Invented by Funda Gunes, Wendy Ann Czika, Susan Edwards Haller, Udo Sglavo, SAS Institute Inc
Machine learning has revolutionized various industries by enabling computers to learn from data and make accurate predictions or decisions. However, building an effective machine learning model requires careful consideration of both feature selection and hyperparameter optimization. These two tasks play a crucial role in determining the model’s performance and generalization capabilities.
Feature selection involves identifying the most relevant features from a given dataset, while hyperparameter optimization focuses on finding the optimal values for the model’s hyperparameters. Traditionally, these tasks have been performed manually, requiring extensive domain knowledge and time-consuming trial and error processes. However, with the advancements in technology, the market for systems that automate simultaneous feature selection and hyperparameter optimization has been rapidly growing.
One of the key players in this market is the development of intelligent algorithms and frameworks that can automatically handle both feature selection and hyperparameter optimization. These systems leverage the power of machine learning itself to automate the tedious and error-prone tasks involved in building a robust model. By doing so, they not only save time and effort but also improve the model’s performance by selecting the most relevant features and fine-tuning hyperparameters.
The market for these systems is driven by the increasing demand for efficient and accurate machine learning models across various industries such as healthcare, finance, marketing, and manufacturing. In healthcare, for example, accurate prediction models can help diagnose diseases, predict patient outcomes, and personalize treatment plans. Similarly, in finance, these models can assist in predicting stock prices, detecting fraud, and optimizing investment strategies.
The benefits of using systems for automatic simultaneous feature selection and hyperparameter optimization are numerous. Firstly, they eliminate the need for manual feature selection, which can be a time-consuming and error-prone process. These systems can automatically identify the most relevant features from a given dataset, reducing the risk of including irrelevant or redundant information in the model.
Secondly, these systems optimize the model’s hyperparameters, which are crucial for achieving the best performance. Hyperparameters, such as learning rate, regularization strength, or the number of hidden layers in a neural network, significantly impact the model’s ability to generalize and make accurate predictions. By automatically fine-tuning these hyperparameters, these systems ensure that the model is optimized for the specific task at hand.
Furthermore, these systems often employ advanced optimization algorithms, such as genetic algorithms, particle swarm optimization, or Bayesian optimization, to efficiently explore the vast search space of possible feature combinations and hyperparameter values. This enables them to find near-optimal solutions in a reasonable amount of time, even for complex and high-dimensional datasets.
The market for systems for automatic simultaneous feature selection and hyperparameter optimization is expected to grow significantly in the coming years. As more industries realize the potential of machine learning and the importance of building accurate models, the demand for these systems will continue to rise. Additionally, advancements in artificial intelligence and computational power will further enhance the capabilities of these systems, allowing them to handle even larger and more complex datasets.
In conclusion, the market for systems that automate simultaneous feature selection and hyperparameter optimization for machine learning models is witnessing rapid growth. These systems offer numerous benefits, including time and effort savings, improved model performance, and efficient exploration of the search space. As industries increasingly rely on accurate machine learning models, the demand for these systems will continue to rise, driving further innovation and advancements in the field.


The SAS Institute Inc invention works as follows
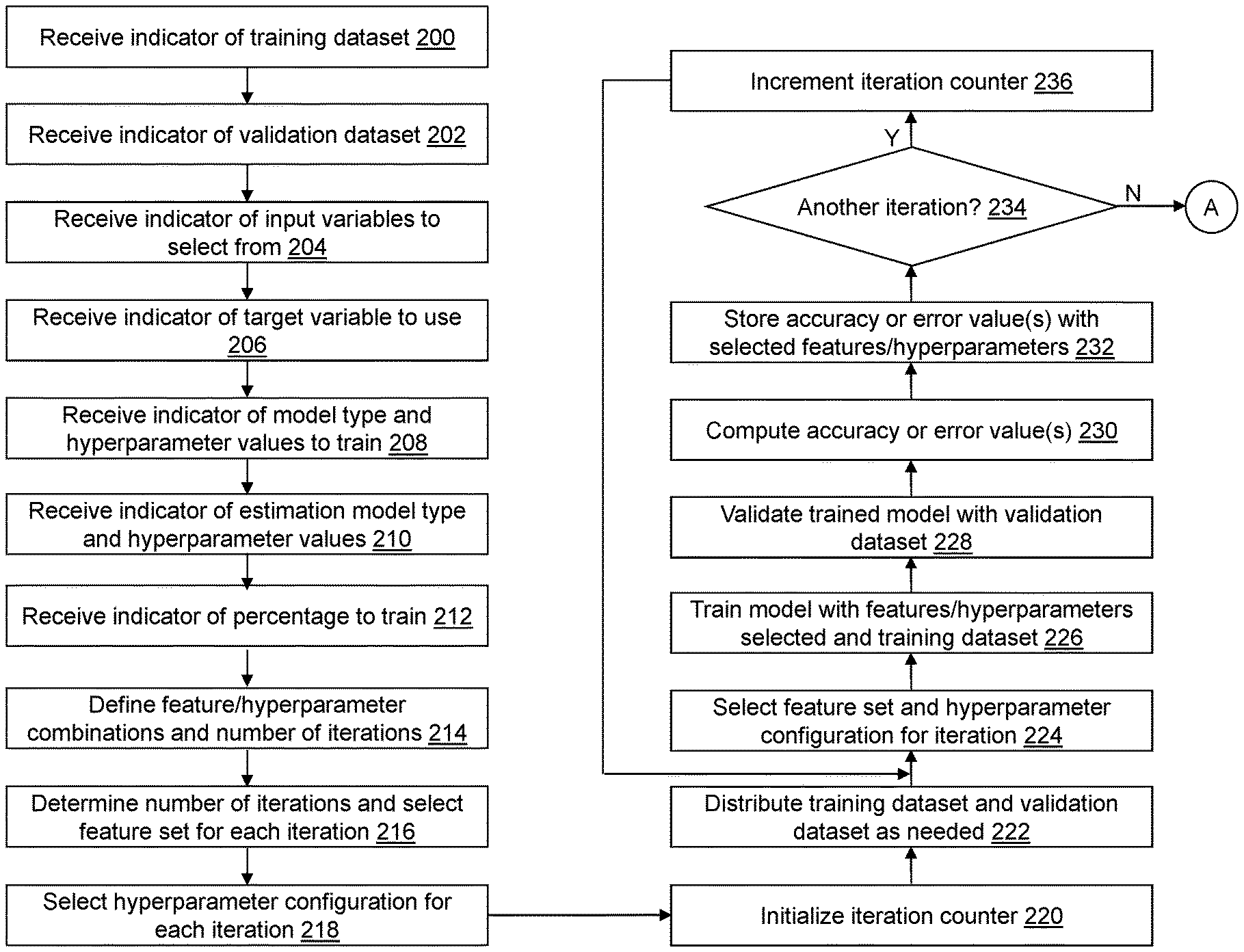
A computing device chooses a feature-set and hyperparameters to create a machine learning algorithm that predicts the value of a characteristic from a scoring dataset. The number of iterations for the training model is determined. Each iteration is assigned a unique evaluation pair that includes a feature set chosen from feature sets, and a hyperparameter configured selected from hyperparameter settings. Each unique evaluation pair is used to train a machine learning model. Validation of each machine learning model trained is done by computing a performance measurement value. The hyperparameter configuration and performance measure value for each unique evaluation pair are used to train an estimation model. The trained estimation is then executed to calculate the performance measure value of each unique evaluation pair. The computed performance value is used to select a final feature set, and a final configuration of hyperparameters.


Background for System for automatic simultaneous feature selection and hyperparameter optimization for a machine-learning model
Training machine learning models that are accurate involves two challenges. First, you need to select a set of good input variables for the model. This is done using feature selection, feature extraction and feature engineering. Retraining the model is the best way to determine whether a set of candidate features improves prediction accuracy. Second, you must choose the hyperparameters that will be used to train your model. The choice of hyperparameters and feature sets has a huge impact on the accuracy of the model. Both tasks are difficult and expensive to compute because they require the training of multiple models in high-dimensional space.
In one embodiment, there is a nontransitory computer-readable media having computer-readable instructions stored on it that, when a computing device executes them, causes the computing device select a hyperparameters and a feature set for a machine-learning model to predict values for a characteristic of a second dataset. There are defined a plurality of feature set inputs to be evaluated by a machine-learning model. Each of the feature sets in the plurality uniquely identifies a plurality variables. Each of the plurality variables is a subset from a second plurality variables included in an output dataset. There are a plurality of hyperparameters configurations that can be evaluated as input to the machine-learning model. Each hyperparameter setting of the plurality hyperparameter settings indicates a value of each hyperparameter from a plurality hyperparameters that are associated with the model type of the model learning model. Each hyperparameter of the plurality is unique. The number of iterations of the training model is determined by a combination of the number of feature sets defined and the number of hyperparameters configurations defined. Each of the predetermined number of iterations of the training model is evaluated using a unique pair of evaluations. Each evaluation pair specifies a feature selection from the plurality defined of feature sets, and a hyperparameter setting from the plurality defined of hyperparameter settings. The feature set of a unique evaluation pair is used to select a current feature set. The hyperparameters of the unique pair of evaluations selected for the current number is used to select a current configuration. The selected current feature set is used to select features from a dataset for training a machine learning model. The validated machine learning model is computed by using features from a validation data set based on selected current feature sets and selected current hyperparameter settings. (e) Both the computed performance measurement value and the indicator of the current feature set selected and the current hyperparameter configured are stored. The current number of iterations is increased. The steps (a) through (f) will be repeated until the training model has undergone all of its iterations. The feature set, hyperparameter configuration and performance measure value for each iteration are used to train an estimation model. The trained estimation is used to calculate the performance measure values for each feature of the defined number of feature sets, in conjunction with each hyperparameter of the defined number of hyperparameter combinations. The computed performance value is used to select a final feature set and final hyperparameter. The final feature set and hyperparameter configuration selected are output in order to predict the value of a characteristic for a new observation.
In another example embodiment a computing device has been provided. The computing device may include, but not be limited to, an operating processor, and a nontransitory computer-readable media operably coupled with the processor. The computer-readable media has stored instructions that, when executed, cause the computing devices to select a feature and hyperparameters of a machine learning to predict the value for a particular characteristic in a secondary dataset.
In yet another example embodiment, the method for selecting a feature-set and hyperparameters to be used in a machine-learning model that predicts a value of a characteristic from a second dataset has been provided.
The following drawings, detailed description and appended claims will reveal other principal features to those who are skilled in the arts.
A feature engineering goal is to give a machine-learning model a set of good features to train from. Better features lead to simpler models and better prediction accuracy. Feature engineering involves a variety of techniques including feature selection and extraction, as well as feature derivation. It is computationally expensive to search through all feature engineering techniques, especially when a dataset contains a lot of features.
Hyperparameter tuning aims to find the best hyperparameters for a machine-learning algorithm that is used to train a machine-learning model. The hyperparameters in most machine learning algorithms are many. They include regularization parameters and stochastic gradient descent (such as momentum and learning rate) as well as algorithm-specific parameters like a maximum tree depth and subsampling rates for a machine learning model based on a decision tree. Regularization parameters, stochastic descent parameters (such learning rate and acceleration), as well other algorithm-specific parameter, are all referred to as “hyperparameters” here. Hyperparameters are parameters that a user defines to control the execution of a prediction model. These include model types like a neural network, gradient boosting trees, decision trees, forest models, support vector machines, etc. The type of predictive models is reflected in the hyperparameters used.
The hyperparameters are important for the accuracy of the models. There is no default value that applies to all datasets. Manual tuning is a traditional method of performing hyperparameter searches. Manual tuning, however, is less likely than other methods to produce an optimal solution. Grid search is another technique that’s commonly used. It involves trying out all the possible hyperparameter values and selecting the set of parameters with the minimum prediction error. Performance measure values can be used to describe the minimum prediction error or maximum accuracy measure. Grid search can, however, become computationally unfeasible as the number hyperparameters increase.
Referring to FIG. A block diagram of the model training device 100 according to an example embodiment is shown on Figure 1. Model training device may consist of an input interface, an output, a communication, non-transitory medium, a processor, a parameter selection app, a dataset, validation dataset, model and feature description, and an application for parameter selection. Model training device 100 may include fewer, different and/or more components.
Parameter Selection Application 122″ automatically combines feature selection with hyperparameter tuning in supervised machine-learning algorithms that are used to train various types of models. Randomly select a fraction (e.g.?5%) from a total combination of pairs of hyperparameter configurations and feature sets. Each pair of selected feature sets and configurations of hyperparameters is used to train a model for the selected model type using training dataset 124. Validation datasets 126 are used to calculate a prediction error or accuracy value for each model. The prediction accuracy or error value for a model type of the remaining pairs are estimated by using a selected estimate model that has been trained with the computed value. The final trained model is the trained model with its feature set and hyperparameters that results in the highest prediction accuracy or lowest error value. This model will be used to predict or characterize a value of an observation vector within a second dataset (shown in FIG. 3).


As understood by those of skill in the art, “Input Interface 102” provides an interface to receive information from the user or other device for entry into the model training device 100. Input interfaces 102 can interface with a variety of input technologies, including but not limited to a keyboard 112, microphone 113 and a mouse 114. They may also interface with a trackball, keypad, a keypad or a keypad. The user can enter data into the model training device 100, or make selections in an interface on display 116. Input interface 102 as well as output interface 104 can be supported by the same interface. Display 116, which is a touchscreen display, can be used to receive input from the user and present output. Model training device 100 can have multiple input interfaces, which may use the same input interface technology or another input interface. Model training device 100 may also be able to access the input interface technology through communication interface 106.
Output Interface 104 provides a means to output information that can be used by an application or device, and/or reviewed by the user of Model Training Device 100. Output interface 104, for example, may interface with a variety of output technologies, including but not limited, to a display 116 and a speaker 118. It could also interface with a printer 120. Model training device 100 can have multiple output interfaces, which may use different or the same output interface technology. Model training device 100 may also be able to access the output interface technology through communication interface 106.
Communication interface 106 is an interface that allows devices to receive and transmit data using different protocols, transmission technologies and media, as defined by experts in the field. Communication interface 106 can support communication via various transmission media, which may be wireless or wired. Model training device 100 can have one or multiple communication interfaces using the same communication interface technology or a different communication communication interface. Model training device 100, for example, may be able to communicate using an Ethernet port or a Bluetooth antenna. It could also support communication via a telephone jack or USB port. Communication interface 106 can be used to transfer data and messages between model training devices 100 and other computing devices of a distributed computer system 128.
Computer readable medium 108″ is an electronic storage place for information that can be accessed and used by processor 110, as those in the know understand. Computer-readable media 108 includes, but isn’t limited to, random access memory (RAM), read only memory(ROM), flash memory etc. Magnetic storage devices, such as hard disks, floppy discs, magnetic strips and other magnetic storage media, are also available. . . ), optical disks (e.g., compact disc (CD), digital versatile disc (DVD), . . . ), smart cards, flash memory devices, etc. Model training device 100 can have one or multiple computer-readable media using the same memory media technology or a different memory medium technology. Computer-readable mediums 108, for example, may contain different types of computer readable media which may be organized in a hierarchical manner to allow efficient access to data as understood by someone skilled in the art. A cache, for example, may be implemented within a faster, smaller memory to store copies of the data from frequently/recently-accessed memory locations in order to reduce access latency. The model training device 100 may also have one or multiple drives to support the loading of memory media, such as CDs, DVDs, external hard drives, etc. Model training device 100 can be connected with one or more external hard disks using the communication interface 106.
Processors 110 execute instructions understood by those with knowledge of the art. Instructions may be executed by logic circuits or hardware circuits. Processor 110 can be implemented as hardware or firmware. Processor 110 performs or controls the instructions that are contained in an instruction. Execution is the term used to describe the process of running an application or performing operations as directed by an instruction. The term?execution’ refers to the execution of an application, or the action required by an instruction. Instructions can be written in a programming language, scripting, assembly language or other languages. The processor 110 is operably coupled with input interfaces 102, output interfaces 104, communication interfaces 106 and computer-readable media 108 in order to receive, send and process information. Processor 110 can retrieve a series of instructions from permanent memory and copy them in executable form into a temporary memory, which is usually some form of RAM. Model training device 100 can include multiple processors using the same processing technology or different technologies. Model training device 100, for instance, may include a number of processors which support parallel processing using, for example a plurality threads.
Parameter Selection Application 122 performs operations related to defining model and feature sets description 128 using data stored in Training dataset 124. Model and feature sets description 128 can be used to classify data, predict data and/or monitor data from second dataset 324. Predicted or classified dates may be stored as a predicted dataset (shown in FIG. The third embodiment enables various data analysis functions and alert/messaging relating to monitored data. The parameter selection application 122 may embody some or all of these operations. The operations can be implemented by hardware, software or firmware.
The parameter selection application 122 can be integrated with other systems processing tools in order to process data automatically generated by an enterprise, device or system. It will identify outliers, monitor data changes, and provide warnings and alerts associated with monitored data. This is done using the input interface 102 and output interface 104 and/or the communication interface 106, so that the appropriate actions can be taken in response to the monitored changes.
Parameter Selection Application 122″ may be implemented as an Internet application. Parameter selection application 122, for example, may be configured to receive responses to hypertext transport protocol requests and to send HTTP request. HTTP responses can include web pages, such as HTML documents and linked items generated in response HTTP requests. The URL of each web page can include the address or location of the computer device that contains the resources to be accessed, as well as the location of that resource. The type of resource or file depends on the Internet protocol used, such as HTTP, H.323, file transfer protocol etc. The file accessed can be a text file, a picture file, a sound file, a video, a Java applet or an XML file.
Training datasets 124 and validation data sets 126 can be partitioned with or without replacing an input dataset, for example based on the selection of a percentage of the input dataset to allocate to training datasets 124 for use in training the model, with the remainder allocated to validation data sets 126 for validation of the performance of the trained models. A user may select a cross-validation option or use another technique to determine training datasets 124 and 126 from an input dataset. Each training dataset 124 or validation dataset 126 may, for example include a number of rows and columns. The rows can be called observation vectors (observations) and the columns variables or features. Transposition of the training dataset 124 and validation data set 126 is possible. The plurality variables vi can define multiple dimensions in each observation vector for training dataset 124 or validation dataset 126. A vector of observation xi can include values for the variables vi that are associated with an observation i. . . , NT where NT is the number of observations within training dataset 124. A vector of observations xvi can include values for the multiple variables associated with an observation i. . . “, NV where NV is the number of observations from validation dataset 126.
Each of the multiple variables vi can describe a particular characteristic of an object. If the input dataset contains data related to the operation of a car, for example, the variables could include an oil-pressure, a speed indicator, a fuel tank level, tire pressures, engine temperatures, radiator levels, etc. The input dataset can include data that is captured over time and relates to one or more objects. Each observation vector xi contains observation vector values of oi,j where j=1. . . Nf = 1 and i=1 . . , N. Where Nf is the number of variables that are present in each observation vector of the input dataset, though some may be missing. Each observation vector xi has a value of the target variable yi associated with it, where i=1. . . NT or i=1, . . , NV. It is possible to use less than all the columns in the input dataset as variables for each observation vector xi, or the target variable value yi that are used to describe the model and feature set description 128, but not all the columns. The input dataset can include more than Nf columns.


Click here to view the patent on Google Patents.