Invented by Chengwen Robert Chu, Wenjie Bao, Glen Joseph Clingroth, SAS Institute Inc
Automated computer-based modeling development, deployment, and management refer to the use of software tools and platforms that enable organizations to create, test, and deploy predictive models without the need for extensive programming skills. These tools leverage machine learning algorithms and artificial intelligence to automate the modeling process, making it faster, more accurate, and less prone to errors.
One of the key drivers of this market is the growing need for businesses to make data-driven decisions. With the explosion of data in recent years, organizations are looking for ways to extract insights and make better decisions based on data. Automated computer-based modeling development, deployment, and management tools provide a way to do this by enabling organizations to build predictive models that can help them identify patterns, trends, and anomalies in their data.
Another driver of this market is the increasing adoption of cloud computing. Cloud-based modeling platforms offer several advantages over traditional on-premise solutions, including lower costs, greater scalability, and easier deployment. This has led to the emergence of several cloud-based modeling platforms that are gaining traction in the market.
The market for automated computer-based modeling development, deployment, and management is also being driven by the increasing availability of open-source machine learning libraries and frameworks. These libraries and frameworks provide developers with a set of tools and algorithms that they can use to build predictive models quickly and easily. This has led to the emergence of several open-source modeling platforms that are gaining popularity in the market.
In terms of geography, North America is expected to dominate the market for automated computer-based modeling development, deployment, and management due to the presence of several key players in the region. However, the Asia Pacific region is expected to grow at the highest CAGR during the forecast period due to the increasing adoption of advanced analytics and machine learning technologies in the region.
Some of the key players in the market for automated computer-based modeling development, deployment, and management include IBM Corporation, Microsoft Corporation, SAS Institute Inc., SAP SE, and Oracle Corporation. These companies are investing heavily in research and development to create innovative solutions that can help organizations build predictive models quickly and easily.
In conclusion, the market for automated computer-based modeling development, deployment, and management is expected to grow rapidly in the coming years due to the increasing demand for advanced analytics and predictive modeling capabilities across various industries. The emergence of cloud-based modeling platforms, open-source machine learning libraries, and frameworks, and the increasing adoption of machine learning technologies in the Asia Pacific region are expected to drive the growth of this market.


The SAS Institute Inc invention works as follows
Computer-based models can be created, deployed, and managed automatically. A model building tool may be chosen based on compatibility with one or more parameters. The model building tool can generate a first machine-learning model and then train it using a training data set. This first machine-learning model is then able to be used for a task. The new tool’s compatibility with one or more parameters can then be used to select a different model-building program. The new tool can generate a second machine-learning model and it can then be trained with the training data. You can compare the accuracy of both the first and second machine-learning models. The second machine learning model is more accurate and can be used for the specific task.


Background for Automated computer-based modeling development, deployment, management
Machines can create models that analyze data from sensors and electronic devices in order to extract important information. This information can be used for controlling how the machine works. A robot might use a model to analyze depth sensors or cameras to identify objects. This can allow the robot to navigate through the world without colliding with it. Complex expressions and data can be included in models, which can either be dynamic or static. One example of a type of model is a neural network. This can contain a mathematical expression, or relationship, that can be adjusted (e.g. can?learn??, as in machine learning) over time to increase performance and accuracy. However, models can be difficult to create and maintain. This can lead to a host of problems for machines that depend on them.
In some cases, the system described in the disclosure may include a processor and a memory device where instructions that can be executed by the processor are stored. Instructions can be used to instruct the processor to choose a model-building tool from a variety of models. This is based on whether the model building tool is compatible with one or several parameters (i) of a machine learning algorithm or (iii) of the training data that can be used to train the machinelearning model. A variety of models building tools are available to be used in the generation of machine learning models. Instructions can be used to instruct the processor to create a machine-learning model by providing one or more parameters to its model building tool. Instructions can be used to instruct the processor to train the first machine learning model by using a training dataset. Instructions can be used to instruct the processor to use the first machine learning model to perform a task. Instructions can cause the processor to perform additional operations after the initial machine-learning model has been used to complete the task. The instructions could cause the device to be given a new tool for building models. Instructions can be used to cause the processing device incorporate the new model building tool into its plurality of modeling tools. The instructions may cause the processing device select the appropriate model-building tool among the multitude of available tools. This is based on whether the new tool can be used with one or more parameters. Instructions can be used to instruct the device to create a second machine learning model by providing one or more parameters. Instructions can cause the processing to train the second model from the training dataset. Instructions can cause the processing unit to input a value from the training data to the first machine learning model in order to generate a first output. Instructions can cause the processing unit to input the data from the training set to the second machine learning model in order to determine the second output of the second machine learning model. Instructions can cause the processing unit to compare the first and second outputs from the first machine learning model with an output value from the second machine learning model. This will determine if the output in the training data is more close to the first or second output. The input value in training data can be used to correlate the output value of the training dataset with the input value. If the instructions are clear enough to cause the processing device, it can decide to use the second machine learning model to complete the task, rather than the first.
A non-transitory computer readable medium may also include instructions that can be executed by a processor device to cause it to perform operations. The instructions could instruct the processor to choose a model-building tool from a variety of models based on whether the model building tool is compatible with one or two parameters (i) of a machine learning algorithm or (iii) of the training data that can be used to train the machinelearning model. A variety of models building tools are available to be used in the generation of machine learning models. Instructions can be used to instruct the processor to create a machine-learning model by providing one or more parameters to its model building tool. Instructions can be used to instruct the processor to train the first machine learning model by using a training dataset. Instructions can be used to instruct the processor to use the first machine learning model to perform a task. Instructions can cause the processor to perform additional operations after the initial machine-learning model has been used to complete the task. The instructions could cause the device to be given a new tool for building models. Instructions can be used to cause the processing device incorporate the new model-building instrument into the multitude of model building tools. The instructions may cause the processing device select the appropriate model-building tool among the multitude of available tools. This is based on whether the new tool can be used with one or more parameters. Instructions can be used to instruct the device to create a second machine learning model by specifying the parameters of the new tool. Instructions can cause the processing to train the second model from the training dataset. Instructions can cause the processing unit to input a value from the training data to the first machine learning model in order to generate a first output. Instructions can cause the processing unit to input the data from the training set to the second machine learning model in order to determine the second output of the second machine learning model. Instructions can cause the processing unit to compare the first and second outputs from the first machine learning model with an output value from the second machine learning model. This will determine if the first or second outputs are closer to the output value of the training data. The input value in training data can be used to correlate the output value of the training dataset with the input value. If the instructions are clear enough to cause the processing device, it can decide to use the second machine learning model to complete the task, rather than the first.
In some cases, a method may include choosing a model-building tool from a variety of models. This is based on whether the tool is compatible with one or two parameters (i) of a machine learning algorithm or (iii) of the training data that can be used to train the machinelearning model. A variety of models building tools are available to generate machine learning models. This method includes the generation of a machine-leaning model by using the model builder. This method may also include training the first machine learning model by using a training dataset. This method may include the use of the first machine-learning algorithm to complete a task. Following the use of the first machine learning model to complete the task, the method may include performing additional operations. The method could include the receipt of a new tool for building models. This could include the incorporation of the new model-building tools into the various model building tools. This can be done by selecting the appropriate model-building tool among the multitude of available tools. The new tool must be compatible with one or more parameters. This method may include the generation of a second machine learning model by using the new tool. The second machine-learning model can be trained using the training data. This method may include providing an input value to the first machine learning model from the training data to determine the first output of the first model. This can be done by comparing the first output of the first machine learning model with the second output of the second machine learning model to an output value from the training dataset to determine if the first or second output is closer than the output value from the training data. It is possible to correlate the output value of the training dataset with the input value from the training data. This method may include, based upon determining that the second outcome is closer to the output in the training dataset than the first output. The second machine-learning algorithm can then be used to complete the task, rather than the first. A processing device can perform some or all of these steps.
This summary does not identify the key features or essential characteristics of claimed subject material. It is also not intended to be used alone to determine the claim’s scope. Refer to the appropriate sections of the specification, all drawings and each claim to understand the subject matter.
The following specification, claims and accompanying drawings will make it easier to see the foregoing and other features and examples.
The following description provides a detailed explanation of technology examples. However, you can use different examples without requiring these details. These figures and descriptions are not meant to be restrictive.
The following description is for examples only and does not limit the scope, applicability or configuration of disclosure. The ensuing description of examples gives those skilled in art an enabling description to implement an example. You can make many changes to the function or arrangement of elements, but they do not have to be incompatible with the spirit and scope described in the claims.
To give you a clear understanding of the examples, the following description contains specific details. However, the examples can be used without these details. To avoid obscure the examples, you can show circuits, networks, processes, or other components as blocks in block diagram format. Another example is to show well-known processes, algorithms, structures and techniques without revealing too much detail, in order not to obscure the examples.
Individual examples can also be described as a flowchart or flow diagram. A flowchart may be used to describe operations in a sequence, but many operations can be done simultaneously or in parallel. You can also change the order of operations. The process is considered complete when it’s operations are completed. However, additional operations can be added to the figure. A process may be a method, function, procedure, subroutine, subprogram, or any combination thereof. If a process is a function, it can be terminated by the return of the function to its calling function or main function.


The systems shown in the figures may be configured in a variety of ways. The systems can be set up as a distributed system in which one or more of its components are distributed over one or more networks within a cloud computing environment.
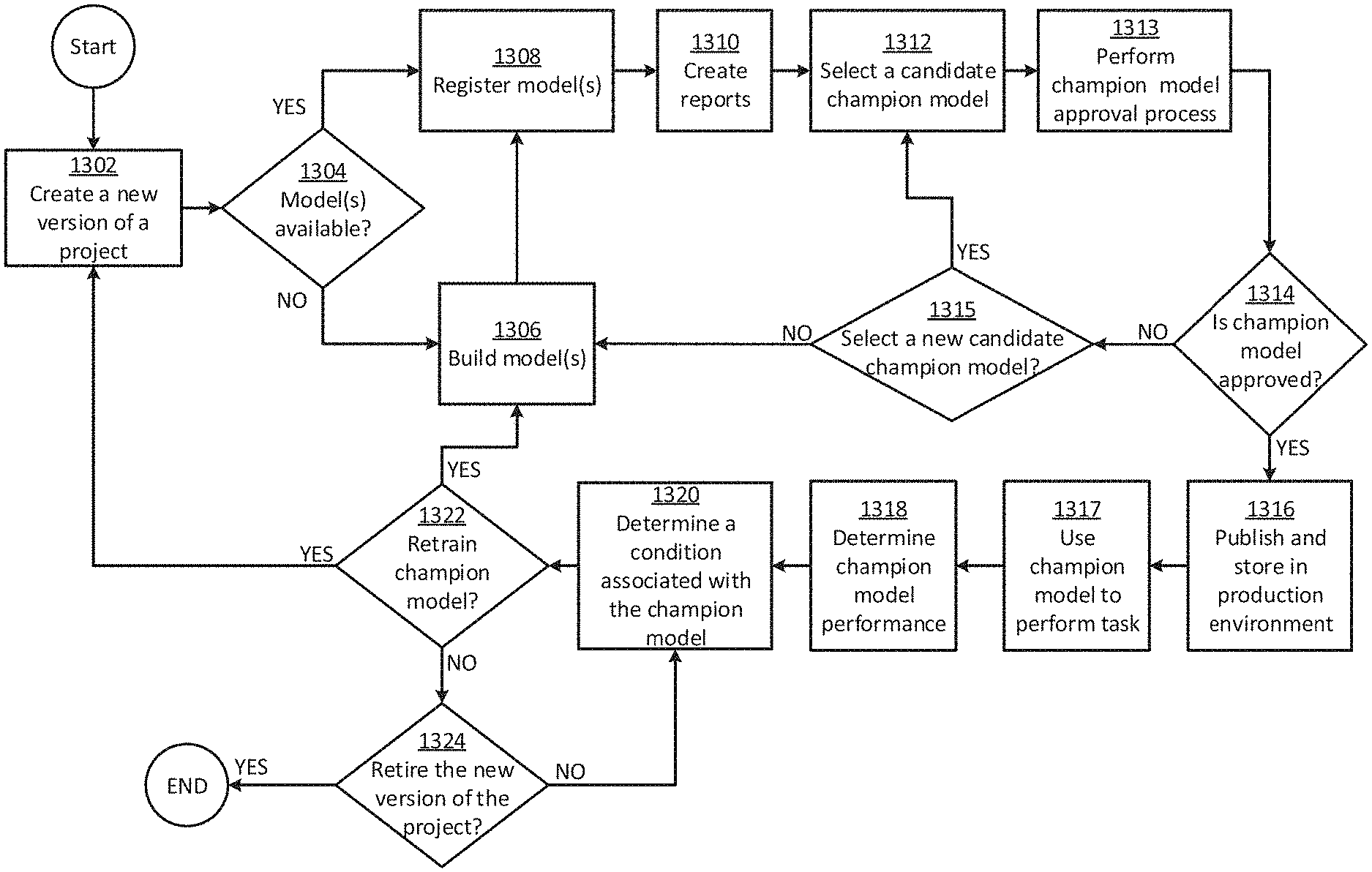
Some aspects and features of this disclosure relate to a system that allows models to be developed, deployed and managed in a semi-automatic manner. This will allow both technical and non-technical users alike to incorporate models into other devices and machines. The system may include an interface that allows users to request a model be made and select high-level parameters. This request is known as a request for model-building. Interfaces can include a graphical user interface, an application programming interface (API), and other types. The system can respond to a model-building request by performing the lower-level operations necessary to build the model according the high-level parameters set by the user. This layer of abstraction can be useful to provide an interface between the user’s model-building process and the system.
In some cases, the system can rebuild or retrain a model in response a certain event that occurs internally or externally to it. The system may automatically rebuild the model if new tools for building models are added to it. This can reduce errors and improve performance. Another example is that the system can rebuild a model when software is added to it or updated. The system might rebuild models in order to make them compatible with new or updated software. An event outside of the system may trigger the automatic rebuilding of the model. An event that is not part of the system could be an economic, regulatory, legal, or political event.
In certain cases, the system may include multiple modeling tools. Cloud Analytic Services (CAS), SAS are examples of model-building tools. STAT, Python scikit?learn and H2O are examples of model-building tools. Spark, etc. Spark, etc. The system can generate multiple versions of the model by using multiple model-building tools in response to a request for model-building. The system will then be able to compare multiple versions of the models and determine the most accurate version, and can provide that model for you.
In certain cases, the system may pre-process (e.g. analyze, transform or both) data that will be used to train a modeling model. This can improve the model. The system can analyse the training data and determine the characteristic of that data. One example of a characteristic is whether the data are compatible with a particular model or model-building tool. The system can transform the data to improve the model.
The system might determine that the data in training is compatible with a model or model-building tool in the current data format (e.g. an XML format) but will produce better results if it uses a different format (e.g. a JSON format). To improve the model, the system can transform the data into the desired format. Another example is that the system can analyze training data and determine that it contains ages of people as numeric numbers between 1 to 100. The system might recognize that some types of models perform better when ages are presented as groups rather than individual. The system can convert the training data so that the ages are shown as belonging to different groups. For example, (i) 0-25 year old; (ii), 26-50 years; (iii), 51-75 years; and (iv). 76-100 year old. The system can update training data so that values between 0-25 and 50 years old are replaced by a signifying group, 26-50 years old with a signifying group, 51-75 years of age are replaced by a signifying groups (ii), and 76-100 year old with a signifying group.
Some of the examples in this disclosure may lead to more precise and efficient models. The system can have the most accurate and efficient models possible for performing tasks by rebuilding or retraining models as new software is introduced. This will also ensure compatibility with new software.
Some examples of the disclosure could also result in significant improvements in a variety technical fields that rely upon models. These technical fields include autonomous navigation (e.g. with a robot/autonomous vehicle using a map-based navigation system), computer threat prevention (e.g. from viruses and hackers using model-based computer attack analysis system) and material molding machines and material curing machines. Models can be rebuilt repeatedly as new tools for building models are added to the system. Computers and machines that depend on models may have the best models, which allows them to continue improving their performance. A computer-threat assessment model can be rebuilt or upgraded whenever new software is introduced to it, or in response of intrusions. This improves the accuracy and efficiency. This can increase the efficiency and accuracy of the computer-threat assessment system.
The present disclosure may also lead to reduced processing times, computation time, or memory usage. Newer models, for example, may have shorter processing times, less computation time, and lower memory usage than older models. By re-building models when new tools for building models are introduced to the system or upon other events, you can ensure that the most efficient models are running within the system. This will help improve the overall performance by decreasing processing cycles, computation times, and memory usage.
Some examples of the disclosure also rely on a set rules to substantially automate tasks that would otherwise have to be done manually by humans. The system may include templates that are specific to different model-building tools. Each template could have its own set rules. The system can create executable templates by filling in high-level parameters that the user has provided to it. The system can then give executable versions to various modeling tools in order to create multiple versions of the model, such as concurrently or in parallel. The system will then automatically create multiple versions of the model by providing only the top-level parameters. The system might also be able to compare multiple models to determine the best one, and then make that model available to the user for further use. This is a departure from traditional systems that may require the user manually to create the program code for a specific model-building software or to navigate through multiple interfaces within the model-building software to create one model. To determine the best model, the user would need to repeat this process with each model-building tool. This can be very time-consuming, tedious, inefficient, inaccurate, and difficult.


FIGS. FIGS. 1-12 show examples of models and methods that can be used for management and model development according to certain aspects. FIG. FIG. 1 shows a block diagram showing some of the components of a computing device according to certain aspects. A data transmission network 100 is a computer system that can be used to process large amounts of data, where many computer processing cycles are needed.


Click here to view the patent on Google Patents.