. This patent application’s new reinforcement learning system offers a simple yet powerful solution. By letting computers learn from their own actions and adapt in real time, it promises better speed, longer battery life, and smoother experiences for everyone. As more devices adopt these smart control systems, we can expect a future where our technology works smarter, not harder, making life easier for users and manufacturers alike.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217254.