Invented by Bathwal; Rahil, Campos; Daniel Fernando, Devaraj; Ashwin, Li; Seth Michael, Pande; Yash, Raghunathan; Vivek, Samdani; Rajhans, Xu; Danmei


Search is something we use every day. We type words into a box and wait for answers. But what happens behind the scenes? How do search engines know what answer to give us? Today, search goes beyond simple keywords. It uses new smart systems called large language models and machine learning. This blog will take you through a new patent application that shows how search is changing. We’ll look at why search needs to get better, what science is behind these changes, and how this new invention works. By the end, you’ll see how search is growing smarter, faster, and more helpful in our lives.
Background and Market Context
Search engines are everywhere. When you want to know something, you use Google, Bing, or Yahoo. These engines help you find web pages, documents, videos, and more. But search is not perfect. Many times, you have to look at many links to find the answer you want. You get long lists of web pages, and you have to click, read, and compare. Sometimes, the results are not even close to what you need. This can take up a lot of time and leave you feeling lost.
Why does this happen? Old search engines mostly look for words that match your question. They count the number of times a word appears (like “dog” or “pizza”) and show you links with those words. But words can have many meanings. Context matters. For example, “apple” can be a fruit or a company. If you search for “how to make apple,” do you want to bake a pie or build a computer app?
As more people use the internet, the amount of information grows every day. There are blogs, news, social media, scholarly articles, forums, and much more. People want smart answers, not just more results. They want search to understand what they really mean, even if they don’t use the right words. They want search to summarize many sources and give them just what they need, right there on the screen.
This is where machine learning comes in. Machine learning is a way for computers to “learn” from lots of data. It isn’t just about matching words; it’s about understanding meaning. Large language models (LLMs) like GPT, BERT, and others can read and understand natural language. They can summarize, answer questions, and create text that sounds like a person. These models help search engines understand what you want and find the best answer across many sources.
But even with these new models, there are problems. Using one big language model for everything can be slow and expensive. It can make mistakes, misunderstand tricky questions, or give answers that are too broad. People want search to be fast, right, and easy to use. Companies want it to run on normal computers and not use too much power or money.
This new patent application is about making search smarter and more helpful using fine-tuned models. It looks at how to make search answer your questions quickly, clearly, and in a way that matches what you really want. It does this by teaching big language models to become experts in certain topics or tasks, making them smaller and faster, and letting people give feedback to make them even better. This is the next step in search technology, and it will change how we find answers online.
Scientific Rationale and Prior Art
Let’s talk about how search engines work now and what science is used behind the scenes. The old way of search is called “keyword matching.” The engine checks each page to see if it has your search words. It uses things like keyword frequency, how important a site is, and if other people like the site. These methods work okay, but they don’t always get the meaning right.

To get better, search engines started using machine learning. This means they train computers to find patterns in data. For example, they can learn what pages people click on most, or which pages people spend time reading. They use this to improve the results they show.
The big change came with natural language processing (NLP). NLP lets computers read, understand, and even write human language. Models like BERT, GPT-3, and T5 are trained on huge amounts of text from books, web pages, and more. They learn not just what words mean, but how sentences fit together and what people might really want when they ask a question.
But these models are huge. They need a lot of computer power and memory. They can be slow, which is bad for search. If you have to wait too long, you might leave. Also, one big model might not be good at everything. For example, a model trained to write stories might not be good at giving short, fact-based answers.
There are also problems with trust. Sometimes these models “hallucinate”—they make up answers that sound right but are not true. Or they might be biased, giving results that are unfair or incomplete. They can also be tricked by spam or low-quality content.
To fix these problems, scientists came up with new ideas:
Fine-tuning: Start with a big model and then train it on smaller, special data for a certain job. For example, you can take a big language model and teach it to summarize news articles, answer legal questions, or help with medical info. This makes the model better at that job and faster to use.
Model Compression: Make the model smaller without losing its smarts. You can do this by pruning (removing parts that don’t help much), distilling (teaching a small model to mimic a big model), or quantizing (making the numbers smaller and easier to store). This helps the model run on cheaper computers and respond faster.
Reward Modeling & Human Feedback: Let people help train the model. If users say an answer is good, the model learns from that. If people say an answer is wrong or confusing, the model tries to do better. This is called Reinforcement Learning from Human Feedback (RLHF). It’s like teaching a child by giving them gold stars for good work and gentle correction for mistakes.
Before this patent, there were some systems that tried these ideas, but they often focused on just one thing. Some used big models for everything, which was slow. Others made small models but didn’t use human feedback well. Some tried to summarize information, but didn’t allow users to interact or set their own preferences. Most search engines still made users click through many pages to find answers.
This new patent brings these ideas together. It creates a system where you get:


– A smart, fine-tuned model that is an expert in a certain area.
– A way to make the model faster and smaller, so it works well in your browser.
– A feedback loop where your choices and ratings help the model get better for everyone.
– Answers that are not just lists of links, but summaries, explanations, and even source citations, all in one place.
This is a big jump forward from the usual search tools. It uses the best science available, brings in new tricks for speed and accuracy, and lets people be part of the learning process. That’s what makes this invention special.
Invention Description and Key Innovations
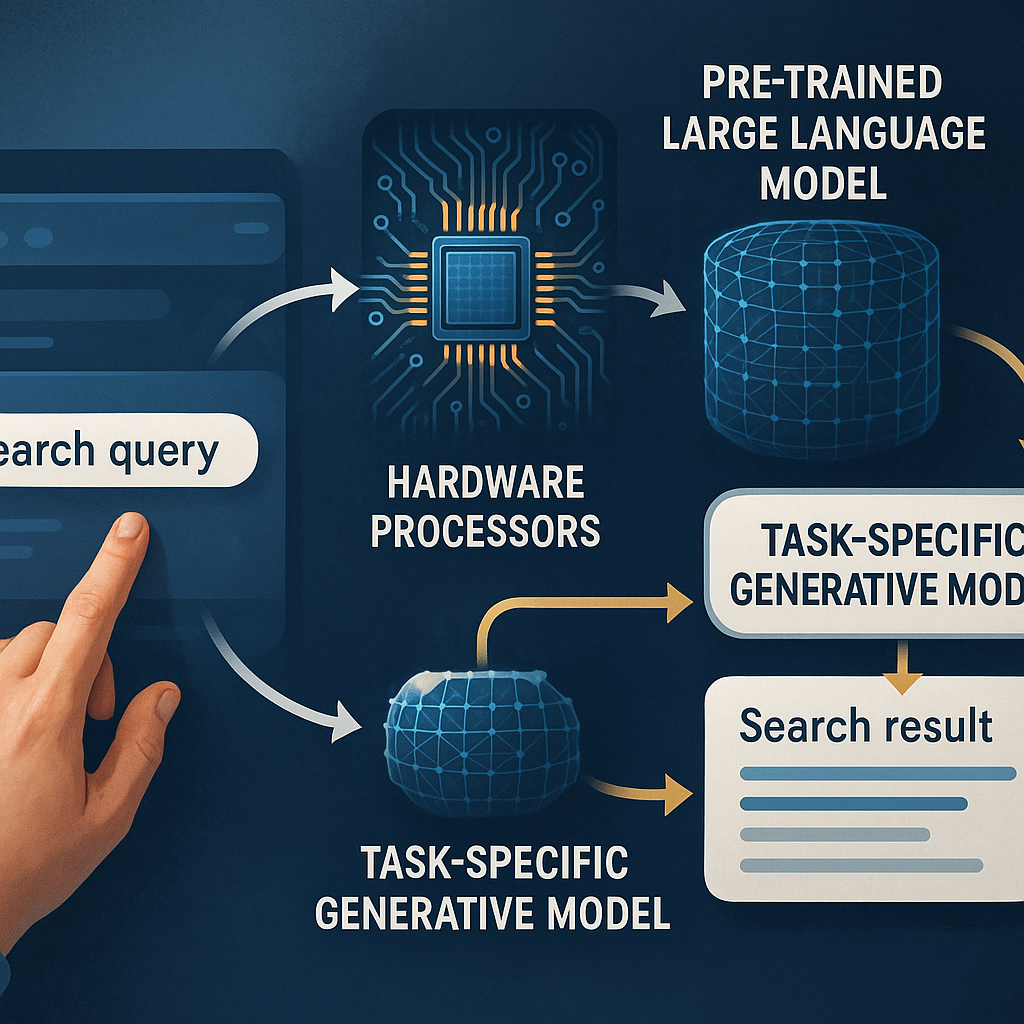
Now let’s look at how this new search system really works. Imagine you type a question into a search box. Here’s what happens, step by step:
Step 1: Receiving the Search Query
You ask a question through a browser or app. The system takes your words as they are, with no need for special keywords or tricks.
Step 2: Accessing a Pre-trained Large Language Model
The system starts with a big, smart language model (like GPT-3 or BERT). This model already knows a lot about language from reading tons of web pages, books, and documents.
Step 3: Domain-Specific Pre-Training
But instead of using the big model as-is, the system trains it further on special data from a certain domain (like medicine, law, shopping, or news). This makes it an expert in that area. For example, if you’re searching for recipes, it knows food terms and cooking steps really well.
Step 4: Fine-Tuning for the Task
The model is fine-tuned even more for a specific job. For instance, maybe you want short, clear answers, or maybe you want full summaries with citations. The system trains the model on examples of good answers for that task. Now the model is smaller, faster, and really good at one thing.

Step 5: Model Compression
To make the model easier to use and run quickly, the system shrinks it using special tricks. It removes parts that don’t help (pruning), teaches a small model to copy a bigger model (distillation), or stores numbers in a simpler way (quantization). This way, the system can answer questions fast, even on a phone or simple computer.
Step 6: Generating Multiple Answers
When you type your question, the model creates several possible answers. Each answer might be a little different—one might be short and direct, another might be longer with more detail, and another might add context.
Step 7: Reward Modeling with Human Feedback
Here is where it gets really smart. The system checks which answer matches what real people like. It does this by using a “reward model.” This reward model is trained by looking at what answers people rated as helpful, clear, and correct. The system gives each answer a score. The answer with the highest score is picked to show you.
If users give feedback (like a thumbs up or down), the system remembers. Over time, the model learns to give better answers that match what people want. This is called Reinforcement Learning from Human Feedback (RLHF). The system can even adjust how much it explores new answers or sticks to what works best, by tuning its settings (hyperparameters) like how much it cares about new ideas versus old favorites.
Step 8: Presenting the Best Answer
You get the top answer right in your browser. It’s not just a list of links. It might be a summary with sources, a step-by-step guide, or a simple direct reply. If you want, you can see the sources or ask for more details. You can even set your preferences, like if you want answers from trusted sites only, short or long answers, or answers in easy words.
Step 9: Interactive and Personalized Experience
The system lets you interact in real time. If you want to change your question or dig deeper, you can do it without starting over. The system remembers your preferences and history (if you allow it), so it gets better at guessing what you like. It can even pull in information from your other searches, your device, or similar users (with privacy controls).
Step 10: Continuous Improvement
Every time someone uses the system, it gets a little smarter. It learns from feedback, new data, and changing trends. If the world changes (like a new discovery or a breaking news story), the system can update quickly and keep answers fresh.
More Features and Innovations
– Summarization: The system can take information from many sources and make one clear answer, showing where each piece came from. This helps people trust the answer.
– Real-Time Customization: You can choose what you care about—trusted sources, answer style, or even which models are used.
– Broad Use: This system isn’t just for web search. It can help with legal research, shopping, learning, or any area where people want smart answers from lots of data.
– Speed and Efficiency: By making models smaller and task-specific, the system saves money and power. It can be used in businesses, schools, or even on personal devices.
What sets this system apart is how it brings all these parts together:
– It starts with a big, smart language model but makes it an expert for one job.
– It uses feedback from real people to get better every day.
– It gives you clear, trusted answers, not just more links.
– It works fast and uses less computer power, so it’s good for everyone.
This is a big step forward in search technology. It means you spend less time searching and more time getting good answers. It helps people learn, make decisions, and solve problems quickly and easily.
Conclusion
Search is changing. Old search engines gave you lists of links. New systems, like the one in this patent, give you real answers, summaries, and even let you help the system get better. They use big language models, but make them small, fast, and smart for the job you care about. They learn from you and everyone else, so answers keep improving. This means you get what you need, faster and with less effort.
If you want to build better search tools, keep these ideas in mind: start with strong language models, fine-tune them for your task, make them efficient, and always listen to your users. The future of search is here, and it’s smarter, faster, and more helpful than ever before.
If you want to learn more, or have questions about building search systems, reach out to an experienced patent attorney, or explore more about how fine-tuned models and user feedback can power the next generation of search.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217418.