Invented by WANG; Rui, POLLEFEYS; Marc André Léon, CHEN; Weirong


In this article, we will take a close look at a new patent application for tracking points in video images using neural networks. We will explore why this technology matters, how it fits into the current market, the science behind it, previous attempts at solving this problem, and finally, what makes this invention different and useful. By the end, you’ll have a clear, simple understanding of how this patent could shape the future of things like cameras, robots, video editing, and more.
Background and Market Context
Let’s start by explaining why tracking points in videos is so important and where it is used today. Imagine you have a camera moving through a room, taking lots of pictures one after another. Each picture is a frame in a video. Now, say you want to follow a spot—maybe a corner of a table or a person’s hand—as it moves through each frame. This is called tracking a point across an image sequence.
This task is at the heart of many modern technologies:
Visual Odometry: This is how robots, drones, and self-driving cars figure out where they are by using their cameras. By following points across video frames, they can tell how they are moving and turning.
Structure from Motion: Here, computers look at a set of pictures from different angles and try to build a 3D map of the world. They do this by tracking points across images.
Human Body Tracking: Think of motion capture in movies or fitness apps. These systems follow body parts across video frames to understand movements.
Video Editing: Editors can separate the background from moving people or objects by tracking points, making it easier to add effects or change scenes.
Vehicle Tracking: In advanced driver-assist systems, one car can keep an eye on another by following certain points, like headlights, as both vehicles move.
In all these cases, the better you can track points, the better the end result—whether it’s a more accurate map, smoother video effects, or safer self-driving cars. However, tracking points is not easy, especially when things move quickly, objects get blocked, or the camera shakes. Sometimes, the same spot might look different in each frame because of light, motion blur, or objects getting in the way.
Today, there are many ways to do this tracking. Some use simple math and rules. Others use machine learning. But the challenges remain: How do you know if the point you track is really the same thing in each frame? What if it’s hidden for a few frames? What if it moves in a tricky way?

This is where the new patent steps in. The inventors want to make tracking more accurate and reliable, even when things get tough. They also want to give more information, like how confident the system is that it’s tracking the right point, or if the point is on something moving or still.
The market for this kind of technology is huge and growing. Self-driving cars need better vision. Augmented reality on phones and headsets must know exactly where things are. Video editing is getting more complex, and robots are working in more places. Each of these needs smarter, more reliable tracking—and that’s what this patent aims to deliver.
Scientific Rationale and Prior Art
Now, let’s dig into the science behind tracking points in videos and what came before this invention. The main job is to follow the same spot from frame to frame. This sounds easy, but it’s actually quite hard because of many reasons, like changes in lighting, objects moving in front, or the camera moving in unexpected ways.
Older methods used basic image math. They tried to match small patches (tiny squares) from one frame to the next by looking for the most similar area. These methods included:
– Optical Flow: This tries to guess how each pixel moves from one frame to the next. It works well when things move slowly and there’s not much change, but it gets confused by fast motion, shadows, or when things are blocked.
– Feature Matching: This looks for special points, like corners or edges, that are easy to find in every frame. It matches these points across frames, but sometimes the matches are wrong, especially if the scene looks similar in many places (like a blank wall).
– Random Sample Consensus (RANSAC): This is a way to throw out “bad matches” by finding a group of points that fit together best. It helps, but it’s slow when there are lots of points.
– Supervised Machine Learning: In recent years, neural networks have been used to improve tracking. Some models learn to find and follow points using big sets of training videos. But these models often just predict where the point is, without saying how sure they are, or if the point stays visible and on the same object.
Most of these older approaches have a few key problems:
– They don’t know when they are making a mistake. They just give a best guess.
– They struggle when things get hidden for a few frames (occlusion).
– They can’t tell if a point is on a moving object or something still, which is important for building 3D maps or knowing which parts of a scene are changing.
– They don’t always use all the information in the set of images. Sometimes, they just look at two frames at a time, missing the bigger picture.
Some newer neural network approaches try to fix these issues. For example, transformers use attention to look at many parts of images at once, but they can be slow and need a lot of memory. Other models use convolutional networks, which are faster but might miss some context. Some methods use probability to guess how sure they are about the position, but these often use simple distributions like Gaussian, which are not always the best for video data.


In short, the field has made progress, but there is still a need for a system that can:
– Track points across many frames, not just two.
– Handle points that disappear and reappear.
– Say how confident it is about each tracking result.
– Tell if the point is on something moving or still.
– Work fast, even on high-resolution video.
The new patent builds on these ideas but brings in new tricks to solve the tough parts—especially by using a smart neural network that can adapt, share information in special ways, and give better confidence scores.
Invention Description and Key Innovations
Let’s walk through what this invention actually does and why it matters.
1. How the System Works
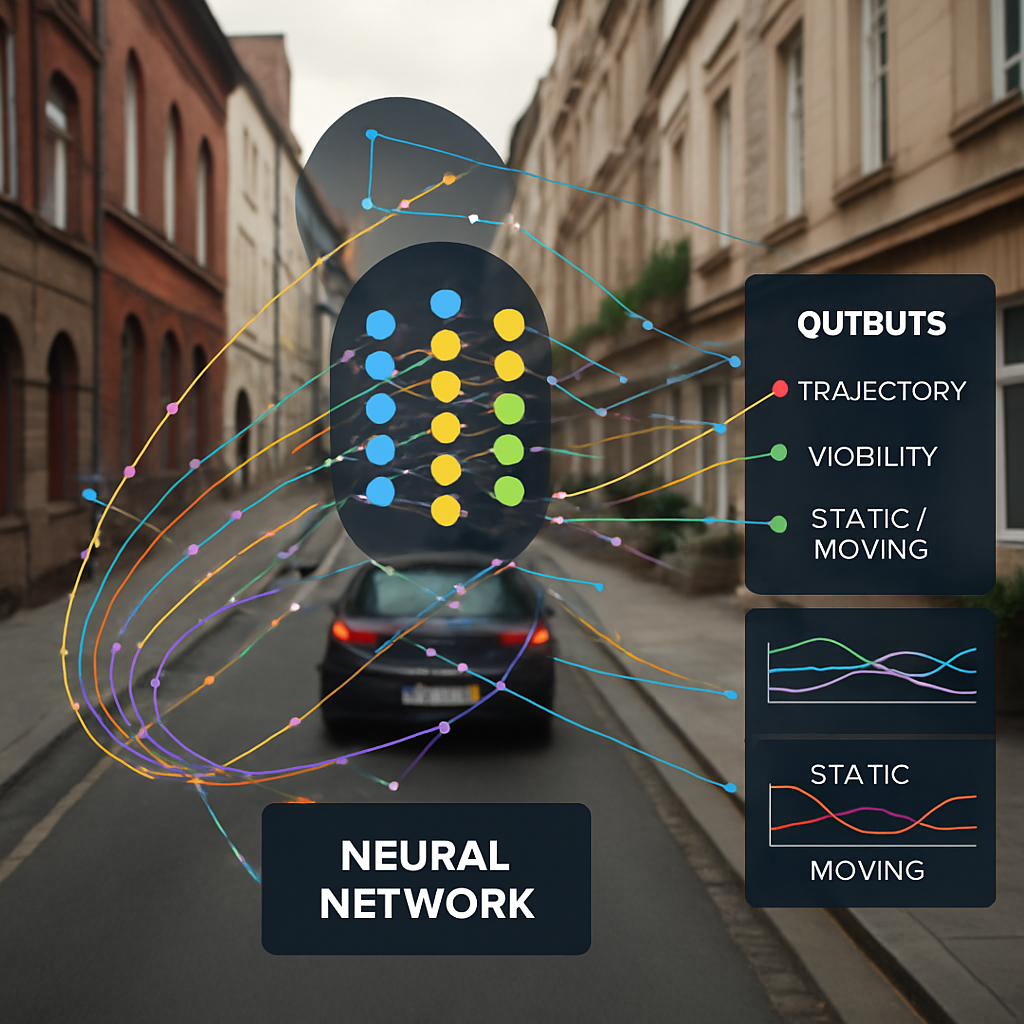
The basic idea is simple: take a set of images from a moving camera, pick some points in one image, and use a neural network to track where those points go in all the frames. But this system goes much further.
Here’s what happens step by step:
– The system receives a sequence of images from a camera.
– It picks special points to track (these can be corners, edges, or spots picked by the user or another system).
– For each point, the neural network tries to follow where it goes in every image, creating a “trajectory” for that point.
– For each trajectory, it predicts if the point is visible in each frame (or if it’s hidden), and whether the point is on a moving surface or something still.
– The neural network also gives a confidence score for each prediction, saying how sure it is.
– All these outputs go to other processes, like building a 3D map, tracking a person, editing a video, or following a car.

2. Smart Neural Network Design
The neural network in this invention has some special features:
– Feature Extraction: The first part of the network looks at the images to find important features. It does this in a smart way, using “deformable” and “dilated” convolutions. This just means the network can look at different parts of the image, at various scales, and adapt to the shape and movement. This helps it find and follow points even when things change shape or size.
– Spatial and Temporal Mixing: The network can share information in several ways. It mixes information across the color channels (red, green, blue) for each point, across time for each trajectory, and between different points in the same image. This helps the network see the bigger picture and spot patterns, even if points move in tricky ways or get blocked.
– Inter-Trajectory Attention: A special part of the network lets it look at all the points together and share knowledge. If one point is hard to track but another is easy, the network can use the easy one to help with the hard one. This “attention” makes tracking more robust.
– Probabilistic Output: Instead of just giving a single best guess, the network predicts a probability distribution for each point. This means it can say not just where it thinks the point is, but how sure it is. It uses a special kind of distribution called Cauchy, which is good for handling outliers (weird or unexpected movements).
– Iterative Refinement: The network doesn’t just make a guess once and stop. It keeps refining its guess in several steps, getting better each time by looking at the local evidence and updating the trajectory and confidence.
– Visibility and Motion Prediction: For each point, it also predicts if the point is visible in each frame (or hidden behind something), and if it’s on a moving object or something still. This helps downstream tasks like 3D mapping or object recognition.
3. Efficient and Flexible Design
The system is made to be fast and work on many devices, from phones to cloud servers. It can handle high-resolution images without slowing down. It can also pick points from any frame, not just the first one, which is handy for various applications.
Anchor points are used to cover the image well, especially near edges, which are easier to track. These anchors are picked using simple image processing (like the Sobel filter) and grouped in a grid, so the network always has good points to work with.
The network can be trained with real or simulated data. It learns by comparing its guesses to known correct answers, using a loss function that rewards accurate tracking, correct visibility prediction, and right motion labels. It can be trained end-to-end, meaning all parts learn together for best performance.
4. Downstream Use Cases
Once the system tracks points and outputs trajectories with visibility, motion, and confidence, these results can be used in many ways:
– Visual Odometry: Only high-confidence, visible, and static points are used to compute the camera’s position and orientation. This makes mapping more accurate.
– Structure from Motion: By knowing which points are on moving things, the system can build a cleaner 3D model of the environment.
– Human Body Tracking: More robust tracking of joints and limbs, even if some get blocked or move quickly.
– Video Editing: Segmentation and tracking are more precise, so editors can apply effects more easily.
– Vehicle Tracking: It’s easier to follow other cars in traffic, even if they get blocked or move unpredictably.
5. Hardware and Software Flexibility
The invention can run on all sorts of devices: phones, wearables, robots, cars, servers, and more. It can use CPUs, GPUs, or even special chips like FPGAs or ASICs for faster performance. The software can be stored and run in different ways, making it easy to deploy in many settings.
6. Real-World Performance
Tests show that this system outperforms older methods, especially in tough scenes with moving objects or when things get blocked. It’s fast, accurate, and gives more useful information for further processing.
Conclusion
This patent presents a big step forward in the world of tracking points in videos. By combining neural networks, smart feature extraction, sharing information between points, and predicting confidence and motion, it solves many problems faced by older methods. It works well in real life, is fast, and can be used in many devices and fields—from robots and self-driving cars to video editing and augmented reality. If you work with video, imaging, or any system that needs to know how things move, this technology offers a practical, reliable, and flexible solution. The future of seeing and understanding the moving world just got a lot clearer.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218003.