Invented by Lourie; Heather, Peterson; Patrick M.


Modern businesses rely on customer service calls to keep customers happy and solve their problems. But when these calls get dropped by accident or end too soon, it can lead to unhappy customers and lost business. A new patent shows a smart way to spot these dropped calls, even without knowing what was said. In this article, we explain why this matters, how it works, and what makes this invention new and useful.
Background and Market Context
Customer service call centers are everywhere. Anytime someone calls a bank, a phone company, or an online store, they often talk to an automated system first. These systems, called interactive voice platforms (IVPs), try to help the caller or connect them to a human agent if needed. But sometimes, calls end too soon. Maybe the caller hangs up out of frustration, maybe there’s a technical problem, or maybe the system makes a mistake. These dropped calls can be a big problem for companies.
When a call drops, the customer’s problem is not solved. This can lead to unhappy customers who might leave bad reviews or switch to a competitor. Dropped calls also waste the time of agents and the company. For a business, every dropped call is a missed chance to help a customer, make a sale, or build loyalty.
Companies really want to know when and why calls drop. If they can spot these calls quickly, they can look for patterns, fix issues in their systems, and improve the customer experience. But there’s a challenge: call centers handle thousands of calls every day. It’s almost impossible for people to listen to every call and spot the ones that end badly.
Most automated solutions try to look for dropped calls by checking for certain keywords or looking at the content of the call. But this is hard, because people speak in many ways, and calls happen in different languages and cultures. Speech recognition is not always perfect, and it takes a lot of time and computer power to process every word.

What’s needed is a way to find dropped calls that does not depend on the actual words spoken. If a system can spot dropped calls just by looking at patterns—like who spoke when, how long someone was silent, or who hung up first—it can work faster, need less training, and be used in many countries without having to know every language. This is where the new patent steps in.
Scientific Rationale and Prior Art
To understand why this invention is important, let’s first look at how dropped calls are usually detected and why those ways have limits.
Traditional systems for finding dropped calls mostly use two kinds of information: what was said during the call (the content), and extra details about the call (metadata). Content-based systems use speech-to-text to turn spoken words into written text. Then, they look for certain words or phrases that might show the caller is frustrated or that the call is ending badly. These systems might also try to guess the caller’s mood (sentiment analysis) or follow the order of prompts in the call. But there are problems here. Speech recognition is not perfect—background noise, accents, or different languages make it even harder. Also, people express themselves in many ways, so a system trained in one language or country might not work well in another.
Another way is to look at the metadata. This includes things like the phone numbers involved, the time and duration of the call, who hung up first, and if any error codes were sent by the phone carrier. Some older systems use simple rules, like “if the call is shorter than one minute and ends from the customer’s side, it’s probably a dropped call.” But these rules are often too simple and miss many cases. Sometimes a customer might be helped in just thirty seconds, or an agent might accidentally hang up early.
Because of these problems, companies have tried using machine learning (ML). ML models can learn patterns from lots of examples and spot things that are hard for rule-based systems to catch. But most ML models still use content (the words spoken) as their main feature, so they run into the same problems as before: they need lots of training data in every language and can be confused by accents, background noise, or unusual phrasing.
Another issue with content-based ML is that dropped calls are rare. In a big data set of calls, only a small percent are truly dropped. This means you need a huge amount of labeled data to train the system well, and getting enough examples of dropped calls can be hard. It also means the system can be slow and expensive to set up, especially if it needs to be retrained for every new language or region.


Some companies have tried to use only metadata or simple timing patterns, but these systems are not very accurate. They often catch many false positives (calls that are not really dropped) or miss true dropped calls. There’s been a need for a system that can use patterns in the call—when people talk, how long they speak, gaps of silence, and who hangs up—without caring about the actual words. Such a system would be faster, cheaper, and easier to use across the world.
This is where the invention in the new patent comes in. It uses features from the call that are not tied to language or specific content. It looks at things like which channel (caller or agent) is speaking, the timing between utterances, the length of silences, and who ended the call. By turning each call into a “feature vector” based on these patterns, a machine learning model can learn to spot dropped calls with high accuracy. Then, only the suspected dropped calls need to be checked by a human analyst, saving tons of time and effort.
This approach is different from what’s been done before. It doesn’t need perfect transcripts, doesn’t care about what language is spoken, and doesn’t get tripped up by local accents or slang. It also works well even if there are only a small number of dropped calls in the training data. This is a big step forward for customer service analytics.
Invention Description and Key Innovations
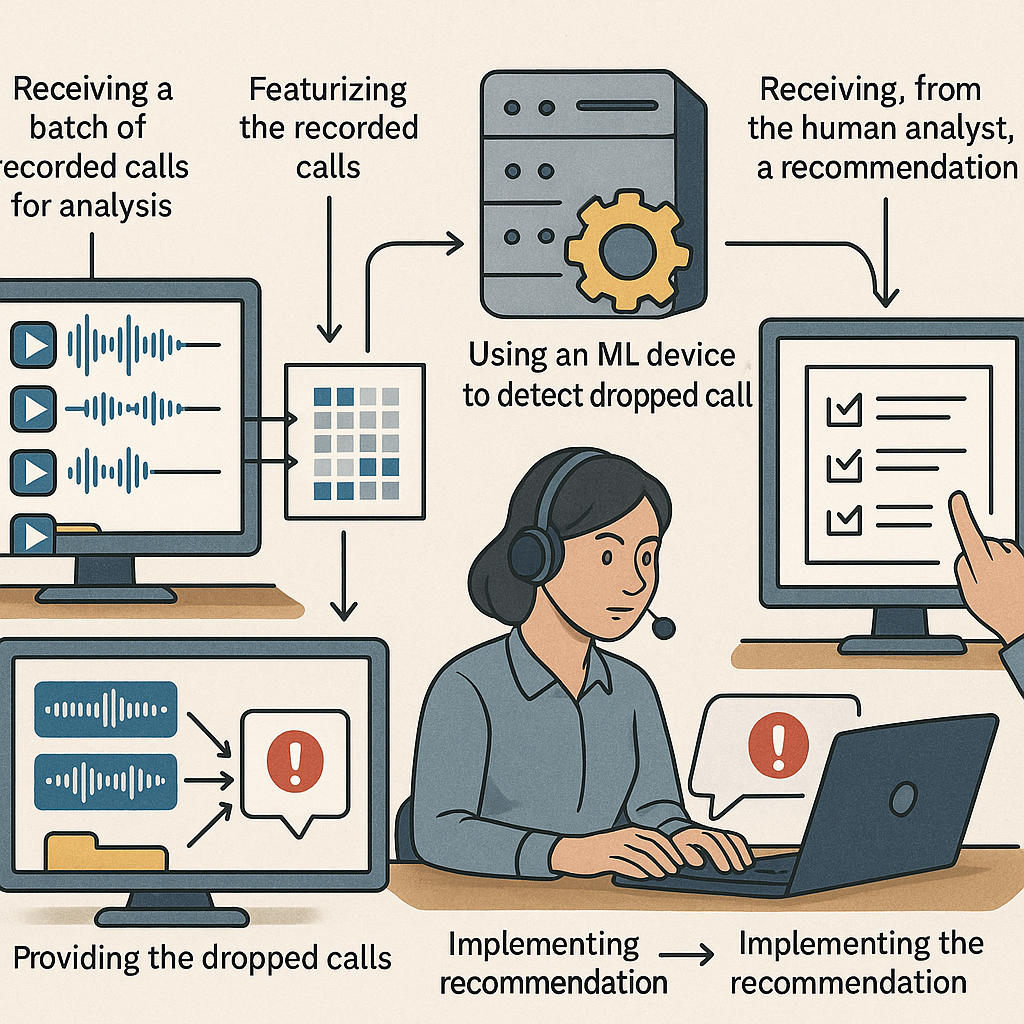
This new system is a smart way to spot dropped customer service calls without needing to know or understand what was actually said on the call. Here’s how it works, step by step:
First, a batch of call recordings is received. Each call has two kinds of data: the audio itself (what was heard) and metadata from the phone carrier (like who called, when, how long the call lasted, and who hung up). The system starts by dividing the audio into two channels—one for the caller, and one for the call center agent. This makes it clear who is speaking at any time.
Next, the audio is broken up into “utterances.” An utterance is a segment of speech, separated by periods of silence (for example, a pause of a few hundred milliseconds). This is done for each channel, so the system can tell when the caller talks and when the agent talks. Each utterance is then tagged as either speech or non-speech (like music, tones, or background noise).

For speech segments, the system may use speech-to-text, but only to help a human analyst later. The main smart part here is that the model doesn’t need the words—it just needs to know when someone spoke, for how long, and in what order. Sometimes, the system might tag a few special types of utterances, like an agent’s greeting, but this is just to help with timing and doesn’t require understanding the whole conversation.
With all this, the system creates a “feature vector” for each call. This is like a summary of the call based on timing and channel information, not on the words. Features might include:
- Which channel is speaking (caller or agent)
- Who ended the call (caller or agent)
- How long each utterance is
- Whether the segment is speech or not
- The time difference between the last utterance and the end of the call
- The time between turns (how long between caller and agent speaking)
- When the last agent utterance started and ended
The system can also use statistical analysis to remove features that are too closely related, making the model simpler and faster.
Once all calls are turned into feature vectors, the data is fed into a machine learning model. The model is trained on calls that are already labeled as “dropped” or “not dropped.” This helps the model learn what patterns usually show up when a call is dropped. For example, a dropped call might end with a long silence from the agent’s side, or the caller might hang up right after a certain prompt.
After training, the model can look at new calls and quickly spot which ones are likely to be dropped. It doesn’t care about the words or language—only the patterns. When a dropped call is found, it’s sent to a human analyst for review. The analyst can then make recommendations to improve the system, like fixing technical issues or changing prompts that cause confusion. The system can also be retrained with new data over time, making it smarter as more calls are processed.
This system can run in many ways. It can work in real time, analyzing calls as they happen, or it can look at batches of calls after the fact. It can be set up on regular servers, in virtual machines, or in containerized environments, making it easy to use in different technology setups.
The real innovation here is that the system is “content-independent.” It works anywhere, in any language, with any accent. It doesn’t need big language models or tons of data. It’s faster, cheaper, and easier to deploy. It also saves human analysts from listening to thousands of calls, letting them focus only on the ones that matter.
By focusing on the structure and flow of calls, not the words, this invention sets a new standard for call center analytics. It helps companies find and fix problems faster, leading to happier customers and better business results.
Conclusion
Dropped customer service calls are a silent killer for businesses, leading to wasted time, lost sales, and unhappy customers. Traditional ways to spot these calls rely too much on what is said, making them slow, expensive, and hard to use across languages and regions. The new content-independent system explained in this patent changes the game. It looks at the patterns of speech and silence, who talks when, and who hangs up, all without caring about the actual words.
This approach makes it possible to spot dropped calls quickly and accurately, no matter where in the world the call happens or what language is spoken. With this smart system, companies can improve their service, save money, and keep customers happy. As businesses continue to move toward more automated and global customer service, inventions like this will be key to staying ahead.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220114.