Invented by Wang; Zijia, He; Bin, Chen; Chunxi, Jia; Zhen


Advances in computer systems are making it easier for people to get answers to their questions. This patent application introduces a new way for question answering systems to understand and help users by using decision trees, natural language, and user feedback. Let’s break down why this matters, how it builds on past ideas, and what’s new about this invention.
Background and Market Context
The way people look for answers has changed. Before, you had to search through books or websites, often using keywords and hoping for a good match. Today, question answering systems try to give you direct answers in plain language. These systems are used everywhere: customer support chats, help desks, medical advice bots, online education, and more.
Most question answering systems fall into two main groups. Some are rule-based, following pre-set rules to find answers. Others use machine learning, where the system learns from lots of examples to get better at finding answers. Both need to understand what you’re asking, find the right information, and share it in a way you can understand.
As more people rely on computers for help, the need for fast and accurate answers is bigger than ever. Companies want to serve customers better, doctors want to make quick diagnoses, teachers want to help students, and businesses want to share knowledge inside their teams. But these systems still have problems. Sometimes, they misunderstand the question. Other times, they can’t find the right answer, or the answers sound robotic and unhelpful.
To solve these problems, researchers have looked at using decision trees. A decision tree is a way to organize choices and questions, like a flowchart. Each question leads to more questions or answers, helping guide the user step by step. Decision trees are used in many areas, like troubleshooting a computer, diagnosing a sickness, or guiding a customer through a product return. But even these trees have limits. They can get too big, become hard to manage, or fail to keep up with how people actually talk.

The market wants smarter, friendlier systems that can keep up with real conversations, learn from users, and get better over time. This is where the patent’s invention fits in. It brings together decision trees, language understanding, and user feedback to build a system that can answer questions more like a real person would.
Scientific Rationale and Prior Art
Let’s look at how question answering systems have worked before, and why this new invention is needed.
In the past, decision trees were built using algorithms like C4.5, CART, or decision flow. The C4.5 algorithm splits data to build a tree, choosing the best question at each step based on information in the data. It can handle messy data, but the trees can get too large and complex. The CART algorithm is similar, but uses a different way to decide splits and only makes yes/no decisions. Decision flow tries to combine nodes that are similar, so the tree is smaller and more accurate, but it needs lots of memory and can lose some details.
These classic methods work well when the data is simple and the questions are clear. But when people ask questions in their own words, or when the system needs to remember what happened earlier in a conversation, these old methods struggle. For example, if a customer says, “My computer won’t turn on,” the system needs to figure out if the problem is with the power, battery, software, or something else. If the customer changes their mind or gives more details later, the system should keep up.
Older decision trees also have problems with “data fragmentation.” As the tree gets bigger, there are fewer examples for each branch, which can make the system less reliable. Pruning (cutting back the tree) can help, but this can also remove useful information. Bad data, missing data, and different ways of saying the same thing (“laptop battery” vs “not charging”) can confuse the tree.


More recent systems use natural language processing (NLP) to turn user questions into “feature vectors” – a way to measure the meaning of words. NLP models like BERT or ROBERTa are trained on lots of text, so they understand how people talk. Some systems also use reinforcement learning, where the system tries different answers and learns which ones work best based on feedback.
But most systems don’t combine all of these ideas. They might use a decision tree, but not remember the whole conversation. Or they might use good NLP, but not have a smart way to pick the best path through the tree. Or they might not learn from user satisfaction. That’s where this new patent comes in – it puts all these pieces together.
Invention Description and Key Innovations
This invention is about a method, device, and computer program for a question answering system. It uses decision trees, NLP, and feedback to make conversations smarter, more accurate, and more human. Let’s walk through how it works, step by step.
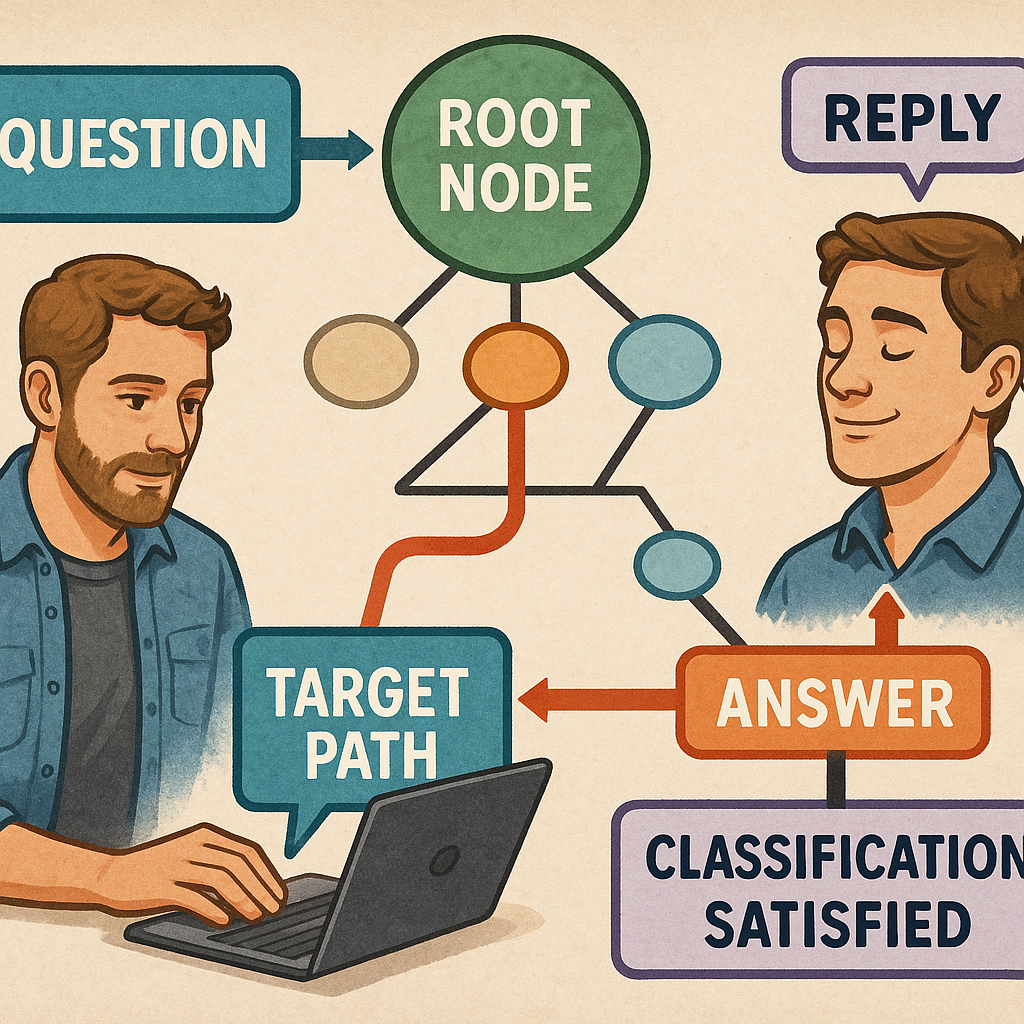
When a user asks a question, the system first tries to figure out what the question is really about. It uses a trained language model to pull out the main words and turn them into a “feature vector” – a kind of fingerprint for the question’s meaning.
Next, the system looks at its decision tree. The tree is made up of “root nodes” (big categories, like “battery problem”), with each root having several “child nodes” (smaller topics, like “plugged in?” or “overheating?”). The system compares the feature vector of the user’s question to the vectors for each node, using a similarity score. Only the child nodes that are similar enough (above a certain score) are chosen as candidates for the next step.
Now, the system looks at different possible “paths” from the root node to each child node. Each step along a path has its own similarity score, based on how well the node matches the question. The system adds up the scores for each path, and picks the path with the highest total similarity. This way, it chooses the path that makes the most sense for the user’s question.

Once the target path is chosen, the system generates an answer. This answer might be a direct reply (“Please check if your laptop is plugged in”) or another question to guide the user further (“Is your laptop under warranty?”). The answer is based on the feature vectors of the nodes along the chosen path, so it’s tied closely to what the user asked.
After the system gives the answer, it waits for the user’s reply. The user might answer “yes,” “no,” “I don’t know,” or give more details. The system takes this reply and runs it through another trained language model to create a feature vector for the reply. Then, it labels the reply – not just with what was said, but also with the type of question and how satisfied the user seems. For example, if the user says, “Thanks, that fixed it!” the system notes that the question was solved and the user is happy.
This label is important. It helps the system track the “dialog state” – all the information about the conversation so far, including past questions and answers, labels, and user feedback. The dialog state is updated after each exchange, so the system always remembers what’s happened. This allows the system to keep track of the context, personalize its answers, and avoid asking the same thing twice.
The system also builds a “structured representation” of the conversation. This means it breaks down the dialog into pieces – like entities (laptop, battery), concepts (problem, solution), and user preferences. This structured information is stored in memory, so the system can use it later in the conversation, or even in future chats with the same user.
If the user asks a new question, the system uses the dialog state and structured memory to give better answers. For example, if it already knows the user’s laptop model, it won’t ask again. If it knows the user was not satisfied with the last answer, it can try a different approach. This makes the whole experience smoother and more helpful.
The patent also covers the way the system is put together. It can run on a computer, server, or even a phone, as long as there’s a processor and memory. The software instructions are stored so they can be run on demand, and the system can be updated as better models or trees are built.
What makes this invention stand out is how it brings together several advanced ideas:
– It uses deep language models to understand both questions and answers, making the system better at handling real conversations.
– It chooses the best path through a decision tree using similarity scores, not just fixed rules.
– It remembers the whole dialog, so it can build context and give more personal, helpful answers.
– It learns from user feedback, tracking satisfaction and adjusting its answers or questions as needed.
– It can be set up on many kinds of devices and updated over time.
This means companies can use the system to help customers more quickly, doctors can guide patients through symptoms more carefully, teachers can answer student questions more clearly, and businesses can share knowledge more smoothly. The system gets smarter with use, remembers what worked, and tries to avoid making the same mistakes.
Conclusion
The patent application for this decision tree-based question answering system marks a big step forward for how computers can help people find answers. By mixing the strengths of decision trees, natural language understanding, and feedback from users, the system can give answers that make sense, fit the context, and keep getting better. As businesses and users look for faster, friendlier, and more reliable help, inventions like this will shape the future of smart assistants and support systems. The key is not just in the technology, but in making sure the computer really listens, learns, and responds like a helpful guide.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217667.