
Invented by Kim; Joohwan, Spjut; Josef, Frosio; Iuri, Gallo; Orazio, Prashnani; Ekta

Curious about how computers can predict where we look, even when our eyes are drawn to things we cannot see? This article breaks down a patent application covering the use of neural networks to predict user gaze, even when objects are hidden or events are only likely to happen. We will walk you through the real-world context, the science and previous inventions, and finally, the unique steps and technical magic this invention brings to the world.
Background and Market Context
Imagine watching a video game, a sports match, or driving a car—your eyes aren’t just looking at what’s in front of you. Sometimes, you glance at a corner because you expect something to happen, like an opponent hiding or a car about to appear. Companies want to know where you’ll look, so they can improve video streaming, make games more fun, help drivers stay safe, or even decide where to put ads.
This interest in “gaze prediction” impacts many industries. Gaming companies use it to boost player engagement and make games more fun to watch. Streaming services want to send the best video quality to where you look, saving bandwidth everywhere else. Car makers and robotics engineers use it to help drivers and machines anticipate danger, by knowing what grabs human attention. Advertisers care because they want their messages where people actually look, not just where the screen is brightest.
In our digital lives, eye-tracking hardware and software are becoming more common. Phones, VR headsets, and even cars are starting to follow our eyes. But there’s a challenge: people don’t always look at what is directly visible. Often, our attention is drawn to places where hidden things might happen, like behind a wall or around a corner.
Today’s systems mostly predict gaze by looking at what’s visible right now. If there’s an object moving quickly or making noise, they expect you to look at it. But that’s not always true. Sometimes, you look at a spot because you think something will pop out, even if nothing is there yet. This is where the new patent application steps in—using neural networks to predict gaze even for hidden or “occluded” objects, by learning from past gaze patterns and possible events in the scene.
This new approach is set to help:
– Game studios design better, more exciting experiences.
– Video streaming services send sharper images where you care, saving data elsewhere.

– Car safety systems warn drivers about hidden dangers, even before they become visible.
– Advertisers place messages where they’ll truly be seen.
As people spend more time in digital worlds, making computers “see” and “think” like us, even about the things we imagine behind the scenes, is a key leap forward.
Scientific Rationale and Prior Art
For years, researchers have tried to predict where people look, using simple rules. If something moves, makes a noise, or looks different, it gets your attention. Early gaze prediction systems used these rules, sometimes with basic machine learning, to guess where your eyes would go in a picture or video.
As deep learning and neural networks became popular, these systems improved. Convolutional Neural Networks (CNNs) learned to find “salient” or important regions in images. They built “saliency maps” showing which parts of a frame are most likely to be looked at, based on patterns seen in lots of training data. In videos, Recurrent Neural Networks (RNNs), including Long Short-Term Memory (LSTM) networks, helped track attention over time.
But all this work had a big blind spot: they mostly predicted gaze based on what is directly visible. They didn’t consider “occlusion”—when something interesting is hidden behind another object—or the human tendency to look at places where something could happen soon, even if nothing is there yet.
Some inventions tried to go further. For example, attention models in video games tried to predict where a player would look based on game events. In cars, eye trackers helped see if a driver was paying attention to the road, but they didn’t guess where a driver might look if worried about a hidden hazard. Other prior patents discussed using gaze to optimize video compression, but only by focusing on current visible objects—not by “imagining” what might be behind an obstruction.
The big leap in this patent is using neural networks to learn from not just visible objects, but from “gaze history” and possible hidden events. This means the system can predict that you’ll look at a doorway, not because there’s something there now, but because it’s likely that something could happen—like an enemy in a game or a car pulling out in traffic.
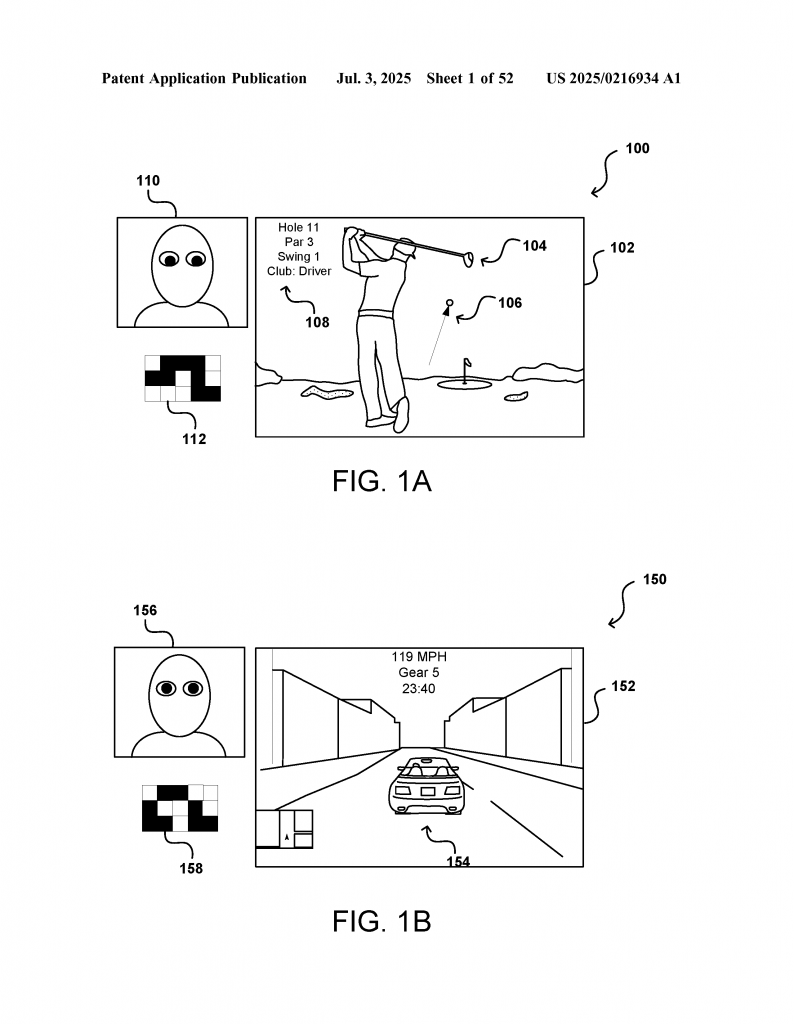
This approach is inspired by how people really act: we don’t just react, we anticipate. We look ahead, scan corners, and check spots where surprises might come from. By blending past gaze data, object detection, and predictions about possible events (even “invisible” ones), the invention creates a smarter, more human-like model of attention.
No previous system could combine these elements—past gaze patterns, occluded objects, event probabilities, importance scores, and explainability—into a working, trainable neural network that could be used in real time for many applications.
Invention Description and Key Innovations
Now, let’s break down the heart of the patent application. The invention centers on using a processor or system (could be a CPU, GPU, or an AI chip) to run one or more neural networks that predict where one or more users will look, even at objects that are hidden or only likely to appear.
Here’s how it works, in simple steps:
1. Learning from Gaze History: The system collects data about where users have looked in the past, including at visible objects and at spots where something was hidden or about to happen. This can include videos, games, or even real driving footage.
2. Object and Event Detection: The neural network analyzes each frame of a video (or each moment in a game or driving scene) and detects not just visible objects, but also “occluders”—things like walls, cars, or bushes that might hide something interesting behind them.
3. Predicting Event Probabilities: For each spot in the scene, the system figures out how likely it is that something important could happen there. For example, a corner might have a high chance that someone or something will pop out. This probability is based on patterns learned from lots of user gaze data.
4. Assigning Importance Scores: Not all events are equal. Some (like a child running into the street) are very important, while others (like a bird flying away) may not matter as much. The system learns to assign “importance” to different event types.
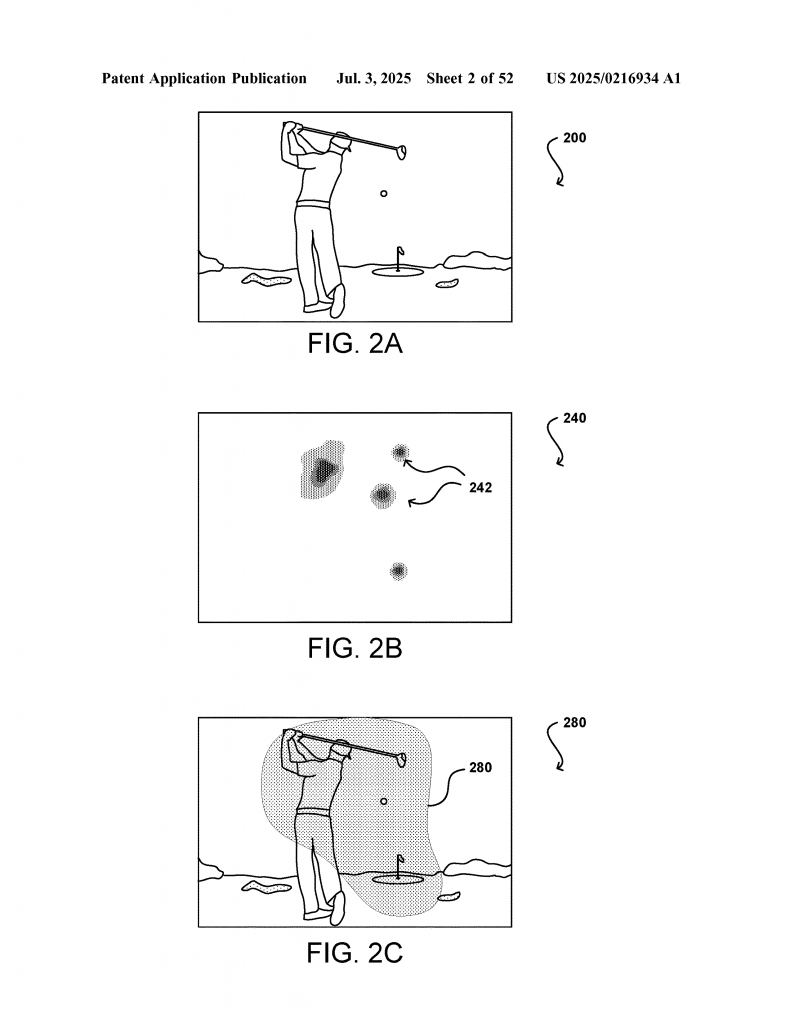
5. Clustering and Context: The model groups similar events and objects together, so it can generalize across different scenes or games. For example, all corners that might hide danger are put in a cluster.
6. Building Attention Maps: Each video frame is divided into a grid. For each cell in the grid, the system calculates an “attention value” by multiplying the probability of important events by their importance scores, summing up over all possible events.
7. Gaze Prediction: The neural network uses these attention maps, along with other image features, to predict where users are most likely to look next. This works even if the reason to look is anticipation—like waiting for something to appear from behind a bush.
8. Explainable Predictions: The system doesn’t just give a “black box” answer. It can explain why it thinks a user will look at a spot—maybe because of a high chance of an important event, or because many users have looked there in the past.
9. Training and Adaptability: The system can be trained on different types of data—gameplay, driving videos, or even surveillance footage. It can use different neural networks for different contexts (like racing games vs. golf games) and can adapt to new scenarios by learning from new gaze data.
10. Real-Time and Cross-Video Use: The invention allows gaze prediction to be made in real time, even as the scene changes. It can also use gaze history from one video to predict attention in a different but related video, making it robust for many applications.
What makes this invention stand out?
– Predicts attention to hidden or future events, not just visible objects.
– Combines gaze history, object detection, event probability, and importance in one trainable model.
– Supports explainability—users or developers can understand why a spot is predicted to get attention.
– Optimizes video streaming and rendering by focusing resources on predicted gaze regions.
– Improves safety in cars and robots by anticipating where a human will look in risky situations.
– Enables smarter ad placement and game design by knowing true attention hotspots.
Tactical uses include:
– Video Compression: The system can send better quality video only to regions where attention is likely, saving bandwidth.
– Game Development: Designers can place critical items in locations where players will notice, or hide secrets in less-visited spots.
– Driver Assistance: Cars can warn drivers about hidden dangers, or take over if the driver is not watching the right spot.
– Ad Placement: Ads can be positioned where they are most likely to be seen, or hidden from critical content.
How can you apply this today?
If you are in video streaming, use the model to send high quality only where the viewer is likely to look. If you develop games, use the attention predictions to design more engaging levels. For car safety systems, train the model on real driving data to make cars smarter about driver attention. For advertisers, use the system’s attention maps to find the best location for messages.
Conclusion
This patent application marks a big step forward in making machines understand human attention—not just what’s visible, but also what’s hidden or possible. By blending gaze history, event probabilities, importance scores, and explainability, the invention opens new doors for video streaming, gaming, robotics, car safety, and advertising. It helps computers think ahead, just like people do, making digital experiences smarter, safer, and more engaging for everyone.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250216934.