Invented by Shaorong Chong, Winston X. Yan, David A. Scott, David R. Cheng, Pratyusha Hunnewell, Arbor Biotechnologies Inc
The Crispr market is divided into two main categories: enzymes and systems. Enzymes are the key components of the Crispr system and are responsible for cutting and modifying DNA. The most commonly used enzymes in Crispr are Cas9 and Cas12a. These enzymes are highly specific and can be programmed to target specific genes within an organism’s DNA. Systems, on the other hand, are the tools and technologies used to deliver the enzymes to the target cells. These systems include viral vectors, nanoparticles, and electroporation.
The market for Crispr enzymes is expected to grow at a CAGR of 22.3% from 2020 to 2025. The increasing demand for gene therapy and the development of new drugs are the key drivers of this growth. Gene therapy is a promising field that aims to cure genetic diseases by replacing or modifying faulty genes. Crispr enzymes are the key tools used in gene therapy, and their increasing availability and affordability are driving the growth of the market.
The market for Crispr systems is also growing rapidly, with a CAGR of 20.8% from 2020 to 2025. The increasing demand for genetically modified crops and the development of new gene therapies are the key drivers of this growth. Genetically modified crops are designed to be more resistant to pests and diseases, and Crispr systems are the key tools used in their development. The increasing demand for gene therapy is also driving the growth of the Crispr systems market, as these systems are used to deliver the Crispr enzymes to the target cells.
North America is the largest market for Crispr DNA targeting systems enzymes and systems, followed by Europe and Asia-Pacific. The increasing investment in research and development, the presence of key players, and the favorable regulatory environment are the key factors driving the growth of the market in North America. Europe is also a significant market for Crispr, with the increasing demand for gene therapy and the development of new drugs driving the growth of the market. Asia-Pacific is expected to be the fastest-growing market for Crispr, with the increasing investment in research and development and the growing demand for genetically modified crops driving the growth of the market.
In conclusion, the market for Crispr DNA targeting systems enzymes and systems is rapidly growing and is expected to reach a value of $10.55 billion by 2025. The increasing demand for gene therapy, the development of new drugs, and genetically modified crops are the key drivers of this growth. North America is the largest market for Crispr, followed by Europe and Asia-Pacific. The future of Crispr is bright, and it has the potential to revolutionize the way we treat genetic diseases, develop new drugs, and even create genetically modified crops.

The Arbor Biotechnologies Inc invention works as follows
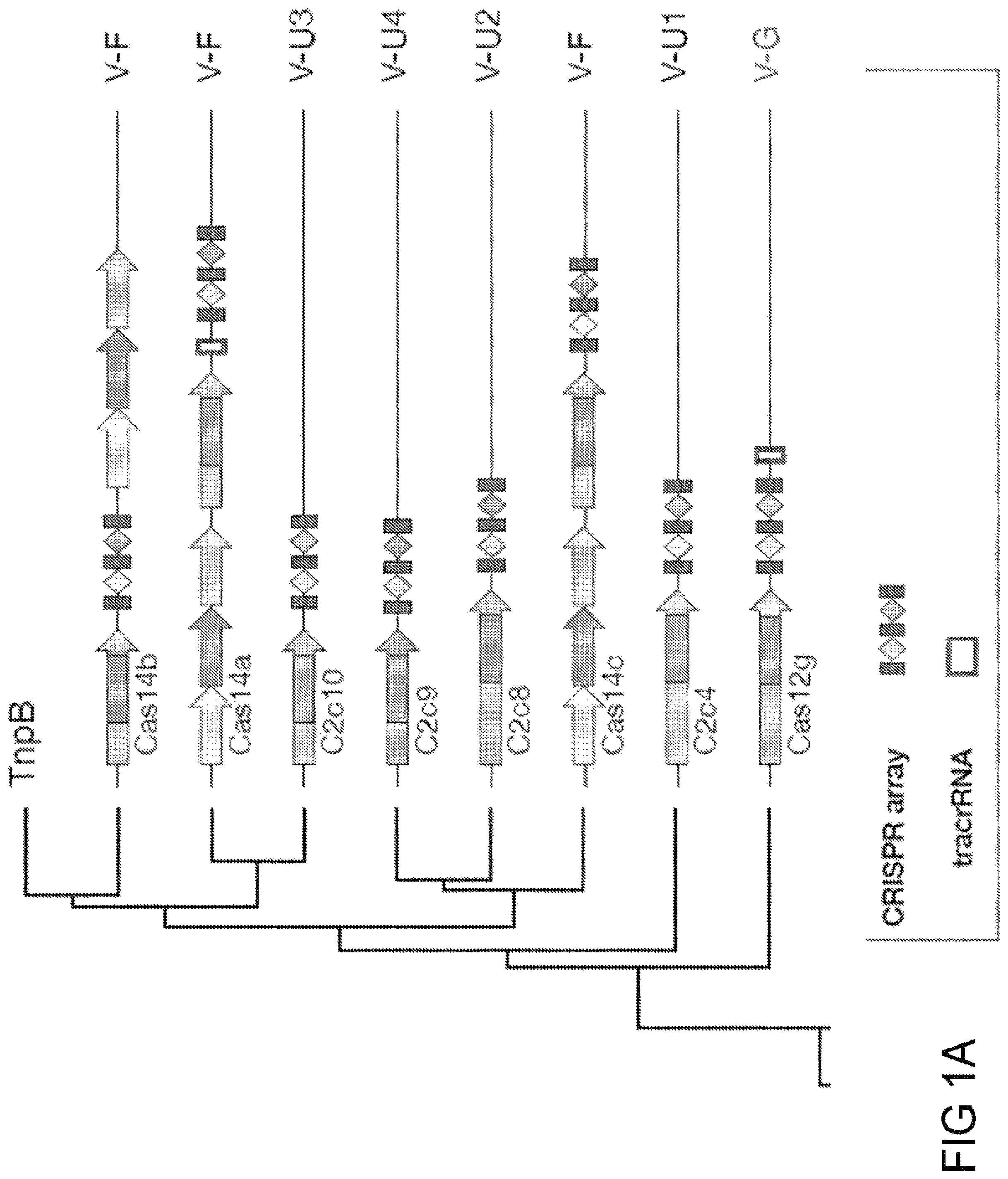
The disclosure describes novel methods and compositions that allow for targeted manipulation of nucleic acid in a targeted manner. The disclosure describes engineered CRISPR systems and components that can be used to modify nucleic acid such as DNA. Each system contains one or more proteins and one or two nucleic acid components, which together target nucleic acids.
![]()
Background for Crispr DNA targeting systems enzymes and systems
Recent advances in genome sequencing technology and analysis have provided significant insight into the genetic underpinnings of biological activities in many different areas of nature, from human pathologies to prokaryotic biosynthetic pathways. It is necessary to fully evaluate and understand the enormous amounts of information generated by genetic sequencing technologies. These new epigenome and genome engineering technologies will allow for the rapid development of innovative applications in many areas, including biotechnology and agriculture.
CRISPR-Cas and CRISPR/Cas genes are known to confer immunity against bacteria and archaea against infection. CRISPR-Cas systems for prokaryotic adaptive immune are a diverse set of proteins effectors, including non-coding elements and loci architectures. Some of these have been engineered to create important biotechnologies.
The components of host defense consist of one or more effector proteins that can modify DNA orRNA, and an RNA guidance element that targets these protein activities to a particular sequence of phage DNA/RNA. CRISPR RNA is the RNA guide. It may also require a trans-activatingRNA (tracrRNA), to allow targeted nucleic acids manipulation by the effector proteins. The crRNA is composed of a direct repeat that binds to the crRNA, and a complementary spacer sequence. CRISPR systems are able to be reprogrammed in order to target alternative DNA and RNA targets. This is done by changing the spacer sequence of crRNA.
CRISPR-Cas systems could be divided into two types: Class 1 systems contain multiple effector proteins, which together form a complex around the crRNA. Class 2 systems have a single effector protein. This complexes with either the RNA guide for target DNA or RNA substrates. The Class 2 systems’ single-subunit effector structure provides a simpler set of components for engineering and application transcription and has been an important source of programmable effectsors. The discovery, engineering, optimization, and application translation of new Class 2 systems could lead to powerful and widespread programmable technologies for gene engineering and beyond.
CRISPR-Cas systems, which are adaptive immune systems found in bacteria and archaea, protect the species from foreign genetic elements. CRISPR?Cas9 is an example of a Class 2 CRISPR?Cas system that has been characterized and engineered. This technology opens up a wide range of biotech applications, including genome editing. There is still a need for more programmable effectsors and systems to modify nucleic acid and polynucleotides, such as DNA, RNA or any other hybrid, derivative or modification, beyond the existing CRISPR-Cas system. These systems allow for novel applications due to their unique properties.
The citation or identification of any document within this application does not mean that it is admissible as prior art for the present invention.
This disclosure provides non-naturally-occurring, engineered systems and compositions for new single-effector Class 2 CRISPR-Cas systems, together with methods for computational identification from genomic databases, development of the natural loci into an engineered system, and experimental validation and application translation. The new effectors differ from existing Class 2 CRISPR effectsors in their sequence and have distinct domain organizations. These effectors have additional features, including 1) novel DNA/RNA editing capabilities and control mechanisms; 2) smaller size for greater flexibility in delivery strategies; 3) genotype-triggered cellular processes like cell death and 4) programmable RNA?guided DNA insertion and excision. The broad range of applications available for specific, programmatic perturbations can be made by adding the new DNA-targeting methods described herein to our toolbox of techniques for epigenome and genome manipulation.
In general, this disclosure pertains to CRISPR-Cas system, including newly discovered enzymes, and other components that allow for the creation of minimal systems that can work in non-natural environments (e.g. in bacteria other than the one in which it was first discovered.
In one aspect, disclosure provides engineered, naturally occurring CRISPR?Cas systems that include: (i) one or several Type V?I (CLUST.029130), RNA guides or one, more or more nucleic acids encoding one or more Type V?I CRISPR?Cas effectsor proteins; (ii) a Type V?I (CLUST.029130), CRISPR?Cas effector proteins or a nucleic Acid encoding the target sequence of the spacer sequence of the target sequence of the target nucleic-I RNA-guide and of RNA target sequences to the spacer sequence. The Type V-I CRISPR-Cas affector proteins (CLUST.029130), are also known as Cas12i-effector proteins. These terms are interchangeable in this disclosure.
In certain embodiments of any system described herein, the Type V?I CRISPR?Cas effector protein has a length of approximately 1100 amino acids (excluding any amino acid signal sequences or peptide tags fused thereto), and at least one RuvCdomain. One, two, or all of the RuvC domains can be catalyzed in some embodiments. The Type V-I CRISPR?Cas effector protein X1SHX4DX6X7 may be found in some embodiments.
![]()
In certain embodiments, the Type V-1 CRISPR-Cas Effector Protein includes or consists the amino acid sequence (SEQ ID No: 201), wherein A1 is A, G or S, and X6 or Q or I. X7 or T or S or V. X10 is T. or A. The Type V-I CRISPR?Cas effector protein may include or consist of the amino acids sequence X1X2X3E. (SEQ ID No: 210).
In some embodiments, Type V-ICRISPR-Cas impactor protein contains more than one sequence of the set SEQID NO: 200, SEQID NO: 201 and SEQID NO: 210. Some embodiments of the Type V-I CRISPR?Cas effector proteins include or consist of an amino acids sequence that is at least 81% (e.g. 82%, 83% or 84%), or more than one sequence from the set SEQ ID NO: 200, SEQ ID No: 201, or both.
In some embodiments, the Type V?I CRISPR?Cas effector proteins includes or consists in an amino acid sequence that is less than 80% (e.g. 81%, 82%. 83%. 84%. 85%. 86%. 87%. 99%. 100%). This sequence is identical to the amino acids sequences of Cas12i1 and Cas12i2(SEQ ID NOT: 3 or 5). Cas12i1 or Cas12i2 are the Type V-I CRISPR?Cas effector proteins in some embodiments (SEQID NO: 3 or 5).
In certain embodiments, the Type V?I CRISPR?Cas effector protein can recognize a protospacer adjacent mole (PAM) and the target nucleic acids includes or consists a PAM that includes or comprises the nucleic Acid sequence 5?-TTN-3?” or 5?-TTH-3 or 5?-TTY-3 or 5?-TTY-3?
In certain embodiments of any system described herein, the Type V?I CRISPR?Cas effector protein contains one or more amino acids substitutions within at most one RuvC domain. One or more of the amino acid substitutions may include an alanine substitution at an amino residue that corresponds to D647, E894 or D948 in SEQ ID No: 3. One or more of the amino acid substitutions may include an alanine substitution at an amino sequence corresponding to D599, E833 or D886 in SEQ ID No: 5. One or more of the amino acid substitutions may result in a decrease in the nuclease activities of the Type V?I CRISPR?Cas effector proteins, as compared with the nuclease activities of the Type V?I CRISPR?Cas protein without the one/more amino acid substitutions.
In certain embodiments of any system described herein, the Type V RNA guide includes an indirect repeat sequence that includes the stem-loop structure proximal the 3? End (immediately adjacent the spacer sequence). The Type V-IRNA guide direct repeat may include a stem loop that is proximal the 3? End at the 5th nucleotide of the stem. The Type V-IRNA guide direct repeat may include a stem loop that is located proximal the 3? End at the 5 nucleotide long stem and 7 nucleotide long loop. The Type V-IRNA guide direct repeat may include a stem loop that is proximal the 3. End at the 5 nucleotide long stem and 6 or 7 nucleotide long loop.
In some embodiments, the Type V-I RNA guide direct repeat includes the sequence 5?-CCGUCNNNNNNUGACGG-3? (SEQ ID No: 202) Proximal to the 3 End, where N is any nucleobase. In some embodiments, the Type V-I RNA guide direct repeat includes the sequence 5?-GUGCCNNNNNNUGGCAC-3? (SEQ ID No: 203) located proximal the 3? End, where N refers to any nucleobase.
In some embodiments, the Type V-I RNA guide direct repeat includes the sequence 5?-GUGUCN5-6UGACAX-3? (SEQ ID No: 204) located proximal the 3? End, where N5-6 refers a contiguous sequence containing any 5 or more nucleobases and X1 refers either to C, T, or U. In some embodiments, the Type V-I RNA guide direct repeat includes the sequence 5?-UCX3UX5X6X7UUGACGG-3? (SEQ ID No: 205) located proximal the 3? end, wherein X3 refers to C or T or U, X5 refers to A or T or U, X6 refers to A or C or G, and X7 refers to A or G. In some embodiments, the Type V-I RNA guide direct repeat includes the sequence 5?-CCX3X4X5CX7UUGGCAC-3? (SEQ ID No: 206) located proximal the 3. End, where X3 is C or U or T, X4 is A or T, U, or X5, X5 refers C or U or U, and A or G refers X7.
In certain embodiments, the Type V-1 RNA guide includes a direct repetition sequence, including or consisting in a nucleotide combination that is at least 88% identical to a nucleotide pattern provided in Table 5A (e.g. SEQ ID NOs 6-19 and 19-24).
In certain embodiments, the Type V-1 RNA guide includes or comprises a nucleotide sequencing or subsequence thereof as provided in Table 5B (e.g. SEQ ID Nos. 150-163). The Type V-IRNA guide may include or consist of a nucleotide combination that is made by concatenating a direct repetition, spacer, and direct repeat sequence. In Table 5A, the direct repeat sequence is given, while the length of the spacer can be found in the Spacer Lens 1 column of Table 5B. The Type V-IRNA guide may include or consist of a nucleotide combination that is made by concatenating a direct repetition, spacer, and direct repeat sequence. In these cases, Table 5A provides the direct repeat sequence, while the Spacer Lens 2 column of Table 5B gives the spacer length. The Type V-IRNA guide may include or consist of a nucleotide combination of a direct repetition, spacer, and direct repeat sequence. In these cases, Table 5A contains the direct repeat sequence, while the Spacer Lens 3 column is Table 5B.

In certain embodiments of any one of the systems described herein the spacer sequence for the Type V-IRNA guide includes or comprises between 15 and 34 nucleotides (e.g. 16, 17, 18, 19, 20, 21 or 22 nucleotides). The spacer can be between 17 and 31 nucleotides long in some of the systems discussed herein.

Click here to view the patent on Google Patents.