
Invented by SPIRA; Yair David, KOZHUKHOV; Vladyslav, LIVNE; Dor, CHECK POINT SOFTWARE TECHNOLOGIES LTD.
Welcome! Today, we’ll explore a new and powerful computer system designed to spot fake websites and emails that pretend to be real brands. This technology builds a smart “brand registry” and uses clever machine learning to tell what’s real and what’s fake. We’ll break down how this works, why it matters, and what makes it so different from past solutions. Let’s get started.
Background and Market Context
Every day, people get tricked by emails or websites that look real but are actually fake. This is called phishing, and it is a big problem. The fake messages are made to look like they come from banks, stores, or other trusted places. When people trust these fakes, they might give away passwords, credit card numbers, or other private information. That can lead to money loss, stolen identities, and much stress.
The problem has only gotten worse as more people use the internet for shopping, banking, and talking with friends. Hackers have gotten better at copying the look and feel of real brands. Traditional security tools, like antivirus programs, spam filters, or email blockers, try to keep up, but they often miss these sneaky fakes. This is because fake messages are getting more clever. They copy brand logos, use similar colors, and even copy the words and style of real companies. Sometimes, they use real-looking website addresses or even buy security certificates to look safe.
For companies, this is not just a headache—it’s a real business threat. If their brand is used in a scam, they can lose trust. Customers may get angry or stop using their services. Even for everyday users, the risks are serious. You might think you’re logging into your bank, but really you’re handing your password to criminals.
Because of this, there’s a big need for better ways to tell real brand messages from fakes. The best way is to look for things that only the real brand would have, and to do this in a smart, fast, and automatic way. The new system we’ll talk about today is made to do just that. It builds a registry of real brands by looking at both how things look (like logos and designs) and what they say (like names and words). Then, it checks new messages or websites against this registry and uses machine learning to make a smart decision. This system doesn’t just block spam—it tries to truly understand what makes a brand real.
Scientific Rationale and Prior Art
To understand why this new invention is special, let’s first look at what has been done before and where those older ways fall short.
For a long time, most tools for stopping phishing have used simple checklists. For example, they look for certain bad words, blacklisted website addresses, or tricky links. Some check if the sender’s address matches the company name. Others look for strange attachments or keywords like “urgent” or “password.” These basic checks can catch some scams, but hackers quickly learn how to get around them.
A step above that, some security systems use fingerprinting. They look for patterns in emails or websites—such as the way links are made, the types of images used, or how the words are written. They might also check if a website has a valid security certificate or if the domain name is very new. These methods are a bit smarter, but they can still be fooled by well-made fakes. Also, they often need to be updated all the time to keep up with new tricks.
A few advanced systems use machine learning. These systems are trained on lots of examples of good and bad messages. They try to learn what makes something look real or fake. But even these systems have problems. They often only look at either the words or the pictures—not both together. They also usually need humans to label lots of examples, which takes time and money. Plus, when brands change their look, these models can get confused.
Another challenge is that brands can be global or local. Some brands are famous around the world, while others are only known in one country or city. Older systems often don’t do a good job at telling apart these different types of brands, especially if they’ve never seen them before.
In short, most past solutions are either too simple, too slow to update, or can’t handle the many ways that scammers try to copy brands. There was a clear need for something better—something that can look at all the clues in a message or website, learn on its own, and keep up with new tricks without needing humans to label everything.
This is where the new invention comes in. It uses modern machine learning in a fresh way. It looks at both the pictures and the text. It can spot both global and local brands. And it learns from large amounts of data, using smart clustering to group similar brand content together. It does not need people to label each example by hand. With this, it can build a brand registry that keeps getting better over time.
Invention Description and Key Innovations
Now, let’s dive into how this new system works, step by step, and see what makes it stand out.
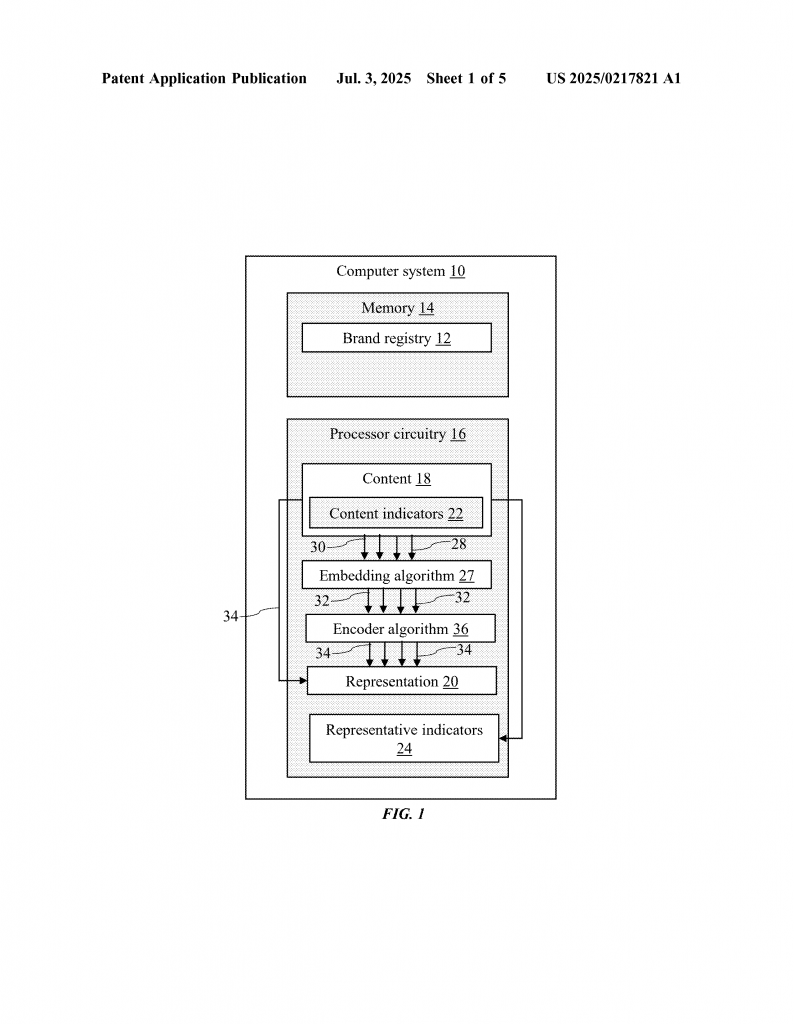
At the heart of the system is a computer with a memory and a processor. The memory stores four main things: a brand registry, an embedding machine learning algorithm, an encoder algorithm, and a risk model. The processor is like the brain—it runs all the steps needed to spot real and fake content.
The first thing the system does is make a smart “representation” of each piece of content it sees. This content could be an email, a webpage, or another type of digital message. To make sense of it, the processor pulls out “indicators.” These are clues found inside the content. Some indicators are visual, like an image, a logo, or a favicon (the small icon next to a website name). Others are textual, like the domain name, body text, or a copyright notice.
The processor splits these clues into two buckets: visual indicators and textual indicators. For each indicator, it uses a machine learning model to turn it into a vector. Think of a vector as a set of numbers that describes what the indicator looks like or means. For pictures, it uses a vision model (like a deep learning network that can “see” images). For text, it uses a natural language model (a tool that “reads” and understands words).
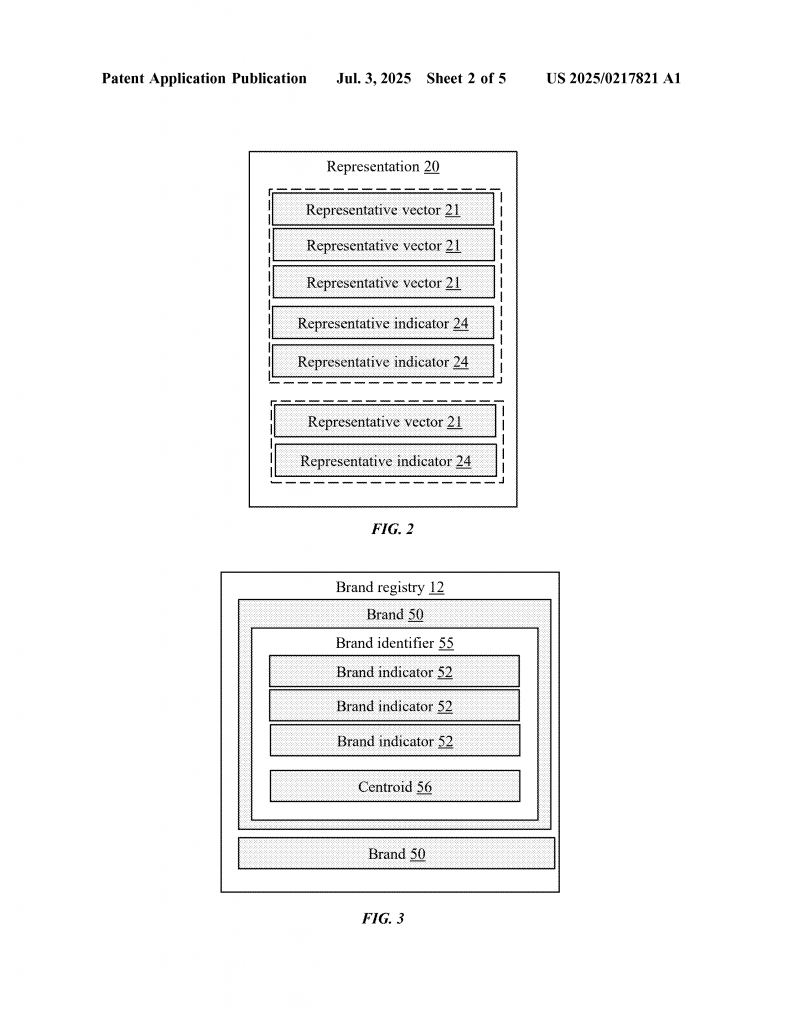
These vectors can be very big—sometimes hundreds of numbers long. To make things faster and easier to compare, the system uses an encoder. This encoder shrinks the vector down to a smaller size but tries to keep all the important details. This helps the system work quickly, even with lots of data.
Once all the brand content is turned into vectors, the system looks for clusters. A cluster is a group of similar vectors. Each cluster is treated as a single brand. This is a smart way to spot both famous brands and small local ones, just by how similar the clues are. The middle point of each cluster (called the centroid) is used as a brand’s “fingerprint.”
The system builds a brand registry out of all these clusters. Each entry in the registry has the brand’s fingerprint, its key indicators, and sometimes its name. The name can be pulled out by looking at the domain, the text, or the security certificate.
Now, when the system sees a new piece of content, it runs the same steps. It pulls out indicators, turns them into vectors, and finds the closest brand cluster in the registry. Next, it compares the clues from the new content to the real brand’s clues. For each matching clue (like the same domain or logo), it makes a note. If the clues match, the content is likely real. If they don’t, it could be fake.
To make the final decision, the system uses a risk model. This model is trained to look at both the matches and some “advanced features.” These features include details like the number of images, how many broken links there are, or if the page uses strange code. The risk model puts all this together and gives a risk score. If the score is high, the content is marked as fake. If the score is low, it’s marked as real.
If something is flagged as fake, the system can block it right away—so users can’t click on a bad link or enter their password on a fake site. If it’s real, the user can go on as usual.
There are several key things that make this invention stand out:
First, it uses both pictures and words to spot fakes, not just one or the other. Second, it learns on its own by finding clusters, so it doesn’t need people to label every sample. Third, it can spot both big brands and small local ones, thanks to its smart clustering. Fourth, it works fast and uses small vectors, so it can keep up even as new brands and fakes appear. Finally, it uses a risk model that looks at many clues, making it harder for scammers to sneak by.
This system can work in many places—on servers, laptops, or even as part of a network. It can be updated easily as new data comes in. Over time, it can help make the internet much safer for everyone, by keeping fake brands from tricking users.
Conclusion
Phishing and brand spoofing are big dangers on the internet today. Old tools can’t keep up with the clever tricks used by scammers. The new system we discussed builds a smart registry of real brands, using both the way things look and the words they use. It uses advanced machine learning to spot clusters, make fast decisions, and block fakes before they cause harm. By not needing human labels and by working with both global and local brands, it stands out from past solutions. This invention is a big step forward in keeping people safe online and protecting the trust we place in our favorite brands.
If your business or organization wants to protect its brand and customers, it’s time to look at solutions like this. As phishing gets smarter, so must our defenses. This technology is a powerful new tool in the fight to keep the internet safe for everyone.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217821.