Invented by Venkataraman Viswanathan, Accenture Global Solutions Ltd
Structured data refers to information that is organized and easily searchable, such as data stored in databases or spreadsheets. On the other hand, unstructured data refers to information that is not organized in a predefined manner, such as text documents, images, videos, or social media posts. Both types of data are valuable sources of information, but analyzing unstructured data can be more challenging due to its complexity and lack of organization.
Ensemble machine learning techniques have proven to be effective in handling both structured and unstructured data. By combining multiple models, ensemble methods can capture different aspects of the data and provide more accurate predictions. This is particularly useful when dealing with unstructured data, where traditional machine learning algorithms may struggle to extract meaningful insights.
One popular ensemble technique is the random forest algorithm, which combines multiple decision trees to make predictions. Each decision tree is trained on a different subset of the data, and the final prediction is determined by aggregating the predictions of all the trees. This approach is effective in handling structured data, as it can capture complex relationships and interactions between variables.
For unstructured data, ensemble methods like bagging and boosting are commonly used. Bagging involves training multiple models on different subsets of the data and averaging their predictions. This helps to reduce the impact of noise and outliers in the data, improving the overall accuracy. Boosting, on the other hand, focuses on iteratively training models that are weighted based on their performance. This allows the ensemble to prioritize the models that perform well on specific subsets of the data, leading to better predictions.
The market for ensemble machine learning for structured and unstructured data is driven by several factors. Firstly, the increasing volume and complexity of data generated by organizations require more sophisticated techniques for analysis. Ensemble methods offer a solution by leveraging the power of multiple models to handle diverse data sources and extract valuable insights.
Secondly, the demand for accurate predictions and decision-making is growing across industries. Whether it is predicting customer behavior, detecting fraud, or optimizing supply chain operations, organizations need reliable tools to make informed decisions. Ensemble machine learning provides a robust framework for improving prediction accuracy and reducing errors.
Furthermore, advancements in technology and computing power have made ensemble methods more accessible and efficient. With the availability of powerful hardware and scalable algorithms, organizations can implement ensemble machine learning techniques on large datasets in a reasonable amount of time.
In conclusion, the market for ensemble machine learning for structured and unstructured data is expanding rapidly as organizations recognize the value of combining multiple models for improved accuracy and reliability. With the ability to handle both structured and unstructured data, ensemble methods offer a versatile solution for data analysis and decision-making. As the volume and complexity of data continue to grow, the demand for ensemble machine learning is expected to increase, driving further innovation and development in this field.

The Accenture Global Solutions Ltd invention works as follows
A machine-learning system includes a subsystem for processing data sets to store data from multiple sources.” A data search function and an ensemble machine learning subsystem can execute queries to identify related structured and non-structured data in the stored data objects. “The structured and unstructured information can be used to create new objects.

Background for Ensemble Machine Learning for Structured and Unstructured Data
Machine Learning evolved from the study and computation of learning theory in artificial Intelligence. Machine learning is the study and creation of algorithms which can make predictions and learn from data. These algorithms work by creating a machine-implemented algorithm from inputs to make data-driven decisions or predictions rather than strictly following static program instructions.
Unsupervised learning is a way to solve problems without knowing what the results will be. No training data is available, so there is no feedback on the results of predictions. Unsupervised learning allows relationships between variables to be established in order to make predictions.
BRIEF DESCRIPTION DES DRAWINGS
The following text describes in detail the embodiments and examples with reference to the figures. In the figures, similar reference numbers indicate similar elements.
FIG. “FIG.
FIG. “FIG.
FIG. “FIG.
FIGS. “FIGS.
FIG. “FIG.
FIGS. “FIGS. 6-10 are examples of screenshots generated by the graphical user interface of machine learning systems.

For the sake of simplicity and illustration, the principles are explained by using examples. To help you understand the examples, we have provided a number of specific details in the description. To a person of ordinary skill, it will be obvious that these examples can be used without any limitation. Some well-known methods or structures haven’t been described in full to avoid unnecessarily obscuring the examples. The examples can be combined in many different ways.
According to examples in the present disclosure, a mixture of unsupervised and supervising machine learning is used for query execution as well as for determining similarity and making predictions using a set documents. In a first stage, for example, unsupervised learning could be used to run a query against a corpus. The words used in the query may not appear in the index for the set of documents that are being searched. This is a technical issue. A searcher might be looking for a concept that can be described by words not included in the index. Words may also have multiple meanings, so a word match may be unable to match the concept searched. A search on the basis of concept could return irrelevant documents or words that have multiple meanings.
Accordingly, according to an example in the present disclosure, machine learning functions of natural language processing can be used, in a preliminary phase, to search for a collection of documents. The Latent Semantic Indexing (LSI), which is a form of semantic indexing, can be used to establish relationships between a set of documents and their terms. The set of documents is analyzed to determine the concepts and terms that are used in them. A matrix of data on term-document associations is then created. LSI involves applying the singular-value data decomposition (SVD), to the matrix of association data between documents and terms. The terms and documents in the matrix can be used to construct a semantic space. SVD clusters documents that have been determined to be related based on patterns. In order to execute a search, terms from a query may be used to identify a specific point in the space and documents within a certain distance are then retrieved. In the first phase of the search, the unstructured text within the set documents can be searched using the query in order to retrieve documents that are most similar (e.g. closest in the space semantic). LSI can be used to reduce dimensionality in a set points of the semantic space, and then used to search a set documents for matches. The natural language processing can be repeated each time new documents arrive that will be added to the set of documents being searched. Searches can also be performed on the unstructured texts of the documents in order to identify matches.
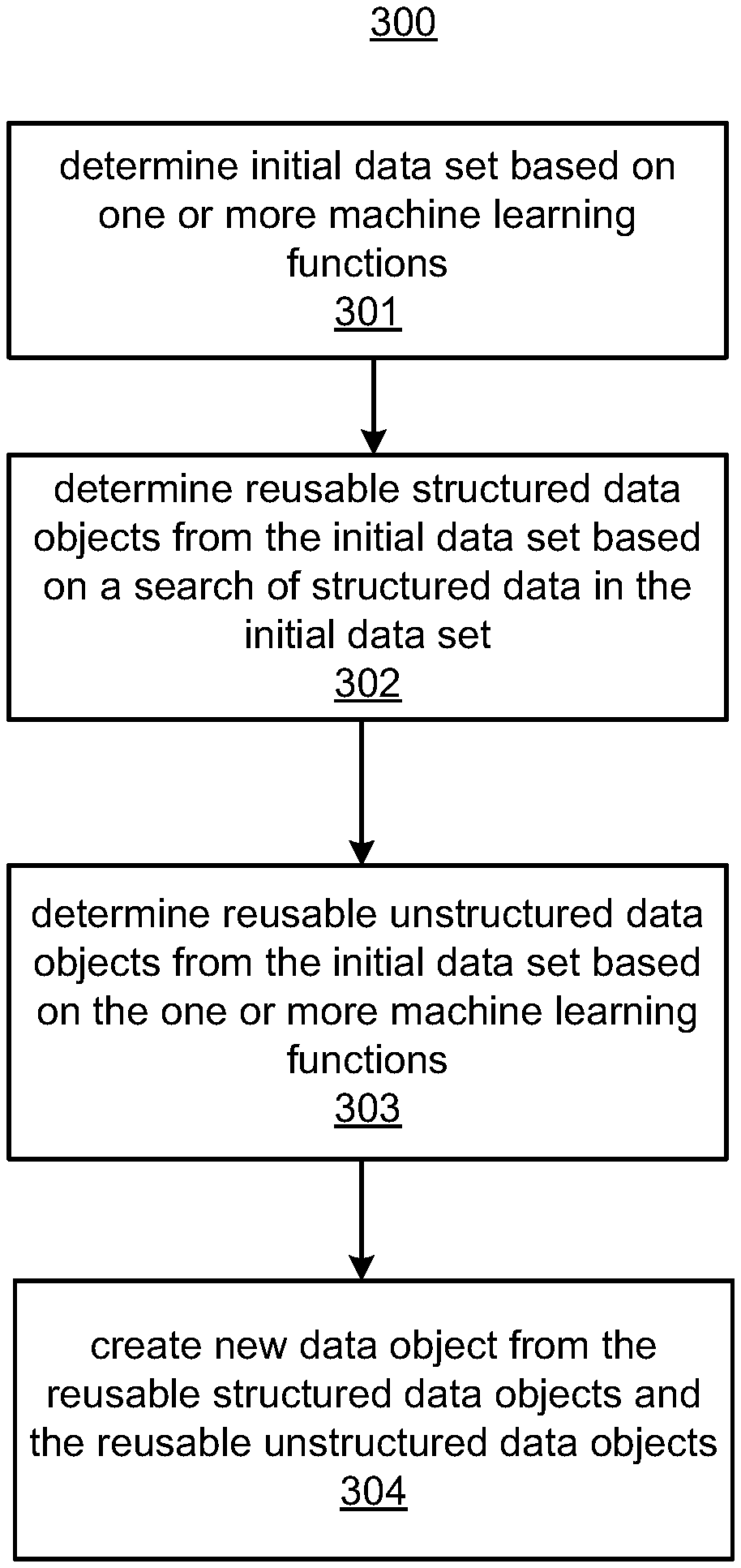
In an example, natural language processing can be used in the first stage to search for a collection of documents and create a new one. The query used to search the documents set in the first phase, for example, may include terms that relate to the type and content of the new document being created.
The fields that were identified in the second stage may be reusable items which can be used to create new documents based on queries executed in the initial phase. One or more fields identified in the second phase may be included in a newly created document.
In a third stage, machine learning under supervision may be used to identify matches between unstructured data and the documents that were matched in the first phase. A training set can be generated in order to train a classification algorithm to classify unstructured data. The training set can include sentences that are composed of a list words and labels. According to an example from the present disclosure, a supervised machine-learning function may iterate the sentences twice. In the first iteration the vocabulary of the sentences is acquired. In a subsequent iteration the classifier will be trained. The training set can be used to generate vector representations for each word or label. After the classifier has been trained, it can classify unstructured data according to the categories in the training set (e.g. labels). As an example, what is the “distributed bag of words”? In an example, the ‘distributed memory? “(dbow) Machine learning functions can be used.
In the third phase of the process, unstructured information from the matching documents identified in the first stage may be searched for unstructured information belonging to a specific category. These unstructured data can be used in the creation of a new document along with the reusable objects that were identified in the second stage. “In an example, the reusable objects determined in the second phase are categories, and the unstructured data that the classifier determines belongs to the category is included in a new document created.
An accuracy problem with machine learning can be a technical issue. False predictions by a machine-learning function can negatively impact the use of that function in its application. A system, according to an example in the present disclosure, may use a machine learning ensemble function that can improve prediction performance. The ensemble machine-learning function, for example, includes supervised and unsupervised machine learning functions. The ensemble machine-learning function can determine whether structured and unstructured documents have similar data. The ensemble machine learning function can generate a new document based on similarities and predictions.
FIG. According to one embodiment, Figure 1 shows a machine-learning system 100. A data set processor subsystem 102 processes the data from data sources a-n. The data set subsystem 102 can perform translations for structured data from the data source 101 a-n. The data source 101 a – n may provide unstructured information to the data set subsystem 102.
Click here to view the patent on Google Patents.