Invented by COLCORD; Aaron David, MELLOTT; Kevin Richard, FAVELA; David Vincente, NEONG; Jeffrey Chee-Keong, Fidelity Information Services, LLC
In this article, we will explore a new data analytics platform patent. We’ll walk through the market context, scientific rationale, and the invention’s key innovations. This will help you clearly see why this technology is important and how it changes the way data analytics platforms work. Let’s jump right in.


Background and Market Context
Data is everywhere today. Every company collects data from many places—websites, apps, point-of-sale systems, and even outside sources like weather or social media. But having lots of data is not enough. Companies need to make sense of it, find patterns, and use it to make decisions. This is where data analytics platforms come in.
Traditional data platforms were built for a different time. Many of them rely on big servers sitting in a building somewhere. These servers need lots of care. As data grows, so does the need for more servers, more storage, and more people to keep it all running. This can quickly get expensive and complicated. If a company wants to add a new client or analyze a new type of data, it may take weeks or months to set everything up.
Another big problem is that older platforms often keep data for each client or product in its own separate area. Imagine a big office with hundreds of locked rooms. If you want to compare what’s in room A with what’s in room B, you need special keys, and maybe even permission from the building manager. This makes it hard to get a full picture of what’s happening across the whole company. Plus, if a client’s needs change, or if a law requires better access controls, it can be a huge job to update all the permissions or move data to new places.
Security is also a serious concern. Companies are under pressure to protect private data. Laws in many countries require companies to show who can see what data and when. If a platform can’t track data usage or keep a clear record of where data came from, the company could get into trouble.
The rise of cloud computing has changed a lot. Now, companies can rent computing power and storage as they need it. This helps them save money and scale up or down quickly. But building a secure, flexible, cloud-based analytics platform is not easy. Most existing solutions either don’t scale well, are too technical for many users, or lack strong security and tracking features.
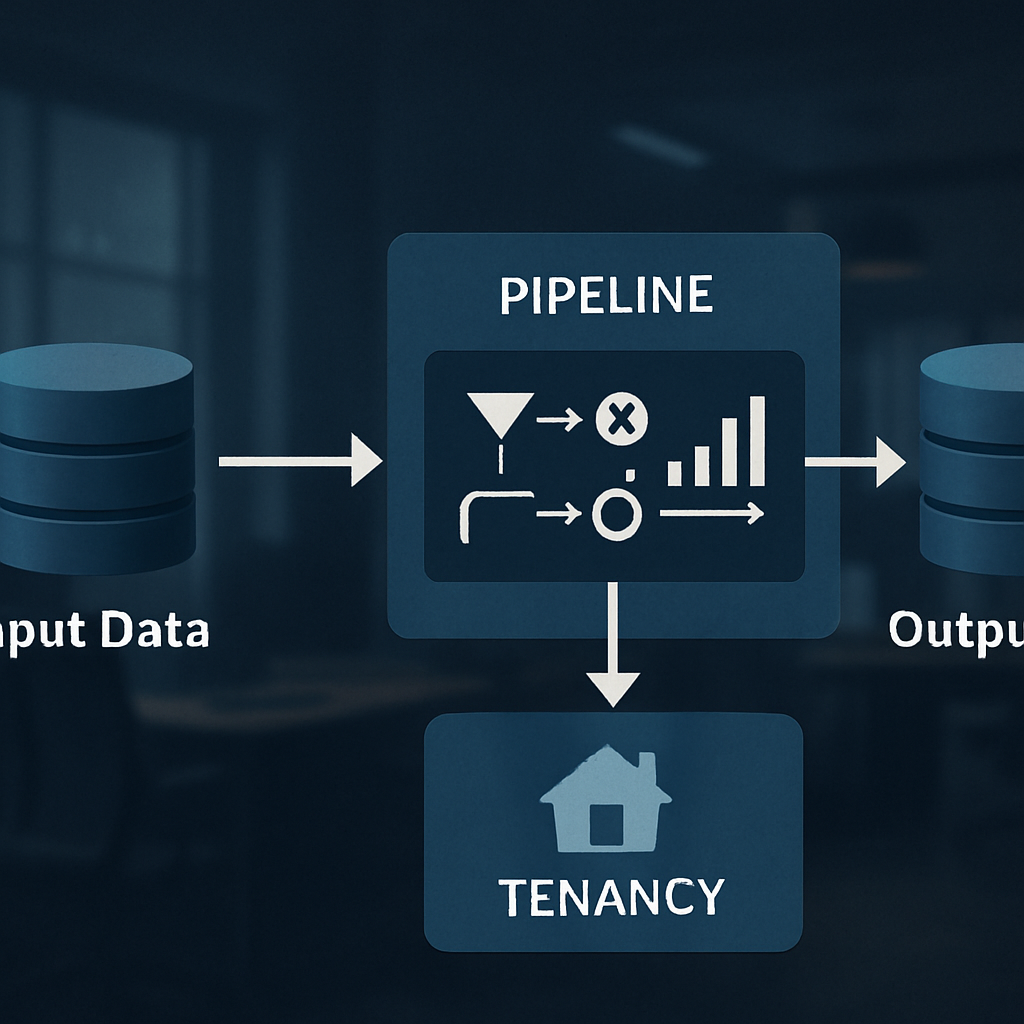
This is the context for the new patent. The invention aims to solve these problems by creating a platform that is easy to use, highly secure, and can grow as needed, all without the need for physical servers. It is built for multiple clients (multi-tenancy), making sure each client’s data is kept safe, yet still allowing for powerful analytics across different types of data.

Scientific Rationale and Prior Art
To understand how this new system works, we need to look at older ways of handling data. In the past, companies would set up large databases on their own servers. These databases were managed by teams of experts. When new data came in, it would be processed, cleaned, and stored in a way that made sense for the business. If someone needed a report, they would request it from the IT team, who would then write special scripts or queries to pull the needed data.
Over time, some improvements were made. Tools called ETL (Extract, Transform, Load) helped move data from one place to another and make it ready for analysis. Data warehouses and data lakes allowed for larger storage and more flexible ways to keep data. However, these tools still needed a lot of setup and maintenance. They also struggled with giving access to many users, especially users who were not technical experts.
Cloud computing started to change things. Companies like Amazon, Microsoft, and Google allowed businesses to rent storage and computing power. This helped with scaling, but many platforms just moved the old problems to a new place. You still needed experts to set up the systems. Managing security, access, and data ownership was still hard. If you wanted to track where data came from (data lineage) or who owned it (data tenancy), you often had to build custom tracking systems on top of your data platform.
Some platforms tried to solve the problem of multi-tenancy by simply creating separate databases for each client. This worked for keeping data separate, but made it hard to see trends across clients or move data between them. Others used complex permission systems, but these often became hard to manage as the number of users and clients grew.
Another challenge was automation. Many platforms required manual steps when adding new data, changing rules, or updating who could see what. This slowed down the process, made mistakes more likely, and increased the need for skilled staff. As regulations around data privacy and tracking grew tougher, these manual systems could not keep up.
Some recent systems added metadata—data about data—to help track ownership, security, and quality. But most still kept metadata and data management separate, making it hard to tie the two together in a way that was flexible and automatic.
The patent we are discussing builds on these ideas and solves key problems that earlier systems faced. It brings together modern cloud technology, flexible metadata management, strong security, and easy-to-use automation, all in one platform built for today’s needs.


Invention Description and Key Innovations
The heart of this invention is a serverless, multi-tenant data analytics platform. “Serverless” means the system runs in the cloud and only uses computing power when there is work to be done. There are no fixed servers to worry about; everything grows and shrinks as needed. “Multi-tenant” means the platform can serve many clients at once, keeping each client’s data separate and safe, but still allowing for smart analytics across all data when needed.
Let’s break down the key parts and innovations of the system:
1. Smart Data Intake and Storage:
When new data comes in, the system puts it into a special storage called an “append-only” store. Think of this as a big notebook where you can only add new pages—you never erase or change the old ones. This keeps a full history of all data, which is great for tracking and rebuilding if something goes wrong. It’s also good for meeting legal requirements that say you must keep records for a certain time.
After the data lands in the notebook, a smart service called a “flow” takes over. This flow reads the data, figures out who owns it (using identifying information in the data), and then gives it a special tag called a “tenancy identifier.” This tag acts like a colored sticker, showing which client or group the data belongs to.
2. Automated Processing with Flows and Metadata:
The flows are written in simple, high-level language like JSON or YAML. Even users without deep technical skills can understand and use them. Flows can be set up to handle different types of data, apply business rules, clean up bad records, and transform data into the right format for analysis. This is all done automatically, based on rules and metadata (information about the data, like its type, owner, and any special handling rules).
This design means that adding new data, changing processing rules, or updating access is as simple as changing a flow or some metadata, not rewriting computer programs or moving data around. The platform can even adjust itself based on what’s in the metadata, making it very flexible and easy to keep up to date.
3. Tenancy and Ownership Tracking:

Every piece of data gets a tenancy tag as soon as it enters the system. The platform keeps a detailed “ownership graph”—a map of who owns each bit of data, how different pieces are related, and who can see or use them. This graph can have several levels, like a family tree. For example, a big company (the parent) may have several divisions (children), and each division may have its own products (grandchildren). If you have permission to see data at the parent level, you can see everything under it. If you only have permission at the product level, you only see that product’s data.
This approach makes it simple to manage access: just change the links in the graph. You never need to copy data or rebuild databases. If ownership changes (like after a merger), you update the graph and the system takes care of the rest.
4. Security and Access Control:
The system uses the ownership graph and tags to control access. When a user or program asks to see data, the platform checks the rules. These rules can be very flexible—maybe only certain people can see sensitive data, or maybe some users can only see data for a certain period or region. If a rule changes, you update it in one place and the system enforces it everywhere.
All data access and changes are tracked, creating a full audit trail. This is important for meeting legal and business requirements. If someone tries to access data they shouldn’t, the system can block them or alert an admin.
5. Automated Metadata Generation and Management:
The platform automatically creates and updates metadata as data moves through the system. Metadata can include technical details (like file type or size), business information (like the product or source), security tags (like “sensitive” or “public”), and quality scores (like how complete or timely the data is).
This metadata is stored separately but linked to the data. It’s always up-to-date and easy to manage. Users can add their own tags or rules, making the system even more flexible. The same flows that process data can use the metadata to decide how to handle each piece—like hiding sensitive information or running special checks on high-value data.
6. Flexible Data Pipelines and APIs:
When a user or program wants to work with data, the system builds a custom “pipeline” on the fly. This pipeline brings together the needed data, applies any business rules, and delivers the result. When the job is done, the pipeline is taken down, freeing up resources. This approach is very efficient and means the platform can handle many users and requests at once without slowing down.
The system can deliver data through many types of interfaces—like GraphQL, SOAP, OData, or OpenAPI—making it easy to connect with other systems, dashboards, or apps.
7. Serverless and Scalable by Design:
Because the platform is serverless, there are no fixed servers. Everything runs in the cloud, using only as much computing power as needed. If there’s a big spike in data or users, the system grows to handle it. When things are quiet, it shrinks back down, saving money. This makes the platform very cost-effective and reliable.
How It All Comes Together:
Here’s a simple example of how the system works in practice:
A new client uploads sales data. The system puts it in the append-only notebook. A flow reads the data, tags it with the client’s tenancy, and stores it in a secure place linked to the client. Metadata is created showing the data type, owner, and any special rules (like “do not share outside the company”). Later, a user wants to run a report. The system checks if the user is allowed to see the data. If yes, it builds a pipeline, applies any needed rules (like hiding sensitive columns), and delivers the result. If the client company reorganizes, an admin updates the ownership graph and access rules update everywhere automatically.
This system is designed to make data management simple, safe, and flexible. It helps companies get value from their data quickly, without needing big IT teams or taking risks with security and compliance. The use of flows and metadata means even non-technical users can set up powerful analytics, and the serverless design keeps costs and complexity low.
Conclusion
This patent introduces a new kind of data analytics platform—one that is built for today’s needs. It solves big problems with old systems: making data easy to manage, safe from mistakes or leaks, and simple to scale up or down. By using serverless cloud technology, flexible flows, metadata-driven automation, and a smart ownership model, it gives companies the tools they need to get the most from their data—quickly, securely, and with far less effort.
If you are a business leader, IT manager, or data analyst, this invention can help you move faster, stay compliant, and focus on using data for insight—not just managing it. The next generation of analytics platforms is here, and it’s all about making data powerful, safe, and easy for everyone.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217369.