Invented by HOU; Xirui, ZHANG; Zhuqing, MEI; Gang, Capital One Services, LLC
Chatbots are everywhere, and getting them to truly understand what we mean is hard. A new patent application sets out a clever way to help chatbots learn intent using fewer labeled conversations. In this article, we break down the big ideas, why they matter, and how this new system works, using simple words and clear examples.


Background and Market Context
Chatbots are now a part of daily life. They help us with online shopping, answer questions, and guide us through websites and apps. Companies want their chatbots to understand people better, because happy users are more likely to buy things or keep using a service. But teaching a chatbot to “get” what someone wants—known as intent recognition—is tricky. This task usually needs a lot of labeled data, which means humans must look at tons of real conversations and mark what the user wanted. That takes time, money, and lots of skilled workers.
The market for smarter chatbots is huge. Businesses save money when bots handle common questions, and customers get faster help. But when a chatbot misunderstands, it can upset users and hurt the company’s reputation. So, companies want bots that need less labeled data but still understand people well, especially as new products and services come out and chat conversations change.
Right now, many chatbots use big language models trained on massive text data from the internet. These models are great at general language tasks. However, they often struggle with the specialized jobs needed for a company’s own chat data, because their training data is different from the real chat logs. Also, most businesses only have a small set of labeled chats, with lots of unlabeled ones piling up every day. This makes the job of intent recognition both important and challenging.

The need for better ways to use both labeled and unlabeled chat data is clear. If bots can learn more from less, using smarter techniques, businesses win. Users get better answers, and companies can roll out new bots without waiting for thousands of conversations to be labeled by hand. That’s where the system described in this patent comes in—it aims to solve these problems in a fresh way.
Scientific Rationale and Prior Art
To understand the invention, let’s start with how chatbots usually learn. Many rely on machine learning, where the system looks at conversations with labels (like “pay bill” or “report fraud”) and learns patterns. The more examples it gets, the better it gets at guessing intent in new chats. But, with only a small set of labeled chats and many unlabeled ones, the old ways don’t work as well.
Earlier methods often use pre-trained models, like word2vec or transformers (such as BERT or GPT), to turn words or sentences into numbers called embeddings. These models are trained on unrelated data, so they learn broad, generic rules about language. When you give them a company’s chat data, they put all the chats into a “coarse” space—think of it as a rough map where similar texts are close, but not close enough for fine-grained jobs like intent recognition. The coarse space is good for general meaning but not very precise for a company’s special needs.
Some researchers tried to fix this by building custom models just for their data, but training a new model from scratch takes lots of labeled examples. Others tried to “fine-tune” big models, but again, they need labeled data and lots of computing power. Semi-supervised learning, where the system tries to learn from both labeled and unlabeled data, is one way to help. In these methods, the system uses what it knows to guess labels for the unlabeled data, then uses these guesses to improve itself. However, the guesses can be wrong, and mistakes can pile up if the system is not careful.
Contrastive learning is a newer idea. Instead of only trying to group similar things together, it focuses on both pulling similar examples close and pushing different ones apart. Imagine you have three chat messages: one is the “anchor,” one is very similar (maybe a rewording), and one is very different (maybe a different intent). The system learns by making sure the anchor and its match are close, while the different one is far away. This helps the system focus on what really matters for the task. Until now, this idea was not widely applied to chatbots and intent recognition, especially for the problem of spreading labels from a small labeled set to a large unlabeled set.

The new patent builds on these ideas. It starts with a pre-trained model to get a rough map (coarse representation). Then, it uses contrastive learning to make a better, “fine-grained” map just for the chatbot’s data. This fine-grained space lets the system guess the right intents for unlabeled chats much more accurately. The key is how the system selects which chat examples to push apart or pull together, and how it spreads labels in this new space. This approach is different from older methods that only used coarse spaces or needed lots of labeled data for fine-tuning.
Invention Description and Key Innovations
This invention is a new system for helping chatbots understand user intent. It does this by building a better map of chat data, making it easier to spread intent labels from a small labeled set to many unlabeled chats. Let’s walk through how it works in simple steps.
Step 1: Getting the Data
The system starts with a dataset of chat conversations. Some chats are labeled with user intent (like “check balance”), and most are not. These labeled and unlabeled chats are the raw material for the system.
Step 2: Making a Coarse Map with a Pre-Trained Model


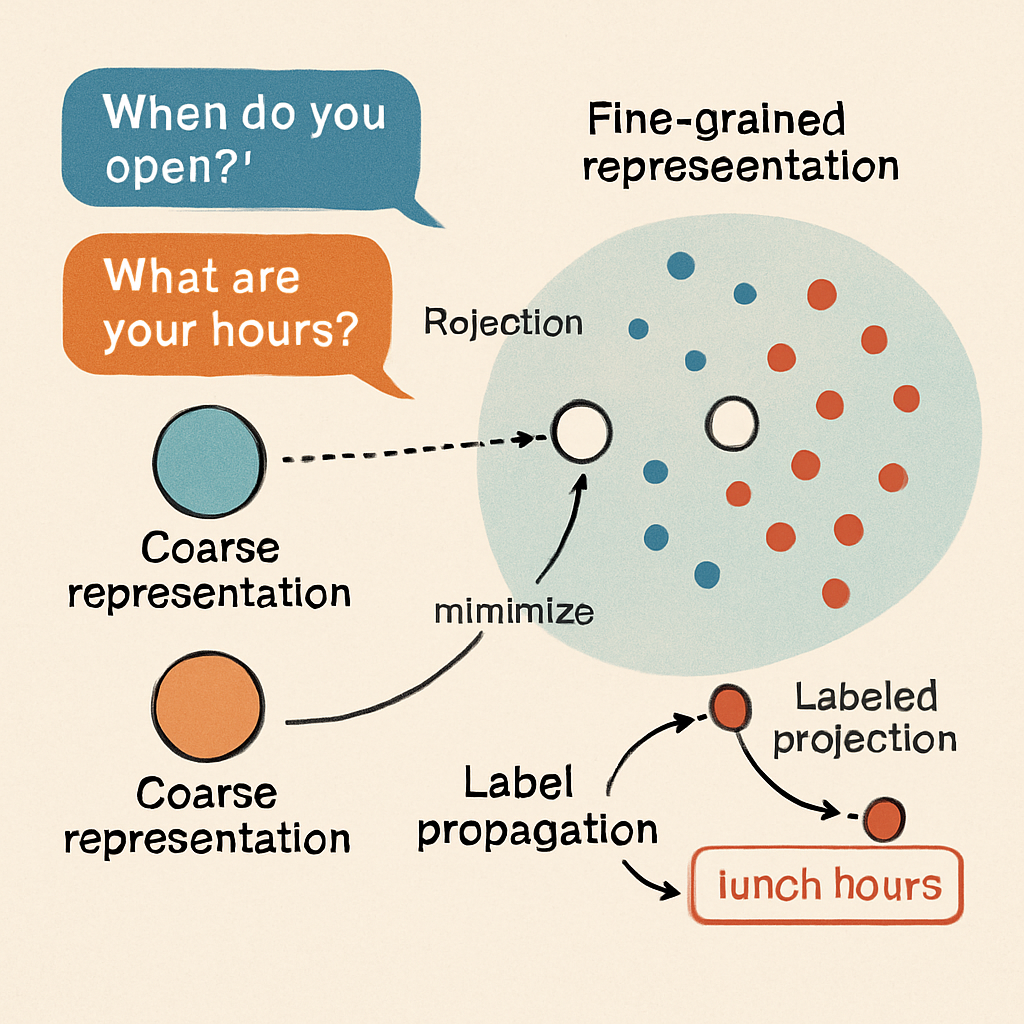
The system uses a pre-trained language model (like BERT, GPT, or word2vec) to turn each chat message into a set of numbers—a point in space. This is called a “coarse representation” because the pre-trained model was trained on unrelated data, so the map is rough and only captures general language features. All the chats are plotted in this space, and similar messages are closer together, but not close enough for the company’s special needs.
Step 3: Selecting Anchor, Similar, and Dissimilar Points
The system picks certain labeled chats as “anchor points.” For each anchor, it finds chats with the same label—these are “similar points.” It also finds chats with different labels—these are “dissimilar points.” The system may pick the most typical chats as anchors, the closest matches as similar points, and the most different as dissimilar points. Sometimes, it makes new similar points by changing the anchor chat a little (like swapping words or using synonyms).
Step 4: Training the Contrastive Learning Projection
This is where the magic happens. The system uses contrastive learning to adjust the map. It trains a projection that pulls the anchor and similar points closer (down to a small margin) and pushes the anchor and dissimilar points farther apart (up to a big margin). This creates a new “fine-grained representation”—a much better map for intent recognition. The space is now stretched out so that chats with the same intent are clustered, and different intents are far apart.
Step 5: Projecting Unlabeled Chats into the Fine-Grained Space
Now the system takes the unlabeled chats and puts them into this new fine-grained space, using the same projection it learned in the last step. Each unlabeled chat gets a new position on the map, and this position is much more meaningful for intent recognition.
Step 6: Propagating Labels with a Similarity Metric
For each unlabeled chat, the system looks at its neighbors in the fine-grained space. If it is close to many chats labeled “report fraud,” it will likely get that label. The system can use simple math (like Euclidean distance) to find the nearest labeled chats. It spreads labels from the labeled projections to the unlabeled ones, filling in the blanks across the dataset. This process can repeat, as newly labeled chats help label others.
Other Smart Features
The system can use different pre-trained models, like word2vec or transformers, and select points using cosine similarity or dot products from attention mechanisms. It can also create new data points by tweaking sentences (swap words, remove words, or use synonyms). The system uses special rules to pick the hardest similar and dissimilar points, making training stronger. It can build fast search structures to look up neighbors and can filter out chats that seem to get inconsistent labels, cleaning up the data as it goes.
What Makes This Invention Stand Out?
The big innovation is how the system builds a fine-grained map using contrastive learning, even with very few labeled chats. It stretches out the data space so that intent labels are easy to spread, making label propagation much more accurate. It works with many types of pre-trained models and uses smart ways to pick which chats to compare during training. It can even spot and remove bad data as it labels new chats. This means companies can train chatbots faster, with less labeled data, and get better intent recognition right away.
Conclusion
This new patent outlines a simple yet powerful way for chatbots to get smarter at understanding what users want. By starting with a rough map from a pre-trained model and then fine-tuning it with contrastive learning, the system can accurately spread intent labels, even when labeled data is scarce. The approach is flexible, works with many types of models, and helps businesses roll out smart, responsive chatbots with less effort. As chatbots continue to grow in importance, tools like this will play a big role in making them more helpful, more reliable, and much easier to build and maintain. The future of chatbot intent recognition looks brighter and easier, thanks to innovations like these.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217602.